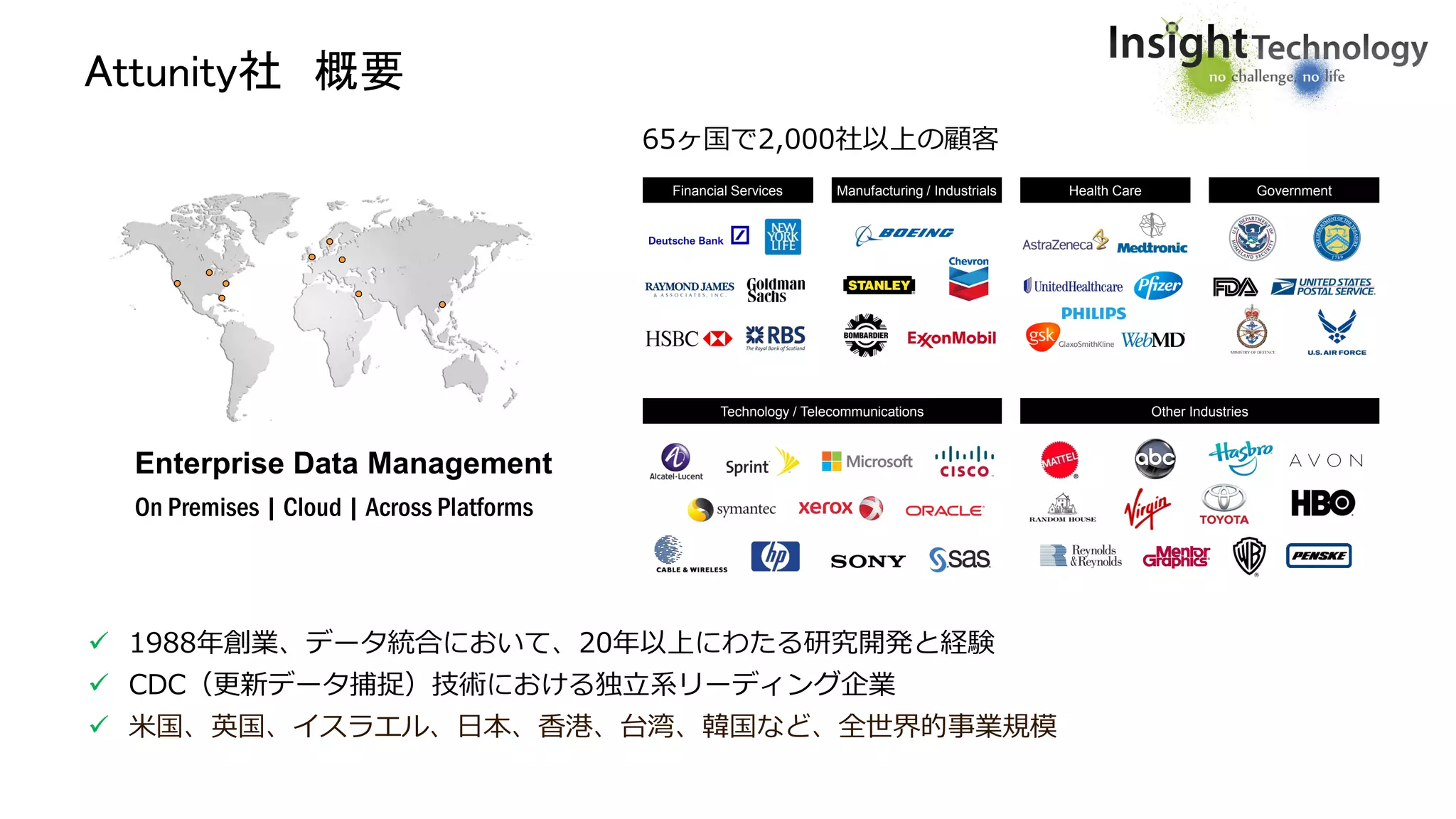
Financial Services Manufacturing/ Industrials GovernmentHealth Care
Technology / Telecommunications Other Industries
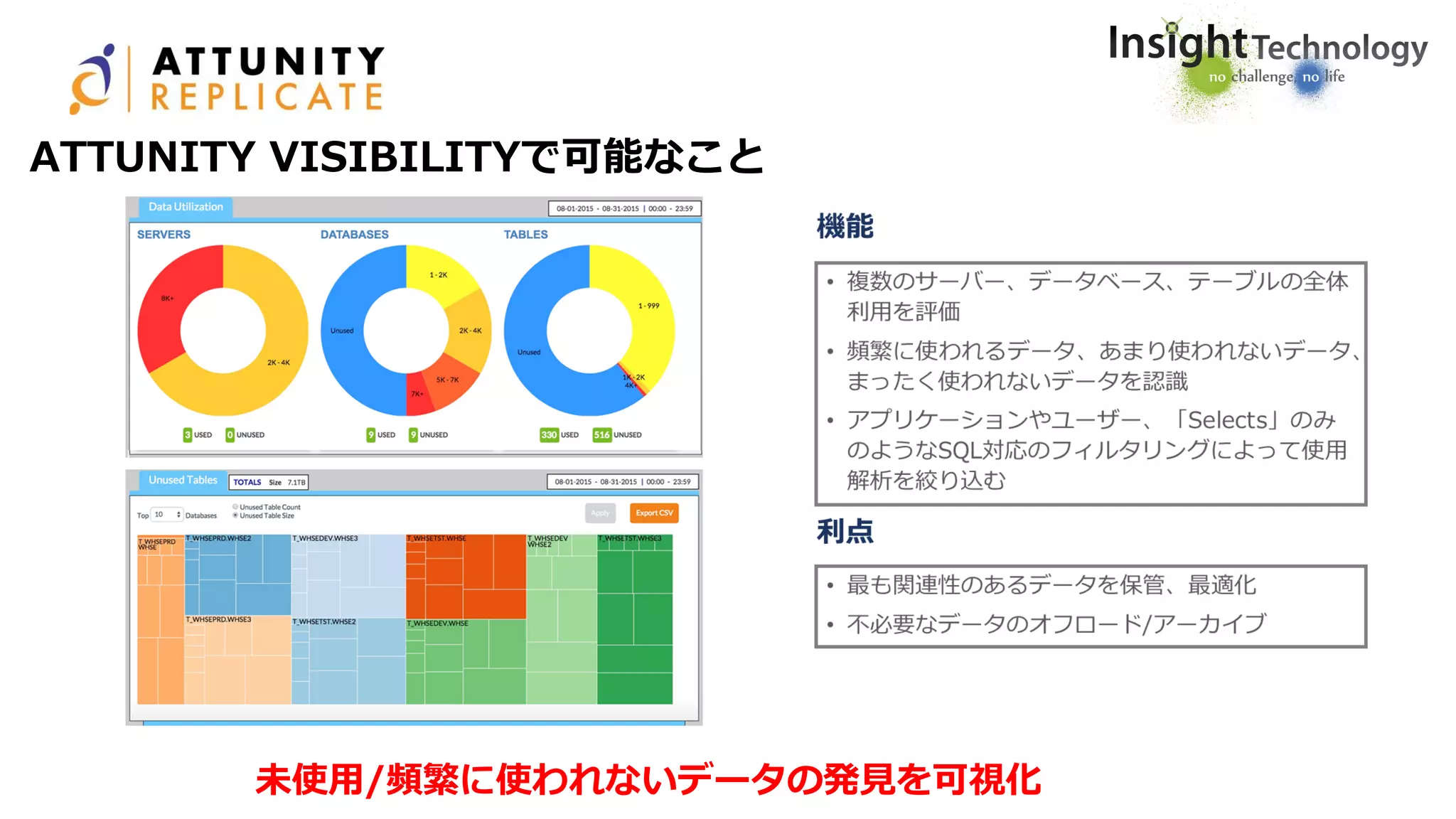
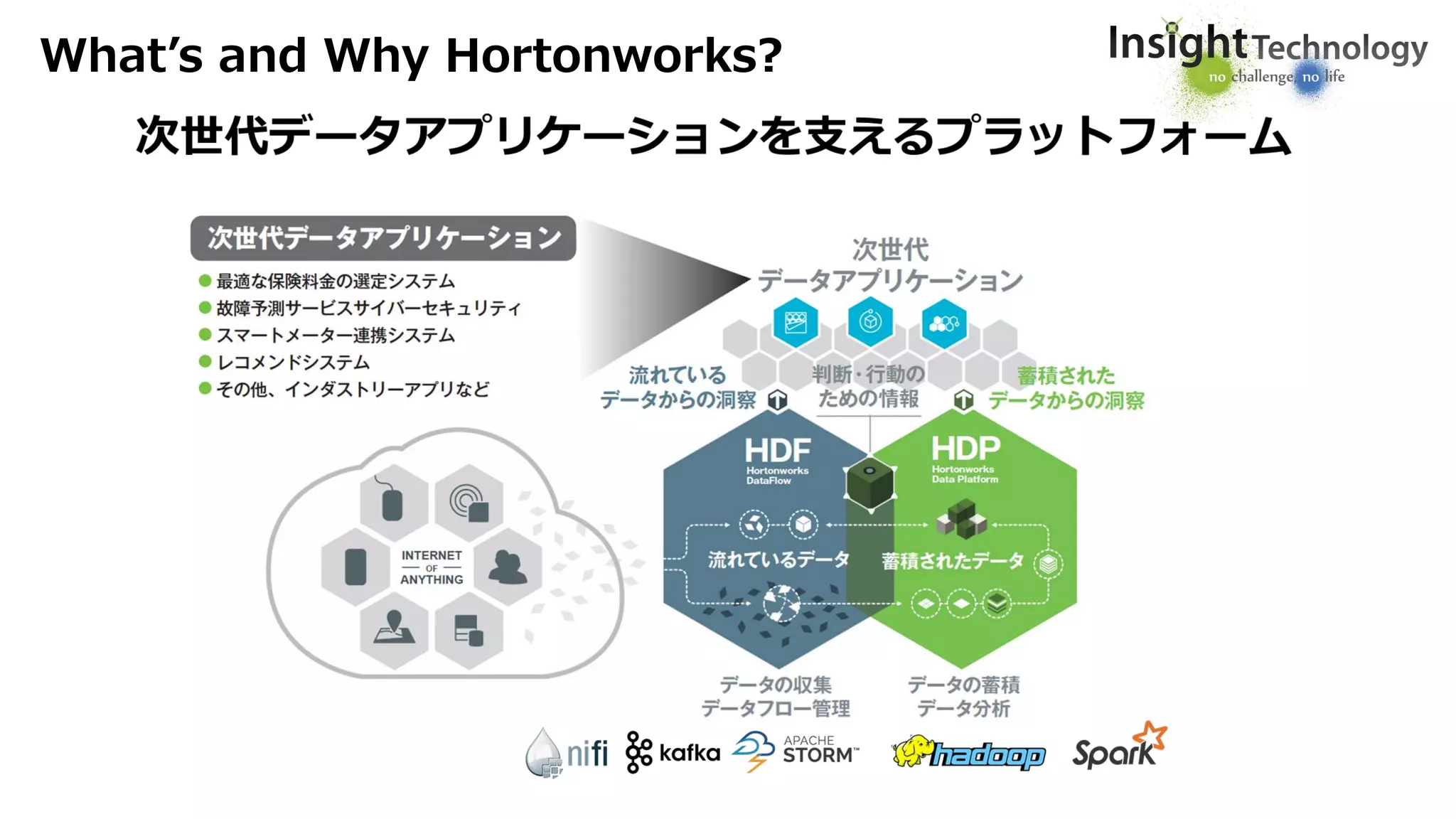
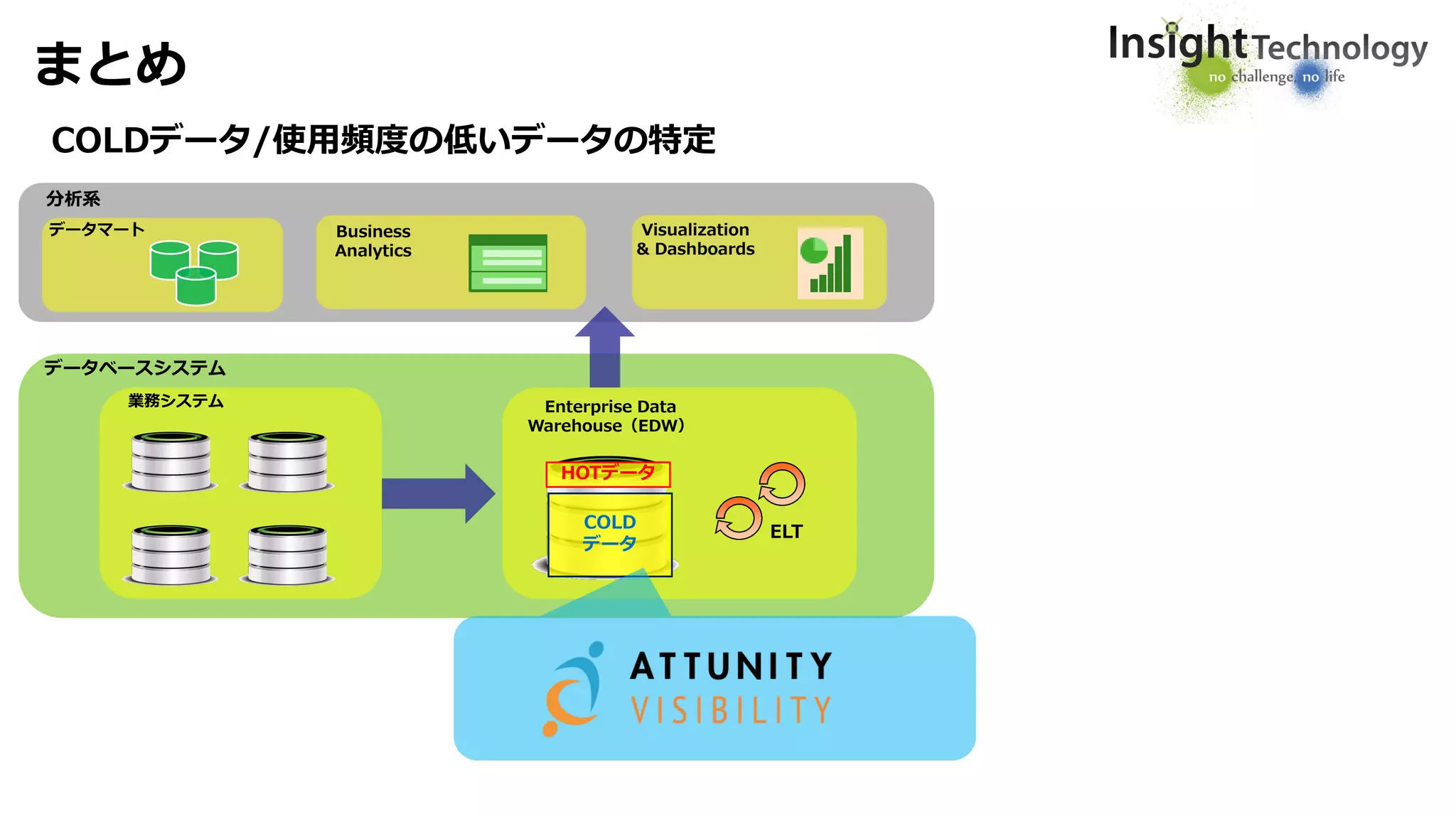
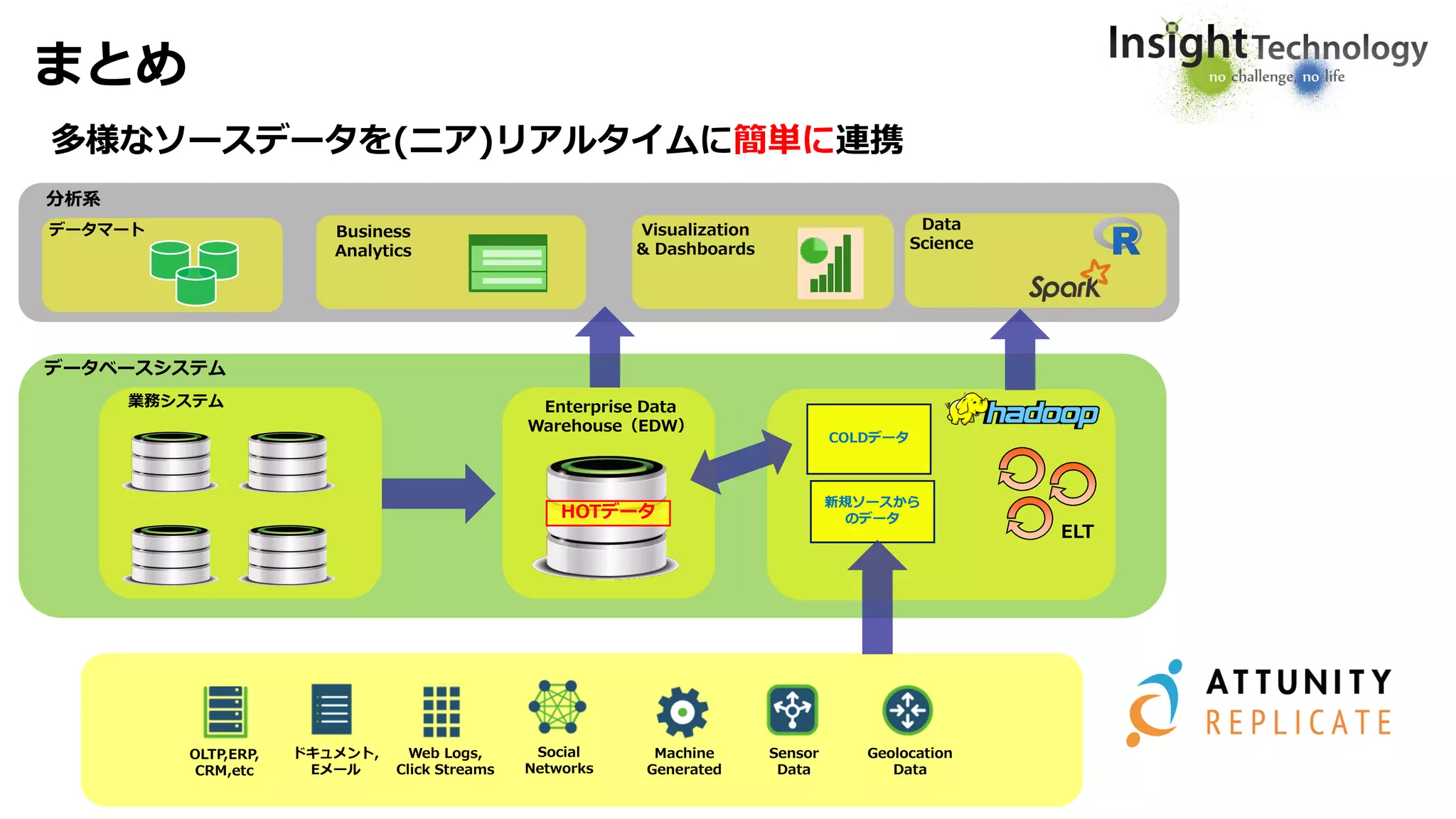
Enterprise Data Management
On Premises | Cloud | Across Platforms
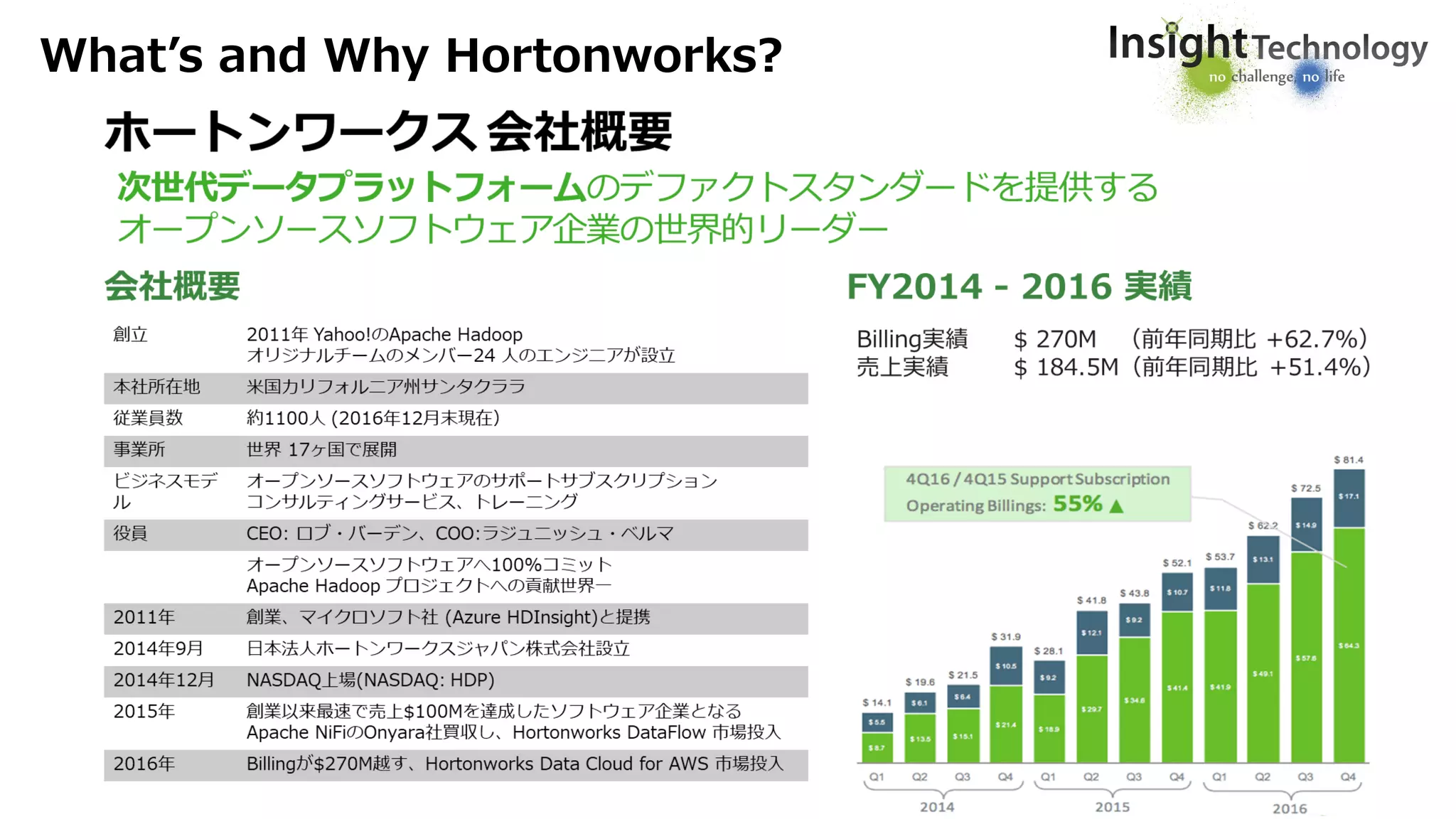
Attunity社 概要
1988年創業、データ統合において、20年以上にわたる研究開発と経験
CDC(更新データ捕捉)技術における独立系リーディング企業
米国、英国、イスラエル、日本、香港、台湾、韓国など、全世界的事業規模
65ヶ国で2,000社以上の顧客
12.
Microsoft with OEMand for over 8 Years
Oracle with OEM for over 13 years
IBM with OEM for over 9 years
Amazon (AWS) as a technology partner
Teradata as a reseller for Data Warehouse /Hadoop market
マイクロソフト、オラクル、IBMやその他の企業から認められ、選ばれた技術
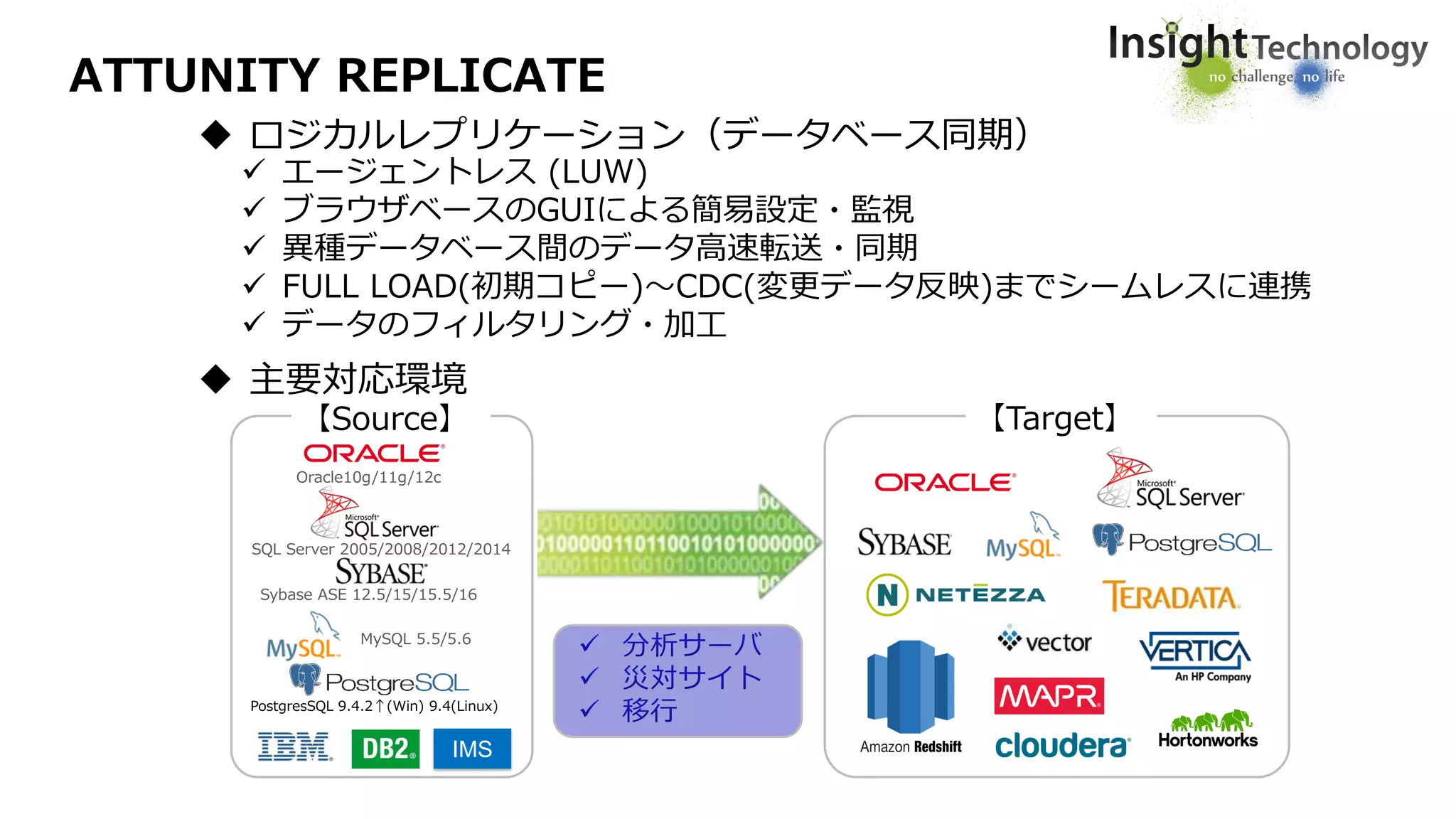
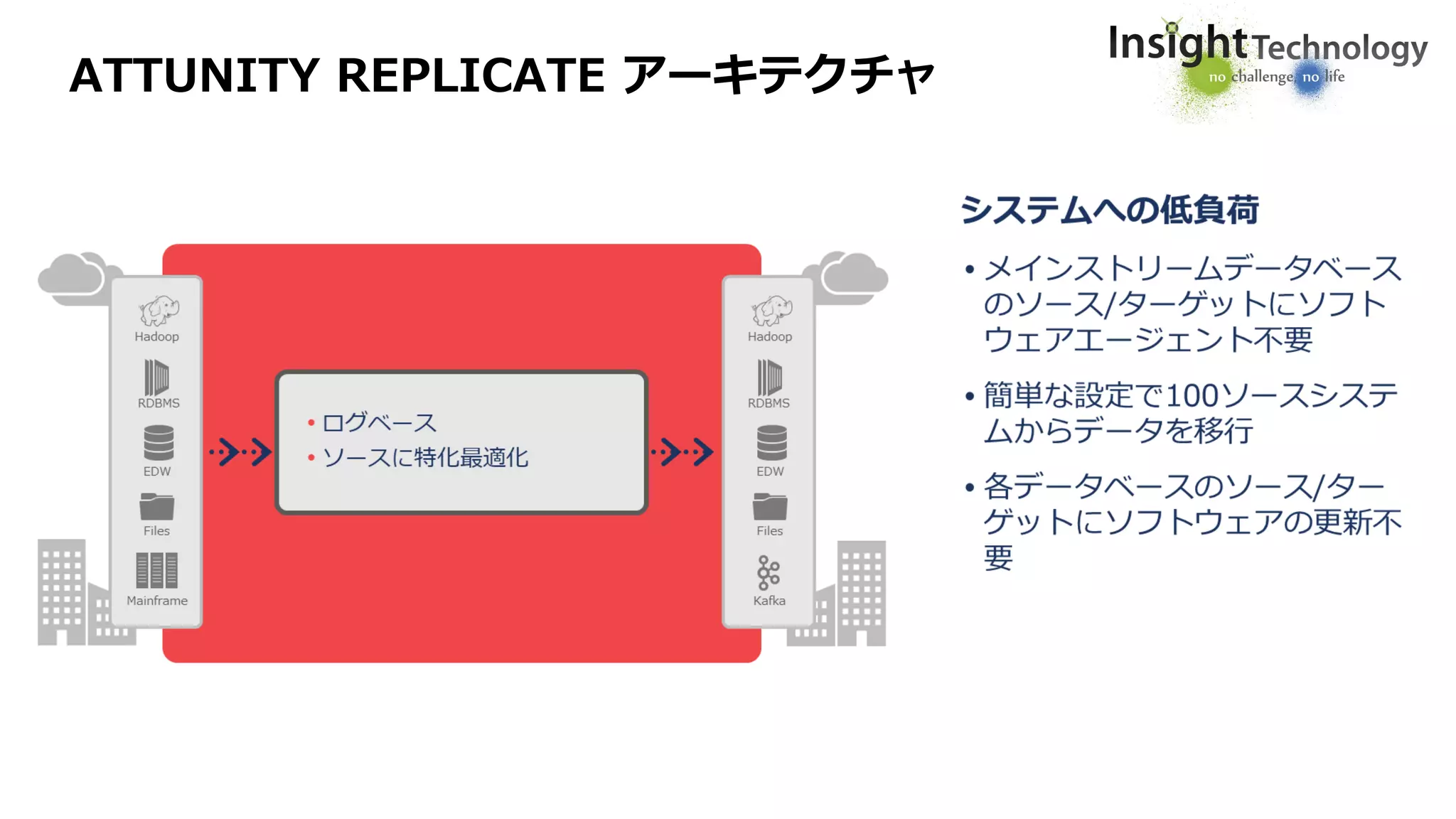
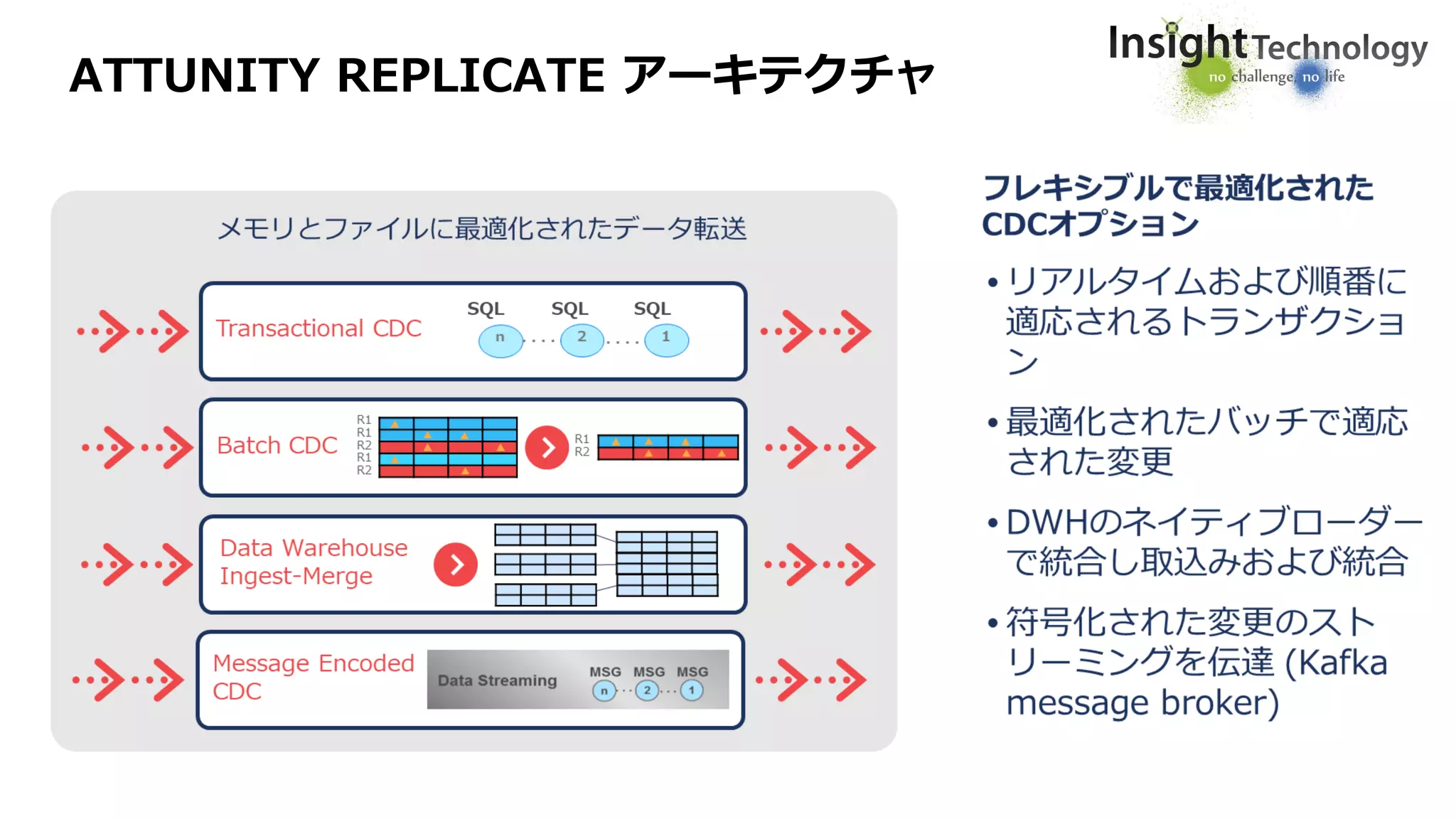
ATTUNITY REPLICATE
エージェントレス(LUW)
ブラウザベースのGUIによる簡易設定・監視
異種データベース間のデータ高速転送・同期
FULL LOAD(初期コピー)~CDC(変更データ反映)までシームレスに連携
データのフィルタリング・加工
【Target】【Source】
SQL Server 2005/2008/2012/2014
MySQL 5.5/5.6
Sybase ASE 12.5/15/15.5/16
IMS
PostgresSQL 9.4.2↑(Win) 9.4(Linux)
主要対応環境
ロジカルレプリケーション(データベース同期)
Oracle10g/11g/12c
20.
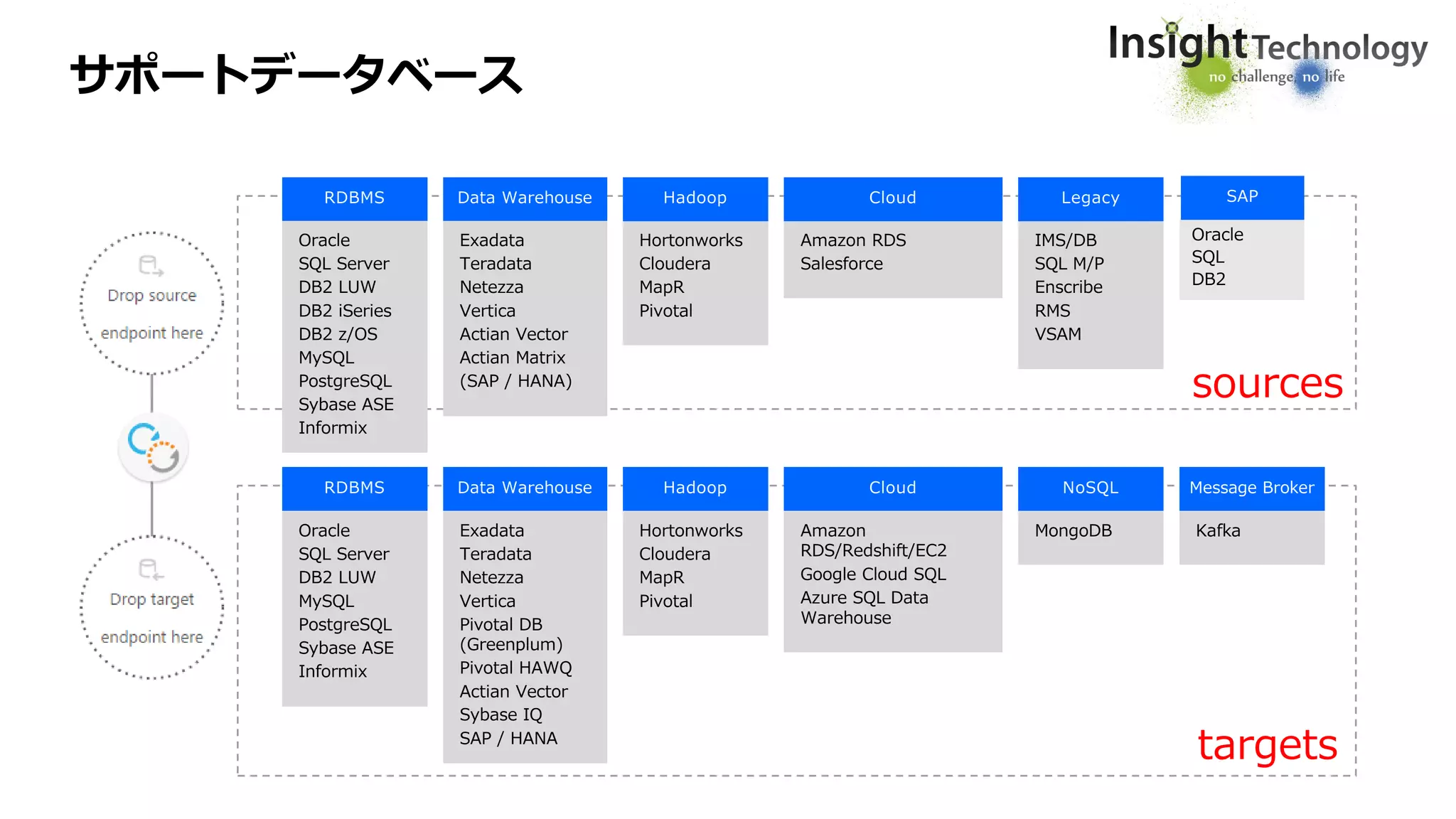
RDBMS
Oracle
SQL Server
DB2 LUW
DB2iSeries
DB2 z/OS
MySQL
PostgreSQL
Sybase ASE
Informix
Data Warehouse
Exadata
Teradata
Netezza
Vertica
Actian Vector
Actian Matrix
(SAP / HANA)
Hortonworks
Cloudera
MapR
Pivotal
Hadoop
IMS/DB
SQL M/P
Enscribe
RMS
VSAM
Legacy
Amazon RDS
Salesforce
Cloud
RDBMS
Oracle
SQL Server
DB2 LUW
MySQL
PostgreSQL
Sybase ASE
Informix
Data Warehouse
Exadata
Teradata
Netezza
Vertica
Pivotal DB
(Greenplum)
Pivotal HAWQ
Actian Vector
Sybase IQ
SAP / HANA
Hortonworks
Cloudera
MapR
Pivotal
Hadoop
MongoDB
NoSQL
Amazon
RDS/Redshift/EC2
Google Cloud SQL
Azure SQL Data
Warehouse
Cloud
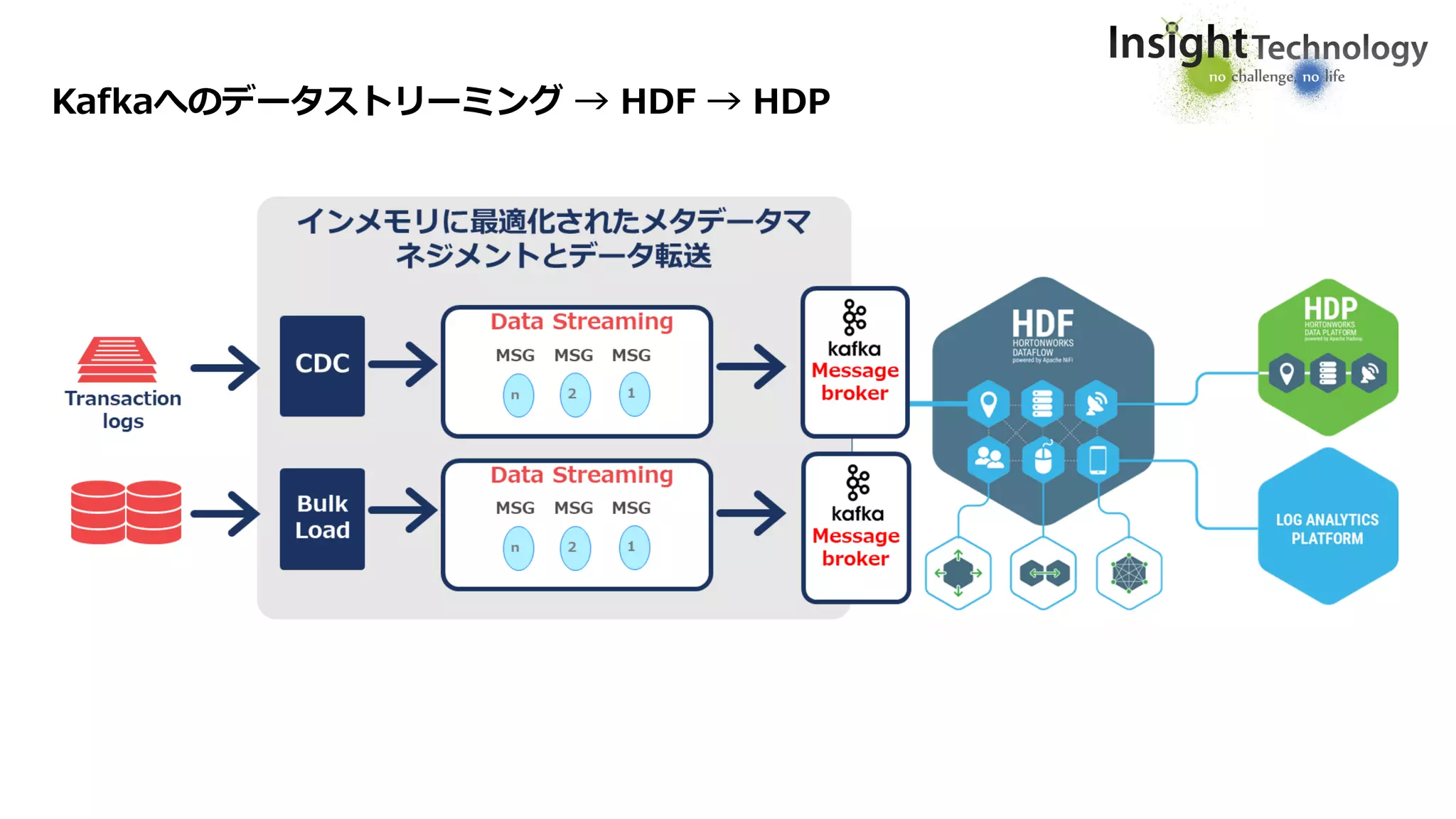
Kafka
Message Broker
targets
sources
Oracle
SQL
DB2
SAP
サポートデータベース
21.
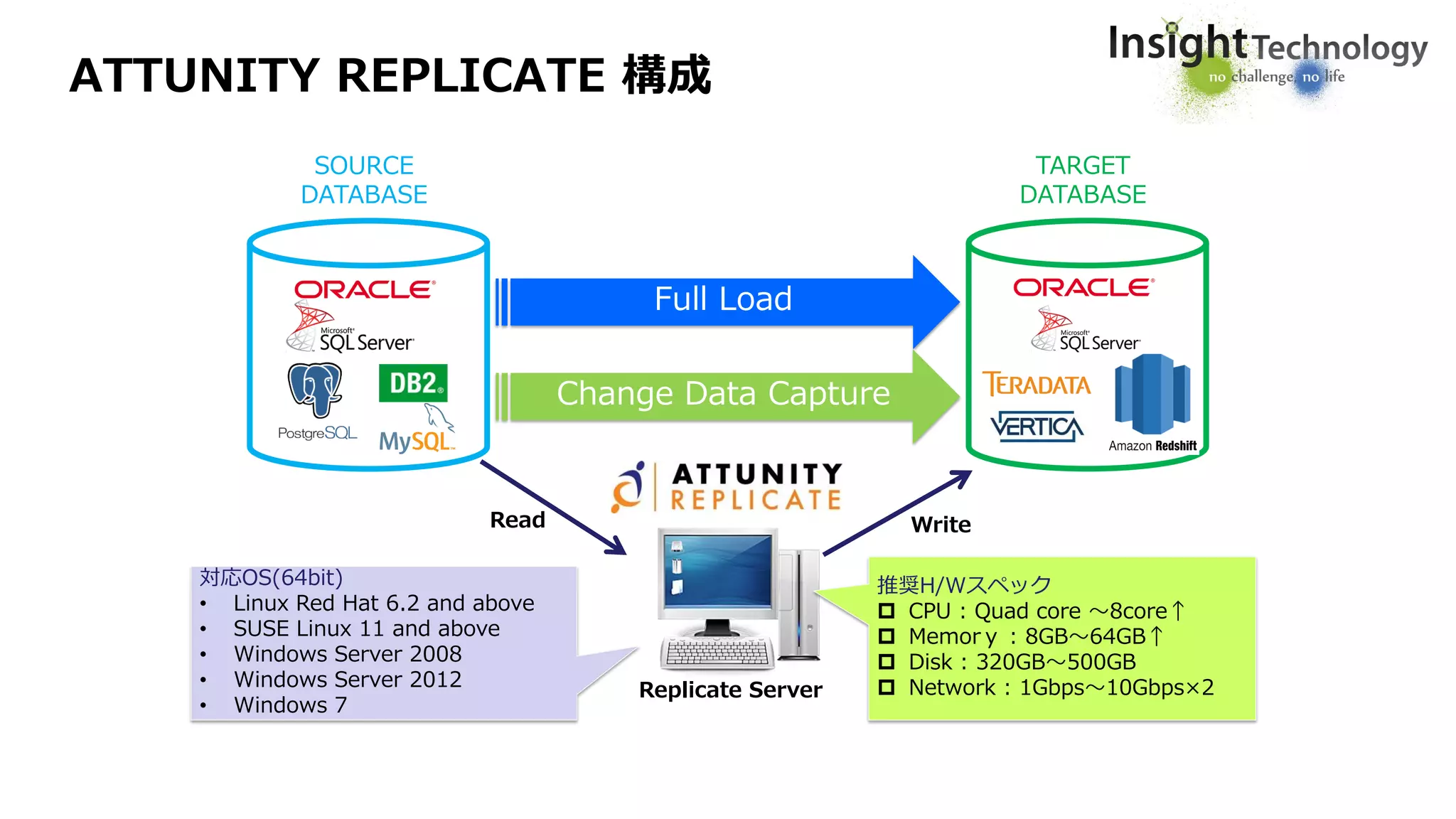
ATTUNITY REPLICATE 構成
ReplicateServer
対応OS(64bit)
• Linux Red Hat 6.2 and above
• SUSE Linux 11 and above
• Windows Server 2008
• Windows Server 2012
• Windows 7
推奨H/Wスペック
CPU : Quad core ~8core↑
Memory : 8GB~64GB↑
Disk : 320GB~500GB
Network : 1Gbps~10Gbps×2
SOURCE
DATABASE
TARGET
DATABASE
Read Write
Full Load
Change Data Capture





















![[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...](https://cdn.slidesharecdn.com/ss_thumbnails/b26-170912020934-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)


![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017e34-170911070313-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase OSS 2017] A22: NoSQL:誰のための、何のためのデータベース?その将来は?by Aerospike, ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcaseoss2017aerospike-170621081031-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...](https://cdn.slidesharecdn.com/ss_thumbnails/d21-170912022444-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] C25: 世界最速のAnalytic DBがHadoopとタッグを組んだ! ~スケールアウト検...](https://cdn.slidesharecdn.com/ss_thumbnails/c25-170913052337-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2018] #dbts2018 #E37 『Attunity Replicateが変えた Oracle D...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e37ctc-181004235303-thumbnail.jpg?width=640&height=640&fit=bounds)

































![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)







