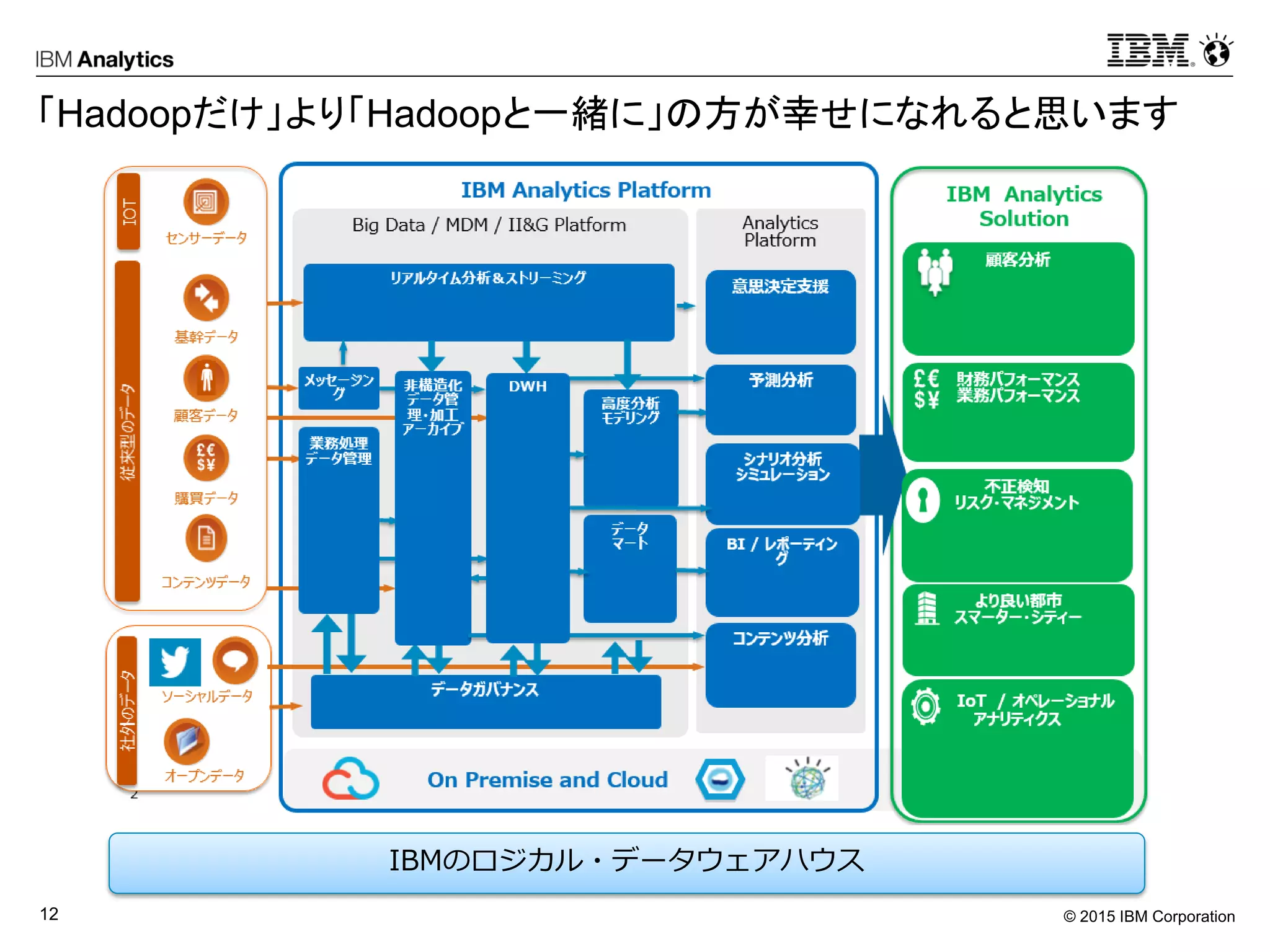
データベースに蓄積されたデータを使って、「過去」と「現在(いま)」の状況を把握できるのは当たり前。これからのデータベースに必要なのは、「未来」を「予測」すること。 そんなことできるの?どうやって?という疑問にお答えします。また、これからのデータ活用には、データの「場所」を意識せずに済むことが重要です。クラウド、オンプレミス、RDB、NoSQL、Hadoop、あちこちに分散したデータを透過的に活用できる、「ロジカルデータウェアハウス」について解説します。















![© 2015 IBM Corporation28
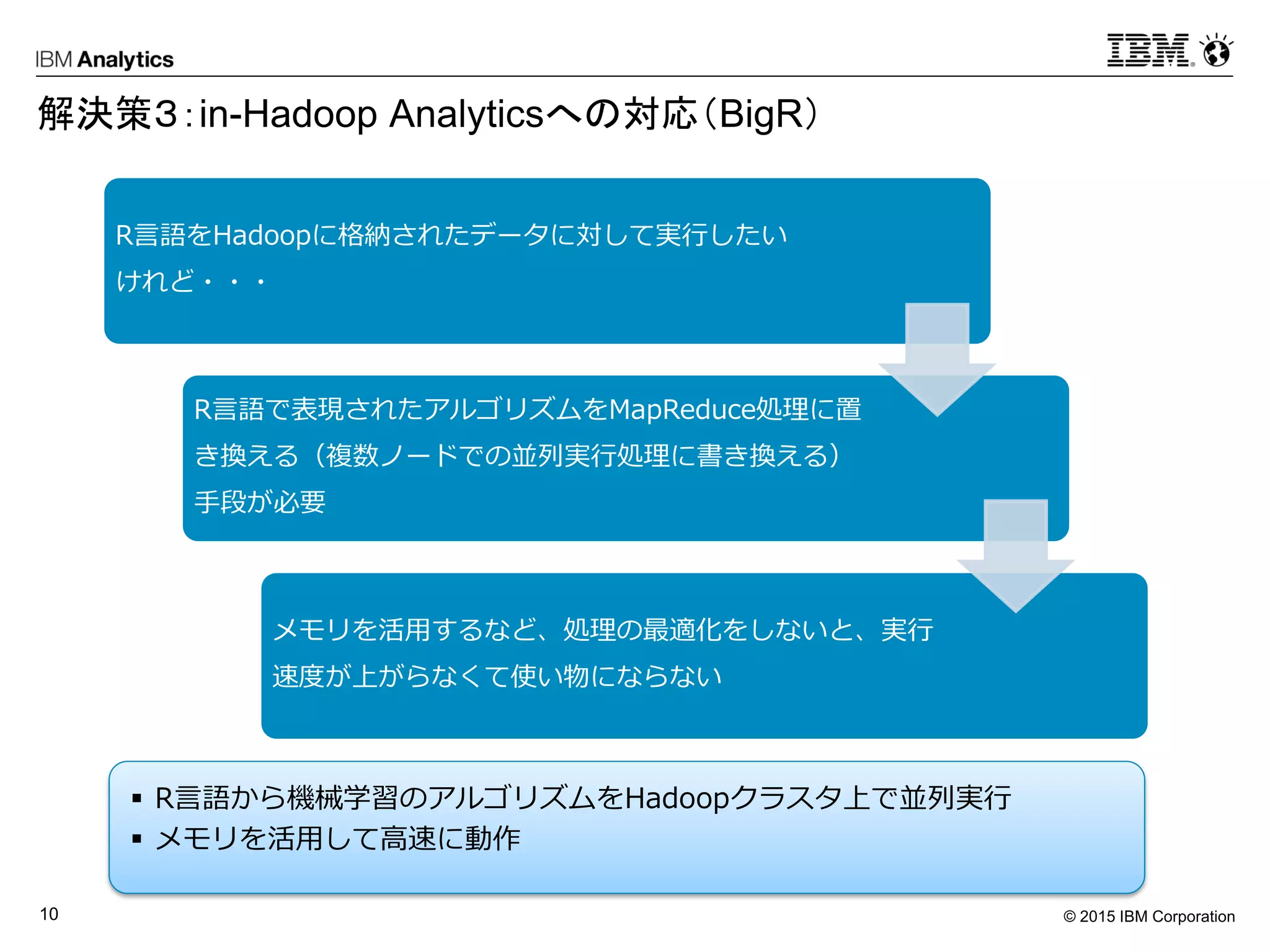
Sample Code – BigR
Code using Big R
library(bigr)
temperatureData <- bigr.frame(dataSource="DEL",
dataPath="/user/temperature.csv", header=TRUE)
coltypes(temperatureData)=ifelse(1:10 %in% c(3, 6),
"numeric", "character")
buildAvgTempFunc <- function(df) {
maxMin <- df[ , c(‘minTemp’, ‘maxTemp’)]
df$avgTempDay <- rowMeans(maxMin)
avgTempCity <- aggregate (df$avgTempDay,
by=list(city=df$city), FUN=mean)
return(data.frame(avgTempCity))
}
avgTemperature <- groupApply(temperatureData,
temperatureData$city, buildAvgTempFunc,
data.frame(city=“city", average_temperature=1.0))
bigr.persist(avgTemperature, dataSource="DEL",
dataPath="/user/output.csv", header=T, del=',')
This code (using Big R) achieves the same as the original R code on the same dataset in the csv file in HDFS.
Note that the function call buildAvgTempFunc has same R code snippet as in original R code.
The groupApply function is specific to bigr package. Other similar useful functions are rowApply and tableApply
Original R Code
tempData <- read.table(“temperature.csv", header =
TRUE, sep=“,’)
coltypes(tempData) = ifelse(1:10 %in% c(3, 4), numeric,
character)
maxMin <- tempData[ , c(‘minTemp’, ‘maxTemp’)]
tempData$avgTempDay <- rowMeans(maxMin)
avgTempCity <- aggregate (tempData$avgTempDay,
by=list(city=tempData$city), FUN=mean)
write(avgTempCity, file = “output.csv", sep = “, “)](https://image.slidesharecdn.com/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891/75/db-tech-showcase-Tokyo-2015-B34-IBM-by-28-2048.jpg)



![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e27neo4jcreationline-150623051314-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] C25: 世界最速のAnalytic DBがHadoopとタッグを組んだ! ~スケールアウト検...](https://cdn.slidesharecdn.com/ss_thumbnails/c25-170913052337-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b24nonstop-sqlhp-150619075240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017e34-170911070313-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...](https://cdn.slidesharecdn.com/ss_thumbnails/d21-170912022444-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d35infoframe-relational-storenec-150616022508-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b15postgresqlntt-oss-center-150619073139-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] A32: Attunity Replicate + Kafka + Hadoop マルチデータ...](https://cdn.slidesharecdn.com/ss_thumbnails/attunityreplicatekafkahadoop-170911072451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...](https://cdn.slidesharecdn.com/ss_thumbnails/b26-170912020934-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D22:インメモリープラットホームSAP HANAのご紹介と最新情報 by SAPジャパン株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d22sap-hanasap-japan-150618080756-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A26:内部犯行による漏えいを防ぐPostgreSQLの透過的暗号化機能に関する実装と利用方法...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a26postgresqlnec-150616021014-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E15:Hadoop大量データ処理技術と日立匿名化技術によるプライバシー保護とデータ活用 by...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e15hadoophitachi-solutions-150721062250-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c32kvshitachi-150619110419-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C33:ビッグデータ・IoT時代のキーテクノロジー、CEPの「今」を掴む! by 株式会社日立...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c33bigdatahitachi-150619110610-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c15mysqlkakaku-150618053752-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] C25:HP NonStop SQLはなぜグローバルに分散DBを構築できるのか、 データの整合...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c25nonstop-sqlhp-150619092435-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...](https://cdn.slidesharecdn.com/ss_thumbnails/b37dbtechshowcasetokyo2015haclusteringsoftware20150612-150611165311-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d23mysqloracle-mysqlgbu-150619101210-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D33:Superdome X 上の SQL Server 2014 OLTP 検証結果と S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d33sql-servermicrosoft-150619092854-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b27sap-hanasap-japan-150618080033-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a33amazon-dynamodbamazondataservicejapan-150623010315-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?](https://cdn.slidesharecdn.com/ss_thumbnails/a27nosqlforrdbengineer-150624020431-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] E24: 流行りに乗っていれば幸せになれますか?数あるデータベースの中から敢えて今Db2が選ば...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017db2ibm-171006012214-thumbnail.jpg?width=640&height=640&fit=bounds)











![[db analytics showcase Sapporo 2017] B27:世界最速のAnalytic DBはHadoopの夢を見るか by 株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/dbas20170701-170707082516-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2018] #dbts2018 #A22 『最高のデータプラットフォームを、最短でつくる方法』](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018a22ibm-180929170611-thumbnail.jpg?width=640&height=640&fit=bounds)












![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)















