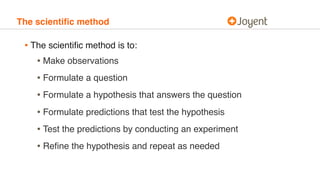
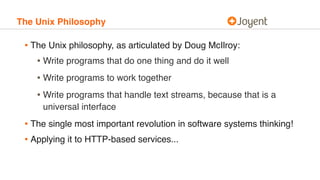
This document discusses debugging microservices in production environments. It begins by providing context on the history of debugging and introduces some common anti-patterns in debugging. It then argues that debugging should be approached methodically using the scientific method. The document outlines a method for debugging software called the software debugging method. Finally, it discusses challenges that arise in debugging microservices due to their distributed nature and argues that containers can help address these challenges.
























































































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









