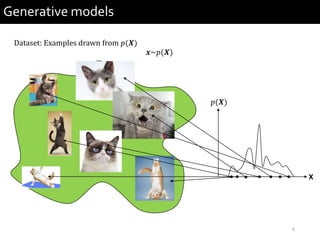
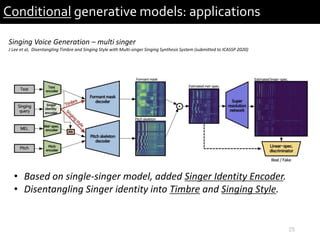
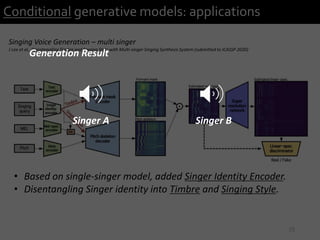
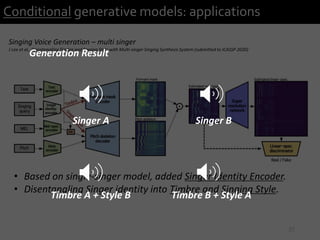
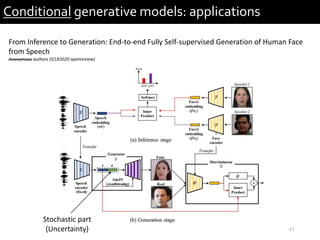
1) The document describes research presented by Hyeong-Seok Choi and Juheon Lee on conditional generative models for audio.
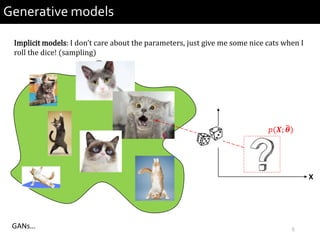
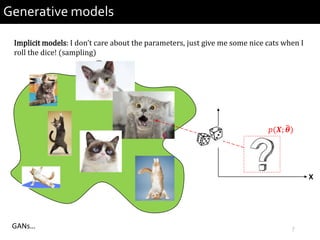
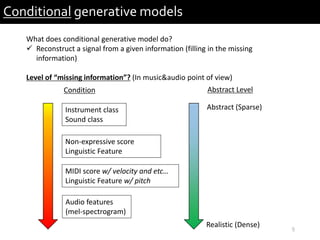
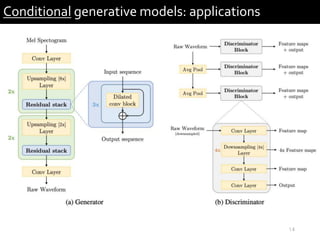
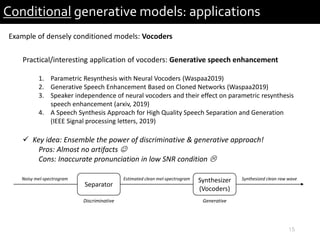
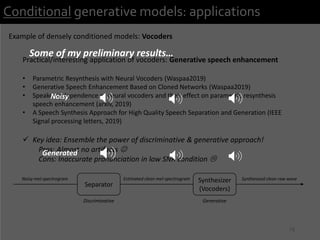
2) It provides examples of conditional generative models including vocoders for speech generation and singing voice synthesis models for generating singing from text and pitch inputs.
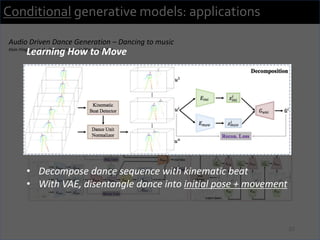
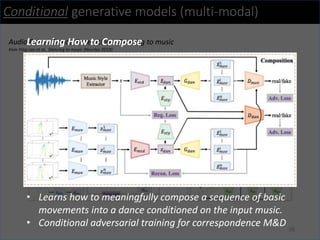
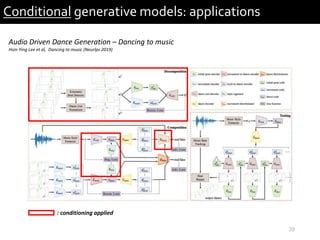
3) The researchers have worked on applications such as speech enhancement using generative models and audio-driven dance generation.






![11
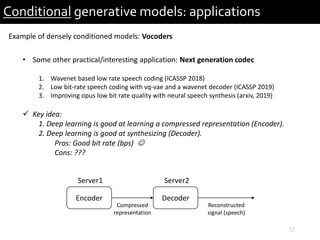
Conditional generative models: applications
Example of densely conditioned models: Vocoders (WaveRNN: training)
Upsample net
GRUs
… …
Input2:
wave[0:dim-1]
GroundTruth:
wave[1:dim]
Input1: mel-spectrogram
Num class: 2 𝑏𝑖𝑡𝑠
Training](https://image.slidesharecdn.com/soundlyconditionalgenerativemodelforaudio-191201165304/85/Conditional-generative-model-for-audio-11-320.jpg)
![12
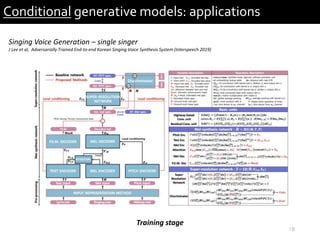
Conditional generative models: applications
Example of densely conditioned models: Vocoders (WaveRNN: training)
Inference
Upsample net
… …
Input: mel-spectrogram
0
0
Zero state
sample sample sample
x[1] x[2]
sample sample
x[N-1] x[N]x[N-2]…
…
output](https://image.slidesharecdn.com/soundlyconditionalgenerativemodelforaudio-191201165304/85/Conditional-generative-model-for-audio-12-320.jpg)

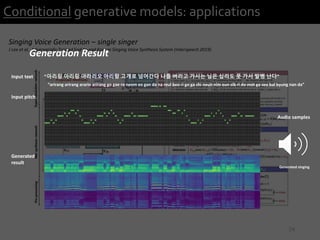
![21
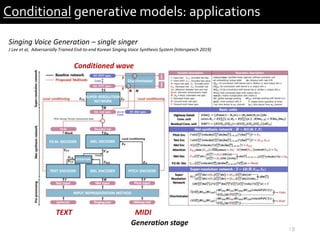
Conditional generative models: applications
Singing Voice Generation – single singer
J Lee et al, Adversarially Trained End-to-end Korean Singing Voice Synthesis System (Interspeech 2019)
Generation Result
Input text : “do re mi fa sol ra ti do”
Input pitch : [C D E F G A B C]
Generated audio :
FormantmaskPitchskeletonGeneratedmelspec.](https://image.slidesharecdn.com/soundlyconditionalgenerativemodelforaudio-191201165304/85/Conditional-generative-model-for-audio-21-320.jpg)
![22
Conditional generative models: applications
Singing Voice Generation – single singer
J Lee et al, Adversarially Trained End-to-end Korean Singing Voice Synthesis System (Interspeech 2019)
Generation Result
Input text : “do do do do do do do do”
Input pitch : [C D E F G A B C]
Generated audio :
FormantmaskPitchskeletonGeneratedmelspec.](https://image.slidesharecdn.com/soundlyconditionalgenerativemodelforaudio-191201165304/85/Conditional-generative-model-for-audio-22-320.jpg)
![23
Conditional generative models: applications
Singing Voice Generation – single singer
J Lee et al, Adversarially Trained End-to-end Korean Singing Voice Synthesis System (Interspeech 2019)
Generation Result
Input text : “do re mi fa sol ra ti do”
Input pitch : [C C C C C C C C]
Generated audio :
FormantmaskPitchskeletonGeneratedmelspec.](https://image.slidesharecdn.com/soundlyconditionalgenerativemodelforaudio-191201165304/85/Conditional-generative-model-for-audio-23-320.jpg)










































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





