







![Index access methods
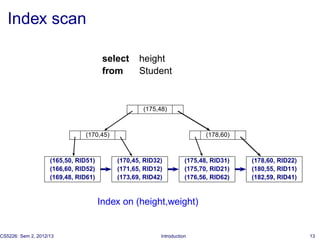
◮ Index scan
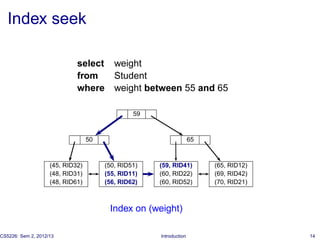
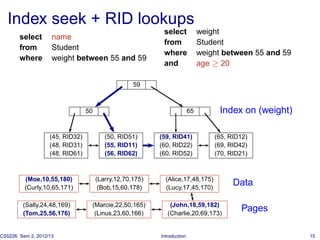
◮ Index seek [+ RID lookup ]
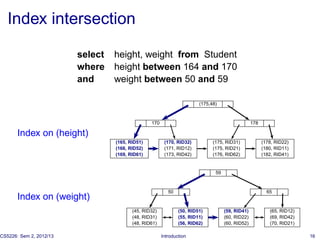
◮ Index intersection [+ RID lookup ]
CS5226: Sem 2, 2012/13 Introduction 12](https://image.slidesharecdn.com/database-slide2301-130118002701-phpapp01/85/Database-slide-12-320.jpg)





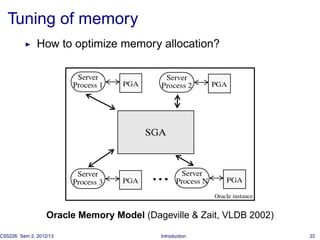
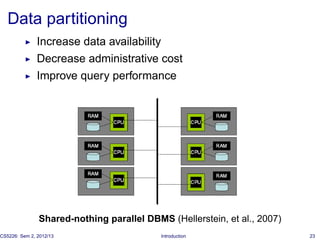


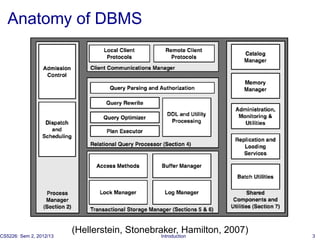
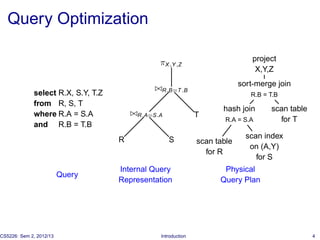
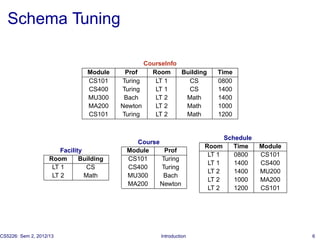
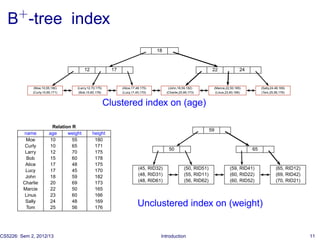
The document introduces database tuning and various performance tuning techniques. It discusses tuning the database at different levels, including the schema, queries, indexes, materialized views, statistics, concurrency control, memory, data partitioning, and hardware. Specific examples are provided for query tuning, index access methods, and materialized view tuning. References are also included for additional reading on database system architectures and memory tuning.






































































