Hitachi Advanced Data Binderで実際の現場で行っているSQLチューニング方法をご紹介します。稼働情報を取得・解析して問題点を見つけ、SQLチューニングを行う一連の流れを実例ベースでご紹介します。








![© Hitachi, Ltd. 2015. All rights reserved.
タイムスタンプ AP_name SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
2015/06/01 06:35:12 adbsql 1 SELECT 266,948 1 ADBDIC ##ADBOTHER#0000004096 8 100 0 0
2015/06/01 06:35:12 adbsql 1 SELECT ADBUIDX01 ADBUIDX01BUF 120,202 100 0 0
2015/06/01 06:35:25 adbsql 2 SELECT 112,899 1 ADBDIC ##ADBOTHER#0000004096 8 100 0 0
2015/06/01 06:35:25 adbsql 2 SELECT ADBUTBL01 ADBUTBL01BUF 75 100 0 0
2015/06/01 06:37:55 adbsql 3 SELECT 23,822,936 1 ADBDIC ##ADBOTHER#0000004096 16 100 0 0
2015/06/01 06:37:55 adbsql 3 SELECT ADBUIDX01 ADBUIDX01BUF 14,760,202 100 0 0
2015/06/01 06:37:55 adbsql 3 SELECT ADBUTBL01 ADBUTBL01BUF 14,520,000 100 0 0
12
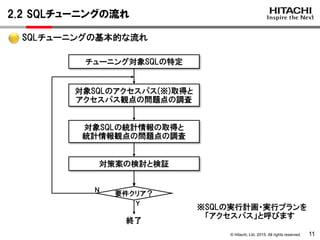
チューニング対象SQLの特定
⇒SQL処理時間を調査し、画面レスポンスとSQL処理時間を比較して、
レスポンスに影響しているSQLを特定します
2.2 SQLチューニングの流れ
<ポイント>
1つのSQLが原因のケースや、複数のSQLで少しずつ時間がかかるケースもあります。
<SQL処理時間の取得方法>
HADBの統計解析コマンド(adbstat)でSQL文の統計情報を取得します
HADBサーバ
データベースadbstat -c sql
-m '開始時刻','終了時刻'
> log_adbstat_sql.csv
DB管理者
・・・
・・・
・・・
・・・
・・・
・・・
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-13-320.jpg)
![© Hitachi, Ltd. 2015. All rights reserved. 14
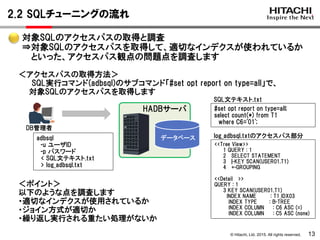
対象SQLの統計情報の取得と調査
⇒対象SQLの統計情報を取得して、バッファへのアクセス要求回数や
I/O回数といった、統計情報観点の問題点を調査します
2.2 SQLチューニングの流れ
<ポイント>
以下のような点を調査します
・想定するDBへのアクセス量と比べて、バッファアクセス回数が多くないか
・バッファヒット率が著しく低くないか(I/O回数が極端に多くなっていないか)
<統計情報の取得方法(SQL処理時間の取得と同じ)>
HADBの統計解析コマンド(adbstat)でSQL文の統計情報を取得します
タイムスタンプ AP_name SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
2015/06/01 06:40:29 adbsql 4 SELECT 266,948 1 ADBDIC ##ADBOTHER#0000004096 8 100 0 0
2015/06/01 06:40:29 adbsql 4 SELECT ADBUIDX01 ADBUIDX01BUF 120,202 100 0 0
2015/06/01 06:41:07 adbsql 5 SELECT 112,899 1 ADBDIC ##ADBOTHER#0000004096 8 100 0 0
2015/06/01 06:41:07 adbsql 5 SELECT ADBUTBL01 ADBUTBL01BUF 75 100 0 0
2015/06/01 06:42:31 adbsql 6 SELECT 23,822,936 1 ADBDIC ##ADBOTHER#0000004096 16 100 0 0
2015/06/01 06:42:31 adbsql 6 SELECT ADBUIDX01 ADBUIDX01BUF 14,760,202 100 0 0
2015/06/01 06:42:31 adbsql 6 SELECT ADBUTBL01 ADBUTBL01BUF 14,520,000 100 0 0
HADBサーバ
データベースadbstat -c sql
-m '開始時刻','終了時刻'
> log_adbstat_sql.csv
DB管理者
・・・
・・・
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-15-320.jpg)



![© Hitachi, Ltd. 2015. All rights reserved.
3.1 事例1 -グループ化処理のタイミングー
18
<ポイント1>
検索の対象行数がどのくらいあるか、ざっくりと求めて、統計情報の
DBアクセス量(バッファ要求回数)と比べてみましょう。
SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
1 SELECT 20,398,931 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
1 SELECT ADBUIDX01 ADBUIDX01BUF 16,450,491 100 0 0
1 SELECT ADBUTBL01 ADBUTBL01BUF 8,219,200 100 0 0
2 SELECT 7,355,184 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
2 SELECT ADBUIDX01 ADBUIDX01BUF 4,241,679 100 0 0
2 SELECT ADBUTBL01 ADBUTBL01BUF 4,149,596 100 0 0
4月分の売上データは410万件あります。
それに対して、統計情報のインデクス要求回数は1645万回。約4倍です。
→ネストジョインの内側である商品TBLを検索する際、インデクス段数が
3段として、売上データ1件当たり商品TBLのインデクスを3回参照。
売上データ001
売上データ002
売上データ003
・・・
売上TBL
商品001
商品002
商品003
・・・
410万件+410万件×3段≒1600万回
売上TBL 商品TBL
商品TBL
商品INDEX
(3段)
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-19-320.jpg)
![© Hitachi, Ltd. 2015. All rights reserved.
3.1 事例1 -グループ化処理のタイミングー
19
<改善策>
集計前の売上データには商品コードが重複するので、集計後に商品TBLを
ジョインするように変更します(グループ化処理を先に実施)
SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
1 SELECT 20,398,931 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
1 SELECT ADBUIDX01 ADBUIDX01BUF 16,450,491 100 0 0
1 SELECT ADBUTBL01 ADBUTBL01BUF 8,219,200 100 0 0
2 SELECT 7,355,184 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
2 SELECT ADBUIDX01 ADBUIDX01BUF 4,241,679 100 0 0
2 SELECT ADBUTBL01 ADBUTBL01BUF 4,149,596 100 0 0
本改善でインデクスへの要求回数が1645万回→424万回に削減できました。
→ 4月分の売上データは410万件で、集計結果は4万件になるため、
410万件+4万件×3段=420万回
売上TBL 商品TBL
select U.大分類, U.商品コード, U.金額, S.商品名
from (select 大分類, 商品コード, SUM(金額)
from 売上TBL
where 日付 between '2014/04/01' and '2014/04/30'
and 大分類 in ('01', '02', '03', '04')
group by 大分類, 商品コード
) U
left join 商品TBL S
on U.大分類=S.大分類 and U.商品コード=S.商品コード
書換えたSQL
の統計情報
・・・
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-20-320.jpg)
![© Hitachi, Ltd. 2015. All rights reserved.
SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
1 SELECT 20,398,931 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
1 SELECT ADBUIDX01 ADBUIDX01BUF 16,450,491 100 0 0
1 SELECT ADBUTBL01 ADBUTBL01BUF 8,219,200 100 0 0
2 SELECT 8,823,041 39,996 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
2 SELECT ADBUIDX01 ADBUIDX01BUF 4,332,134 100 0 0
2 SELECT ADBUTBL01 ADBUTBL01BUF 4,149,596 100 0 0
3.2 事例2 -ジョインの順序ー
20
<ポイント2>
事例1の改善策として、ジョイン順序を変更する方法もあります。
事例1は売上TBLを起点にしていましたが、商品TBLの方が件数が少ない
ため、商品TBLを起点としたジョインに変更します。
本改善でインデクスへの要求回数が1645万回→433万回に削減できました。
→ 4月分の売上データは、商品コード当たり平均103件あるため、
4万件 + 4万件×(103件+4段)=432万回
商品TBL 売上TBL
select U.大分類, U.商品コード, U.金額, S.商品名
from 商品TBL S
INNER JOIN 売上TBL U
on U.大分類=S.大分類 and U.商品コード=S.商品コード
where U.日付 between '2014/04/01' and '2014/04/30'
and S.大分類 in ('01', '02', '03', '04')
group by U.大分類, U.商品コード
書換えたSQL
の統計情報
・・・
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-21-320.jpg)

![© Hitachi, Ltd. 2015. All rights reserved. 24
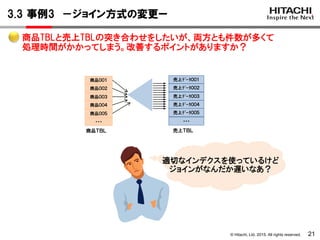
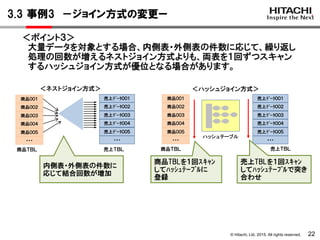
<ポイント4>
演算を含むIN(副問合せ)はインデクスで評価できずに、思わぬ処理時間
がかかってしまうことがあります。
SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
1 SELECT 58,134,960 400 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
1 SELECT ADBWRK ADBWRK 54,657,604 100 0 0
1 SELECT ADBUIDX01 ADBUIDX01BUF 137,394 100 0 0
1 SELECT ADBUTBL01 ADBUTBL01BUF 137,185 100 1 0
2 SELECT 1,417,099 400 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
2 SELECT ADBUIDX01 ADBUIDX01BUF 548,355 100 0 0
2 SELECT ADBUTBL01 ADBUTBL01BUF 273,974 100 0 0
演算を含むIN(副問合せ)は、副問合せの結果を作業表に格納して、
主問合せの1件ごとに、作業表と突き合わせて評価します。
→副問合せ結果(あるメーカの商品数)は400件あり、4/1の売上データは
136000件あります。
→400件×136000件=5400万回の突き合わせが行われます。
統計情報からも、作業表のバッファに5465万回の要求回数をだしており、
この突き合わせに時間がかかっていることがわかります。
3.4 事例4 -演算を含むIN(副問合せ)の書換えー
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-25-320.jpg)
![© Hitachi, Ltd. 2015. All rights reserved. 25
<改善策>
演算を含むIN(副問合せ)は、外への参照を使ったEXISTS述語で書き換えると
効率的に検索できるケースが多いです。
select 大分類 , 商品コード , SUM(金額)
from 売上TBL U
where 日付 = '2014/04/01'
and EXISTS(
select * from 商品TBL
where メーカーコード='000456'
and 大分類=U.大分類 and 商品コード=U.商品コード
)
group by 大分類 , 商品コード
SQL# SQL_type SQL時間[μ秒] フェッチ行数 DBエリア名 バッファ名 要求回数 バッファヒット率 read回数 write回数
1 SELECT 58,134,960 400 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
1 SELECT ADBWRK ADBWRK 54,657,604 100 0 0
1 SELECT ADBUIDX01 ADBUIDX01BUF 137,394 100 0 0
1 SELECT ADBUTBL01 ADBUTBL01BUF 137,185 100 1 0
2 SELECT 1,417,099 400 ADBDIC ##ADBOTHER#0000004096 14 100 0 0
2 SELECT ADBUIDX01 ADBUIDX01BUF 548,355 100 0 0
2 SELECT ADBUTBL01 ADBUTBL01BUF 273,974 100 0 0
書換えたSQL
の統計情報
本改善で、作業表(ADBWRK)へのアクセスそのものがなくなり、5467万回
の突き合わせ処理が削減できました。その分は、外への参照の部分で
インデクスへのアクセスが増加する形になります。
3.4 事例4 -演算を含むIN(副問合せ)の書換えー
・・・
・・・](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-26-320.jpg)




![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 by 株式会社日立製作所 情報・通信システム社 山口健一](https://image.slidesharecdn.com/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892/85/db-tech-showcase-Tokyo-2015-B36-Hitachi-Advanced-Data-Binder-SQL-by-32-320.jpg)

![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b24nonstop-sqlhp-150619075240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d35infoframe-relational-storenec-150616022508-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e27neo4jcreationline-150623051314-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D33:Superdome X 上の SQL Server 2014 OLTP 検証結果と S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d33sql-servermicrosoft-150619092854-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C25:HP NonStop SQLはなぜグローバルに分散DBを構築できるのか、 データの整合...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c25nonstop-sqlhp-150619092435-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b17postgresqlsraoss-150616021919-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] A12:DBAが知っておくべき最新テクノロジー: フラッシュ, ストレージ, クラウド b...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a12oraclesqlserverinsighttechnology-150918013852-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b15postgresqlntt-oss-center-150619073139-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A26:内部犯行による漏えいを防ぐPostgreSQLの透過的暗号化機能に関する実装と利用方法...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a26postgresqlnec-150616021014-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] E24: 流行りに乗っていれば幸せになれますか?数あるデータベースの中から敢えて今Db2が選ば...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017db2ibm-171006012214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] A25: ACIDトランザクションをサポートするエンタープライズ向けNoSQL Databas...](https://cdn.slidesharecdn.com/ss_thumbnails/0srcpmelq3u9j2hc5dv9-signature-2f56a4964d89a71ef0ade271d7aebd1fb48e0c6f2d10a84704e4a42846607f3d-poli-160721034720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] C25: 世界最速のAnalytic DBがHadoopとタッグを組んだ! ~スケールアウト検...](https://cdn.slidesharecdn.com/ss_thumbnails/c25-170913052337-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] D15: データベース フラッシュソリューション徹底解説! 安価にデータベースを高速にする方法...](https://cdn.slidesharecdn.com/ss_thumbnails/8dzgn4hircgyxu7agvvv-signature-e2d161bac10db4b1f2edfe0e3785064ea4537096d62ef03035d3e3fcb7faeb03-poli-160815015129-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D25:The difference between logical and physical...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d25oracledbvisit-software-150619090737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C14:30万のユーザ部門を抱える日立、情シスの「理想と現実」 by 株式会社日立製作所 情報...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c14it-infrastructurehitachi-150619110309-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C16:Oracle Disaster Recovery at New Zealand sto...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c16oracledbvisit-softwareinsight-technology-150619090553-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C33:ビッグデータ・IoT時代のキーテクノロジー、CEPの「今」を掴む! by 株式会社日立...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c33bigdatahitachi-150619110610-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c27mysqlrakuten-150617022225-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?](https://cdn.slidesharecdn.com/ss_thumbnails/a27nosqlforrdbengineer-150624020431-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c15mysqlkakaku-150618053752-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E15:Hadoop大量データ処理技術と日立匿名化技術によるプライバシー保護とデータ活用 by...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e15hadoophitachi-solutions-150721062250-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D22:インメモリープラットホームSAP HANAのご紹介と最新情報 by SAPジャパン株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d22sap-hanasap-japan-150618080756-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a32amazon-redshiftamazondataservicejapan-150623010123-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B16:最新版PostgreSQLのパフォーマンスを引き出すためのポイント by Postgr...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b16postgresqlpgecons-150616021257-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a33amazon-dynamodbamazondataservicejapan-150623010315-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





































![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)