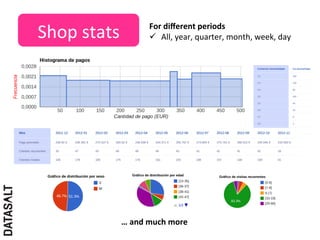
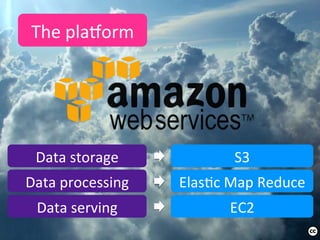
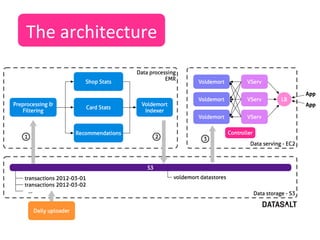
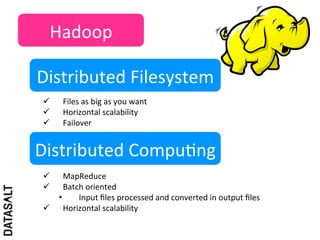
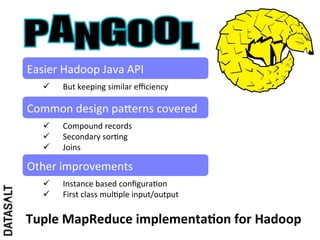
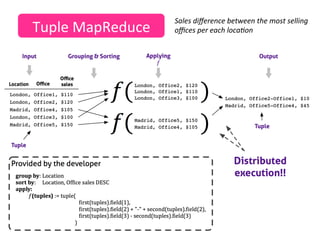
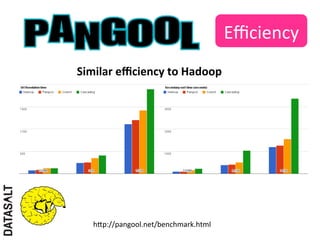
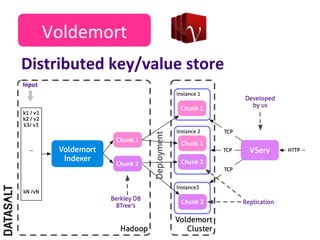
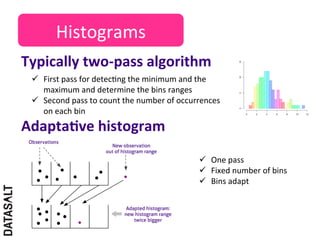
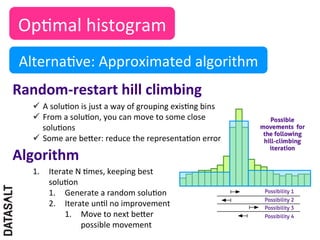
This case study describes how BBVA extracts value from anonymized credit card transaction data. It discusses how the data is shared in an impersonal, aggregated, dissociated, and irreversible manner to help consumers make informed shopping decisions and help sellers learn customer patterns. The challenges of company silos, data volume, security, and development are addressed through a Hadoop/Amazon Web Services architecture. Advanced analytics like histograms and optimal binning are also discussed.