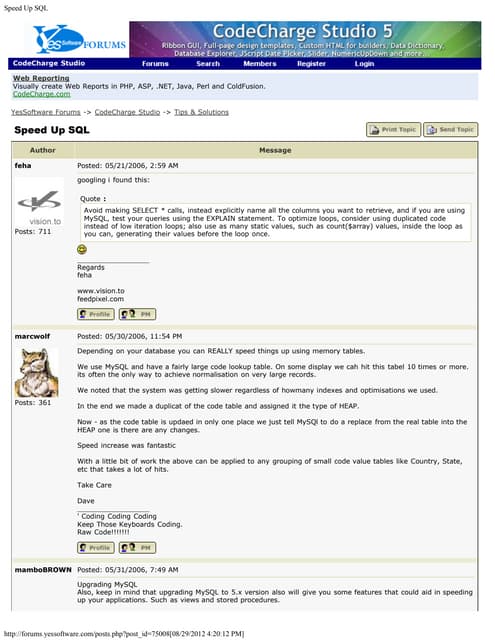
The document provides guidelines for database design, including naming conventions and best practices. It recommends using consistent naming conventions to avoid issues later on. Key points include:
- Use camelCase and avoid special characters for names. Prefix table names with unique identifiers.
- Primary keys should be named {TablePrefix}OID and foreign keys should match the primary key name in the referenced table.
- Attribute names should be self-explanatory like Invoices.InvIsPrinted rather than ambiguous names.
- Consistent naming conventions are important for maintenance and analyzing data across the whole system.

![different prefixes like Inv for Invoices and Ivt for Inventories. The prefix
is part of each attribute name and should be used in related sequences and
index names as well.
So far, so easy. When it comes to attribute names, naming conventions
become more complicated. Let's start with technical attributes, because
there is no occasion for interpretations.
In order to guarantee uniqueness, each table has a technical primary
key (a surrogate primary key populated by the create trigger with a unique
sequence value, but preferential a UUID), which will never get a
business meaning. Don't argue, primary keys with business meaning as
well as composite keys are a bad idea. There is nothing to say against
additional unique columns with business meaning, but do not merge the
underlying technical implementation with your business logic. Name the
primary key = table prefix + OID (or ID), e.g. CustOID or CustID. If an
object has children or is an attribute of other objects, use the unchanged
and unextended name of the parent table's primary key as foreign key in
the child table respectively referencing table.
Say you've a table Invoices and a table Addresses:
Addresses.AdrOID [primary key]
Addresses.AdrOtherAttributes ...
Invoices.InvOID [primary key]
Invoices.AdrOID [foreign key]
Invoices.InvOtherAttributes ...
Index Invoices.AdrOID and you can code
FOR EACH Addresses OF Invoices:
Do something.
END.
or
FOR EACH Invoices WHERE Invoices.InvNetAmount >= 1000.00,
EACH Addresses OF Invoices WHERE Adresses.AdrZipCode BEGINS '34':
Do something.
END.
instead of
FOR EACH Addresses WHERE Addresses.AdrOID = Invoices.AdrOID:
Do something.
END.
There is one exception to this rule. Sometimes an object is an attribute of
another object multiple times, without being a class itself. Different roles are
marked by a number sign '#'. The most important foreign key name is kept
as is, other roles are extended by '#Role':
Invoices.InvOID [primary key]
Invoices.AdrOID [billing address]
Invoices.AdrOID#Delivery [delivery address]
Actually, this is way beyond a clean (normalized) database design. Also,
most design tools will not handle such non-normalized structures. If](https://image.slidesharecdn.com/databasedesignguide-120122125039-phpapp01/75/Database-design-guide-2-2048.jpg)
![possible, you should avoid attribute name extensions, better normalize
instead. To bring this point home, let's say your customers provide
permanent delivery addresses. By the way, delivery addresses tend to have
their own attributes and behavior. Most probably a bunch of shipping
addresses are an attribute of Customers:
DeliveryAddresses.DelAdrOID [primary key]
DeliveryAddresses.CustOID [foreign key]
DeliveryAddresses.AdrOID [foreign key]
DeliveryAddresses.DelAdrDispatchType [another attribute, which in real life
would be the reference to a carrier]
Invoices normalized:
Invoices.InvOID [primary key]
Invoices.AdrOID [billing address]
Invoices.DelAdrOID [delivery address]
Let's come to attributes with business meaning. Besides technical
attributes in different roles, I can think of other cases where it is necessary
to extent attribute names. For example default values. As long as there is
just one default value, put it in the attribute's definition. Otherwise you've a
table storing those values:
Discounts.DiscOID
Discounts.DiscAppliesToBusinessType[e.g. wholesale, distributors, retail...]
Discounts.DiscPercent
Since discounts given to customers are calculated individually, the
percentage can vary from customer to customer and it makes no sense to
reference Discounts in Customers. However, in the interest of a readable
model it is good style to mark the source, therefore the attribute discount
percent of Customerskeeps it's source:
Customers.CustOID
Customers.DiscPercent#Cust
There are other advantages of consistent naming rules. In commercial
applications you're dealing with discount percentages in tons of objects.
Imagine you need to analyze your enterprise wide discount policy. Finding
all instances of discount percentages can become a PITA in complex
systems. Consistent naming provided, you can search in your system tables
for 'DiscPercent*' and you get a complete list:
Discounts.DiscPercent
Customers.DiscPercent#Cust
Invoices.DiscPercent#Inv
InvoiceLines.DiscPercent#InvLine
...
If your application shall be used by a group of (affiliated) companies, where
each single company is representing another client in the multi-client
capable accounting system, things become difficult. The easiest solution
would be the physical splitting of your ERP database. Keep all common](https://image.slidesharecdn.com/databasedesignguide-120122125039-phpapp01/75/Database-design-guide-3-2048.jpg)


![to each attribute. Besides the above mentioned object identifiers and one to
many relationships, you need a policy for many to many
relationships too. Those are kind of technical classes, making complex
relationships persistent. Users will never see their names nor attributes, so
you may use geek speech. Here is a proven system: name those tables
composing your unique table prefixes delimited by the digits '2' (to) and '4'
(for). If your customers can belong to different groups, the table
representing the relationship 'customers [belonging] to customer groups' is
named Cust2CustGrp and contains only three keys:
Cust2CustGrp.Cust2CustGrpOID [primary key]
Cust2CustGrp.CustOID [foreign key]
Cust2CustGrp.CustGrpOID [foreign key]
To handle all customers of a group you code
FOR EACH Cust2CustGrp OF CustomerGroups,
EACH Customer OF Cust2CustGrp:
Do something.
END.
To get a list of all groups a customer belongs to you write:
FOR EACH Cust2CustGrp OF Customers,
EACH CustomerGroups of Cust2CustGrp:
Do something.
END.
In some rare cases these prevailing technical classes have other attributes.
Pragmatically, here I'd go for an descriptive table label and stick with the
geeky table name. Actually, most probably those attributes are simple
connections, keeping the table itself invisible to users. E.g. if you've a table
storing Xmas present types, you could assign the type (or value) of presents
depending on one of the groups assigned to your customers:
XmasPresentTypes.XptOID
XmasPresentTypes.XptPostardOnly
XmasPresentTypes.XptPrice
Cust2CustGrp4Xpt.Cust2CustGrp4XptOID [primary key]
Cust2CustGrp4Xpt.Cust2CustGrpOID [foreign key]
Cust2CustGrp4Xpt.XptOID [foreign key]
or
Cust2CustGrp4Xpt.Cust2CustGrp4XptOID [primary key]
Cust2CustGrp4Xpt.CustOID [foreign key]
Cust2CustGrp4Xpt.CustGrpOID [foreign key]
Cust2CustGrp4Xpt.XptOID [foreign key]
Pick whatever fits your needs best.
Now let's come to another important rule: Separate all technical stuff
from your business logic. You can't avoid technical attributes in tables
representing business objects, but you can and you should handle them
separately. For example you can assign values like
Table.PrefixOID
Table.PrefixUserLastUpdate (if you don't log user activities, probably you need to store these
data on creation too)](https://image.slidesharecdn.com/databasedesignguide-120122125039-phpapp01/75/Database-design-guide-6-2048.jpg)
![Table.PrefixDateLastUpdate
Table.PrefixTimeLastUpdate
Table.PrefixIsActive || Table.PrefixIsDeleted
in database triggers. Be aware that in n-tier architectures database triggers
usually do not know the user. If you need to log user activities, you can
implement this feature in your key wrapping widgets. Since your
technical primary keys can't be used in user interfaces, you create a key
wrapping widget for each primary key. This widget knows the invisible
primary key and enables the user to choose or enter one or more attributes
with business meaning, which can be used to identify an object. Looking at a
data viewer, those widgets appear just like fill-in fields with search button or
combo boxes. In the background they pass values of technical keys as well
as screen values of their visible attributes with business meaning to an
application server, or another process handling your persistent objects.
Back to logging. Since every data viewer must contain at least one key
wrapping widget (one handling the primary key and probably a few others
handling foreign keys), you can determine the current user here. Just pass
another hidden value to your persistence handler. Then in the database
trigger you compare the old and new buffer, logging changes only. With a
Progress® database, you can fully automate user activity logging using
generated includes in write triggers, made up by a tool accessing the virtual
system tables (VST). By the way, you should assign values to primary keys
in create triggers only. At this point, recap another important rule on state
of the art software design: Do not put any business logic into the user
interface code. Think SOA and encapsulate technical services as well as
audit trail requirements.
Another rule of thumb is: Do not delete physically. Admitted deletions are
technically possible, they are way too expensive, not really necessary and
furthermore you destroy information which as a rule you will need some
day. Deleting logically on the other hand perfectly keeps your referential
integrity, and it is way faster because your database servers update just one
column in a parent table, instead of bothering with often almost endless
cascading deletes along with RI checks. Adding a WHERE clause [NOT]
ParentTable.PrefixIsDeleted, or, much better, [NOT]
ParentTable.PrefixIsActive is cheap in comparison with all the nasty
side effects of physical deletion. Tell your delete button to set a logical
attribute isDeleted to true, or even dump the button and use a check box
instead, which allows your users to reactivate inactive objects.
Large projects can easily exceed the physical limits set by your database
system. If you deal with very large amounts of data in particular entities,
ensure that primary keys of (physically sliced) mega entities are never used](https://image.slidesharecdn.com/databasedesignguide-120122125039-phpapp01/75/Database-design-guide-7-2048.jpg)







![ServicePilot ISM Express Datasheet [EN]](https://cdn.slidesharecdn.com/ss_thumbnails/ismexpressdatasheeten-111228053621-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![ServicePilot NBA for z/OS Datasheet [EN]](https://cdn.slidesharecdn.com/ss_thumbnails/nbaforzosdatasheeten-111228073147-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![ServicePilot ISM Enterprise Datasheet [EN]](https://cdn.slidesharecdn.com/ss_thumbnails/ismenterprisedatasheeten-111228053311-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)