

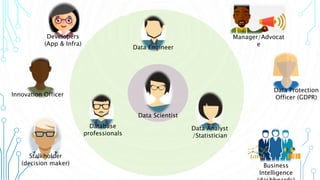
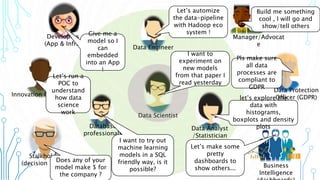

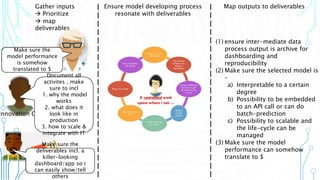








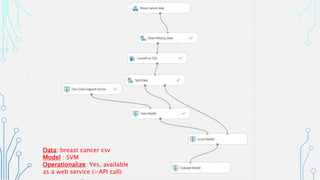

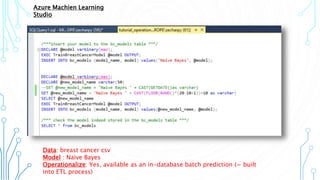

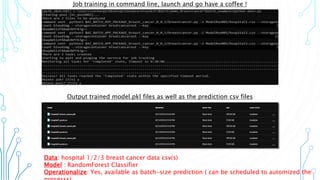
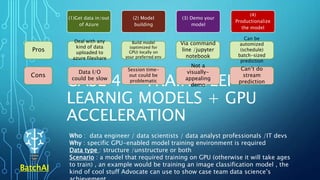
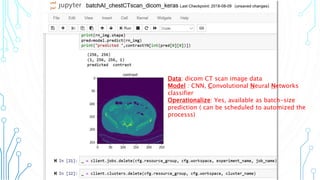
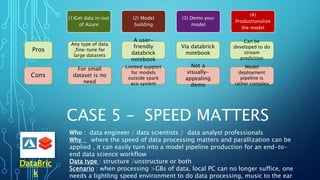
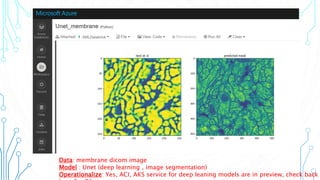






The document outlines an agenda focused on exploring data science practices within Azure for various professionals, including data scientists and managers. It emphasizes the need for compliance with GDPR while experimenting with models and conducting proofs of concept (POCs). The document also details specific case studies demonstrating data processing capabilities and the use of Azure services for machine learning.












![[Research] azure ml anatomy of a machine learning service - Sharat Chikkerur](https://cdn.slidesharecdn.com/ss_thumbnails/researchazuremlanatomyofamachinelearningservice-sharatchikkerur-150820102331-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





























































