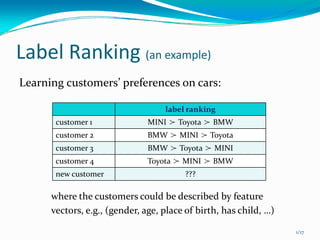
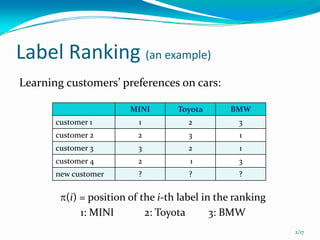
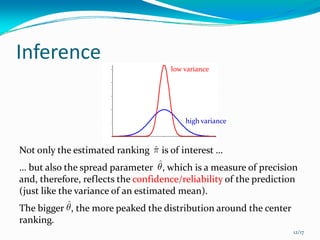
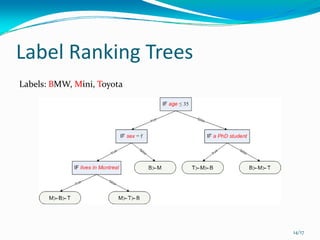
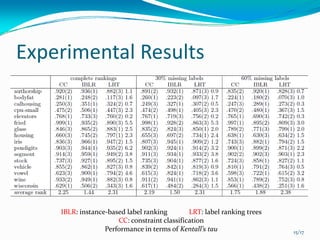
This document presents a local approach to label ranking using a probabilistic model. It describes an instance-based method for learning customers' preferences on cars from labeled training data consisting of customers' rankings of different car labels. The method models the distribution of rankings as locally constant, estimating the distribution from nearby preferences using maximum likelihood. It can handle both complete and incomplete rankings through an approximation of the EM algorithm. Experimental results show the local method can better exploit preference information than model-based approaches like constraint classification.