Download to read offline












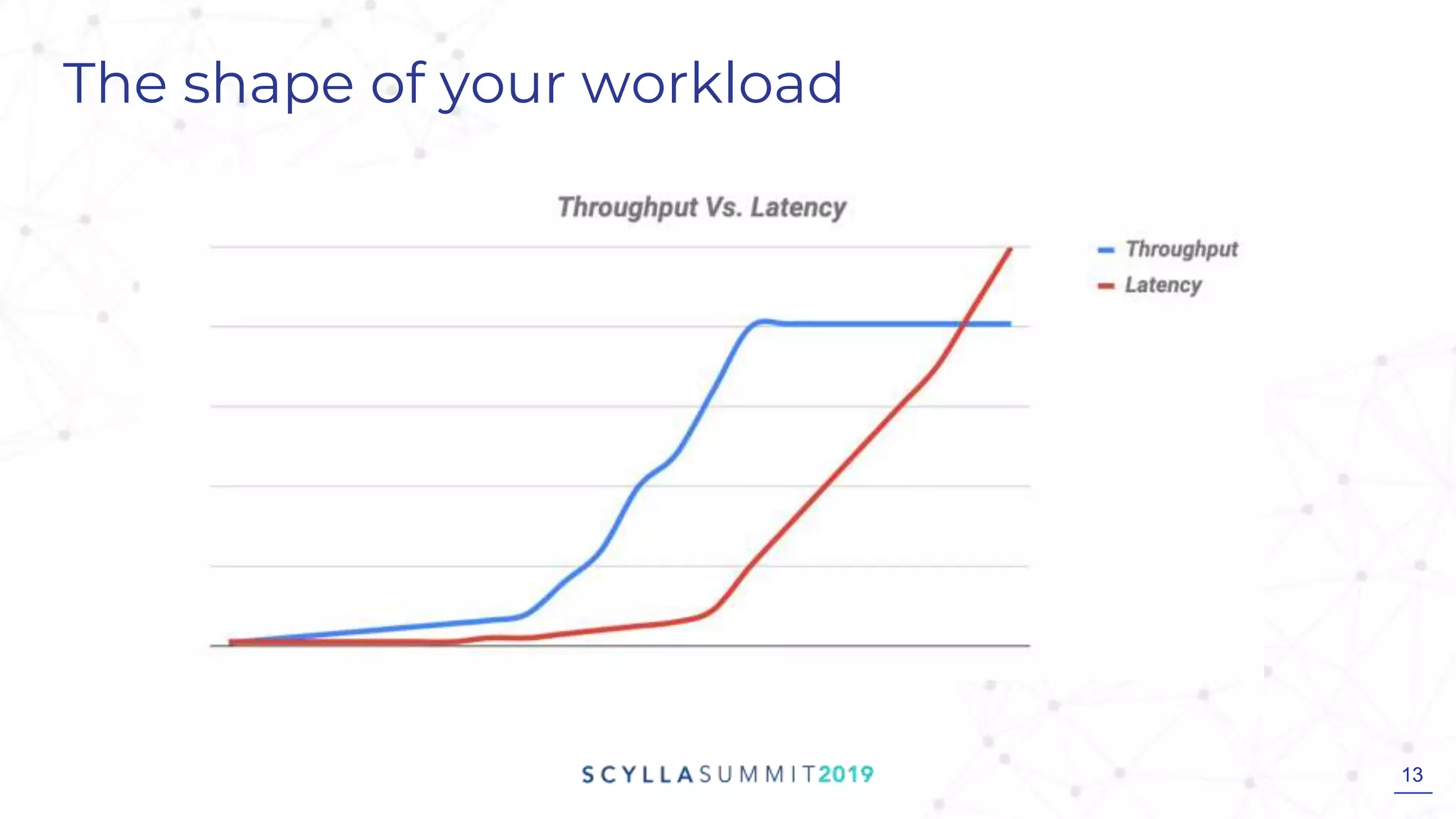
















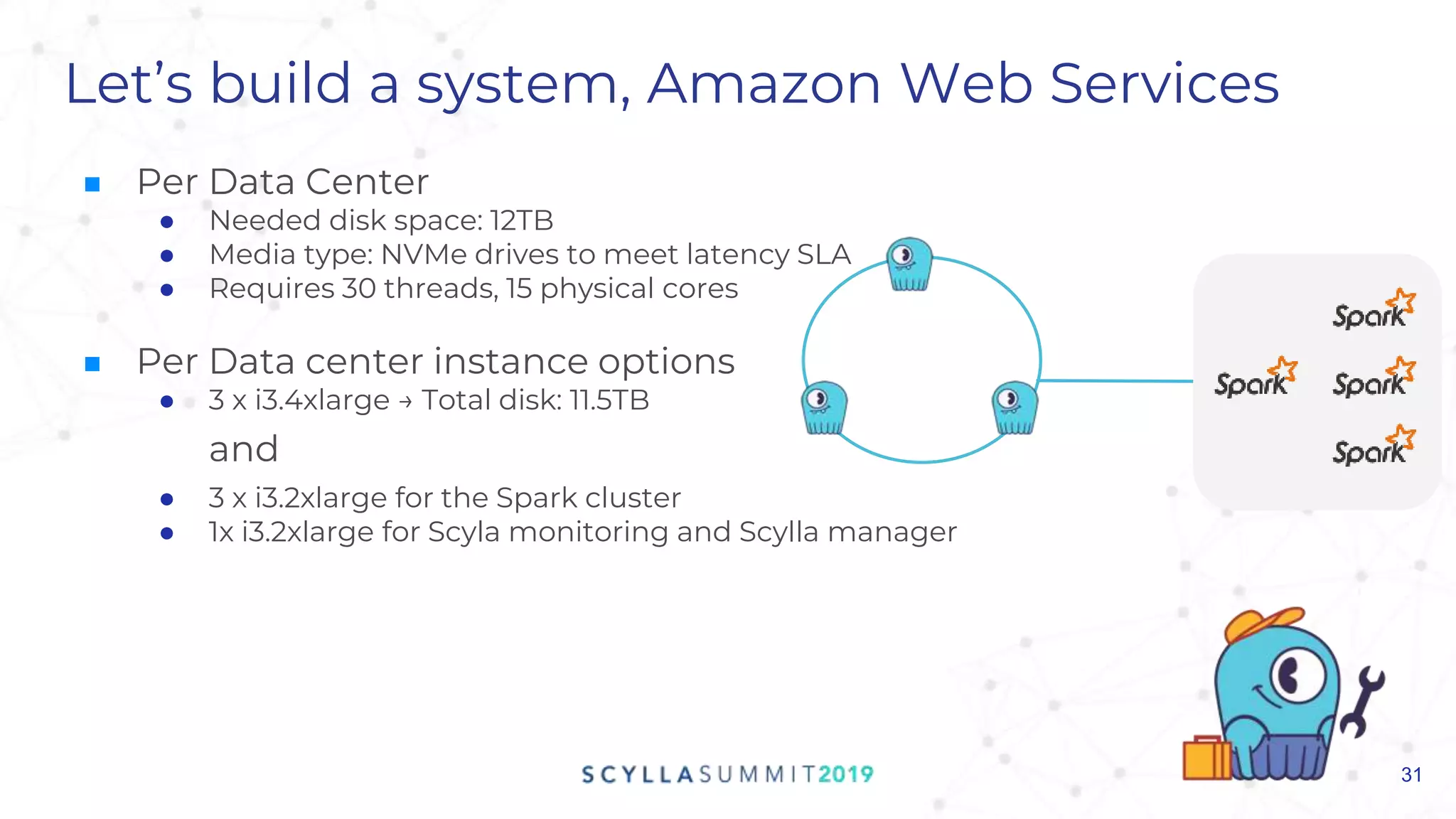










This document discusses ScyllaDB's process for sizing a Scylla cluster. It begins by outlining the importance of understanding business, application, and infrastructure requirements. Then it walks through building a sample system based on provided workload details. It shows how the sample system could be configured on different cloud platforms like AWS, Azure, and GCP. Finally, it highlights Scylla's sizing sheet tool for helping to determine hardware needs based on workload characteristics and performance goals.






















































































