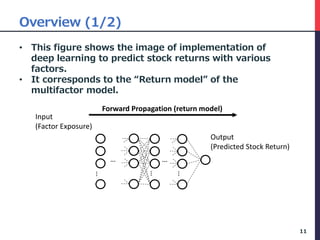
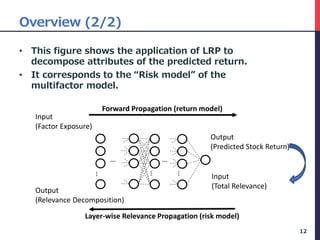
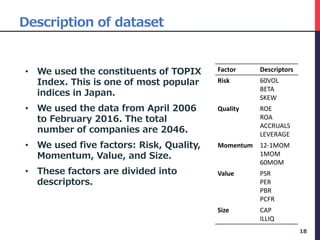
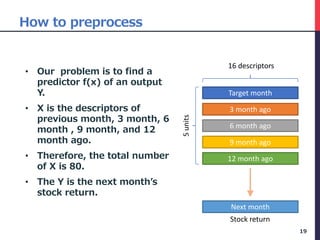
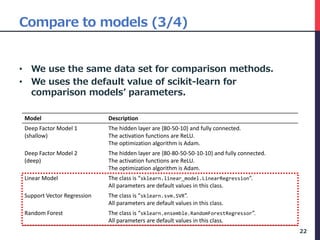
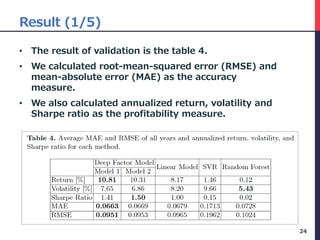
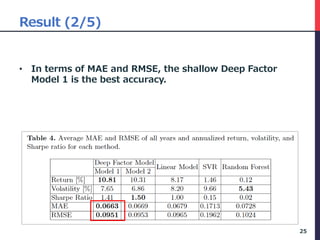
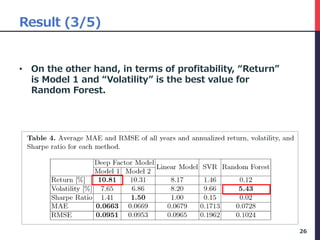
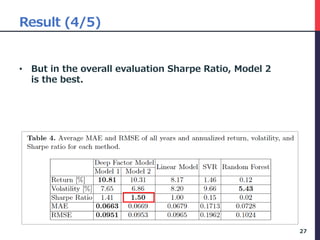
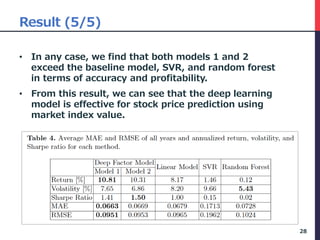
The document presents a deep factor model for forecasting stock returns using deep learning and layer-wise relevance propagation (LRP). It discusses the challenges in traditional forecasting methods and introduces a unified framework for predicting stock returns while ensuring model interpretability. The authors validate their model against various benchmarks, demonstrating its superior accuracy and profitability in stock price predictions.



















![Calculation process of LRP (1/5)
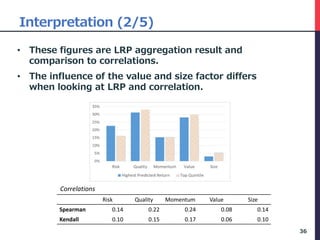
• There are 5 steps in this procedure.
• We use the data as of February 2016 to illustrate
the process.
• Step 1, we calculate LRP for each 80 variables.
30
this month … -12 month
Company_ID yyyymm Risk_60VOL Risk_BETA Quality_ROE … Value_EP Value_BR Value_PCFR
c0001 201602 0.110 0.837 0.822 … 0.021 0.067 0.001
c0002 201602 0.111 0.809 0.823 … 0.018 0.058 0.010
c0003 201602 0.108 0.785 0.799 … 0.020 0.066 0.001
… … … … … … … … …
[Step 1] Calculate LRP of each sample of only 201602(latest) yyyymm set](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-30-320.jpg)
![Calculation process of LRP (2/5)
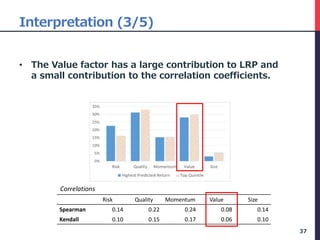
• In Step 2, We aggregate the descriptors to 5
factors.
31
[Step 2] Group Calculated LRP of each descriptor by 5 Factor.
this month … -12 month …
Company_ID yyyymm Risk_60VOL Risk_BETA Quality_ROE … Risk_60VOL Risk_BETA Quality_ROE …
c0001 201602 0.110 0.837 0.822 … 0.021 0.067 0.001 …
c0002 201602 0.111 0.809 0.823 … 0.018 0.058 0.010 …
c0003 201602 0.108 0.785 0.799 … 0.020 0.066 0.001 …
… … … … … … … … … …
sum of all month
Company_ID yyyymm Risk_* Quality_* Momentum_* Value_* Size_*
c0001 201602 1.318 8.366 2.091 0.418 0.209
c0002 201602 1.222 9.708 4.854 0.971 0.194
c0003 201602 1.400 7.068 2.356 0.471 0.094
… … … … … … …](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-31-320.jpg)
![Calculation process of LRP (3/5)
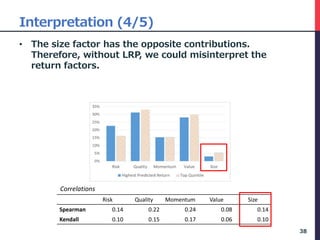
• Step 3, we convert this to a percentage.
• The result is the following table.
• This expresses the percentage that affected that
prediction.
32
[Step 3] Convert the summed LRP to percentage.
sum of all month
Company_ID yyyymm Risk_* Quality_* Momentum_* Value_* Size_*
c0001 201602 11% 67% 17% 3% 2%
c0002 201602 7% 57% 29% 6% 1%
c0003 201602 12% 62% 21% 4% 1%
… … … … … … …](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-32-320.jpg)
![Calculation process of LRP (4/5)
• Step 4, samples are sorted in descending order of
predicted return first.
• We will extract Highest predicted company and
company set of Top Quantile.
33
[Step 4] Sort descending order by predicted next month return.
sum of all month predicted
return of next
month
Company_I
D yyyymm Risk_* Quality_* Momentum_* Value_* Size_*
c0871 201602 0.076 0.652 0.227 0.030 0.015 0.87
c1981 201602 0.084 0.654 0.178 0.056 0.028 0.74
c0502 201602 0.215 0.570 0.127 0.051 0.038 0.71
c0070 201602 0.152 0.674 0.130 0.022 0.022 0.68
… … … … … … … …
c1788 201602 0.220 0.610 0.171 0.000 0.000 -0.92
c0834 201602 0.138 0.646 0.185 0.000 0.031 -0.94
c0043 201602 0.131 0.571 0.214 0.048 0.036 -1.05
Companies in top quantile](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-33-320.jpg)
![Calculation process of LRP (5/5)
• Step 5, we compare the two extracted data.
• Top quantile's company's factor score is average.
• By doing this, we can see which factor was affected
by the company that was expected to have a high
Return value.
34
[Step 5] Compaire between Highest predicted company VS Average of Top Quantile.
sum of all month
segment Risk_* Quality_* Momentum_* Value_* Size_*
Highest Company
(c0871)
0.23 0.31 0.15 0.28 0.03
Average of Top
Quantile
0.16 0.33 0.15 0.30 0.05](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-34-320.jpg)
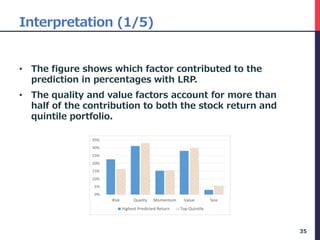
![Interpretation (5/5)
• In general, the momentum factor is not very
effective, but the value factor is effective in the
Japanese stock markets [Fama2012]
• On the other hand, there is a significant trend in
Japan to evaluate companies that will increase ROE
over the long term.
39](https://image.slidesharecdn.com/deepfactormodel-181001043151/85/Deep-Factor-Model-39-320.jpg)



































![Mini Project Final Presentation Template [Autosaved].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/miniprojectfinalpresentationtemplateautosaved-251206074050-2337e704-thumbnail.jpg?width=640&height=640&fit=bounds)


































