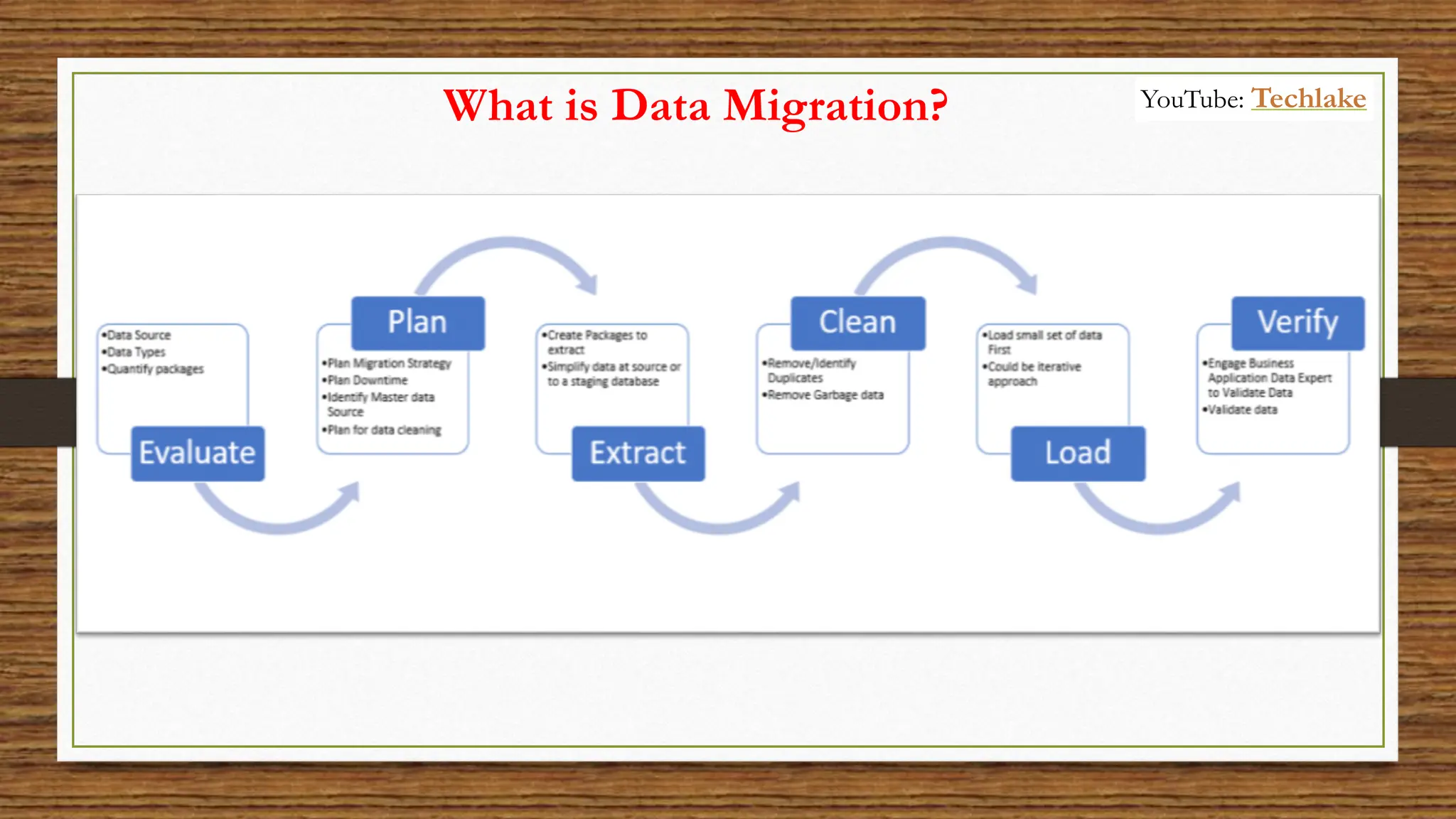
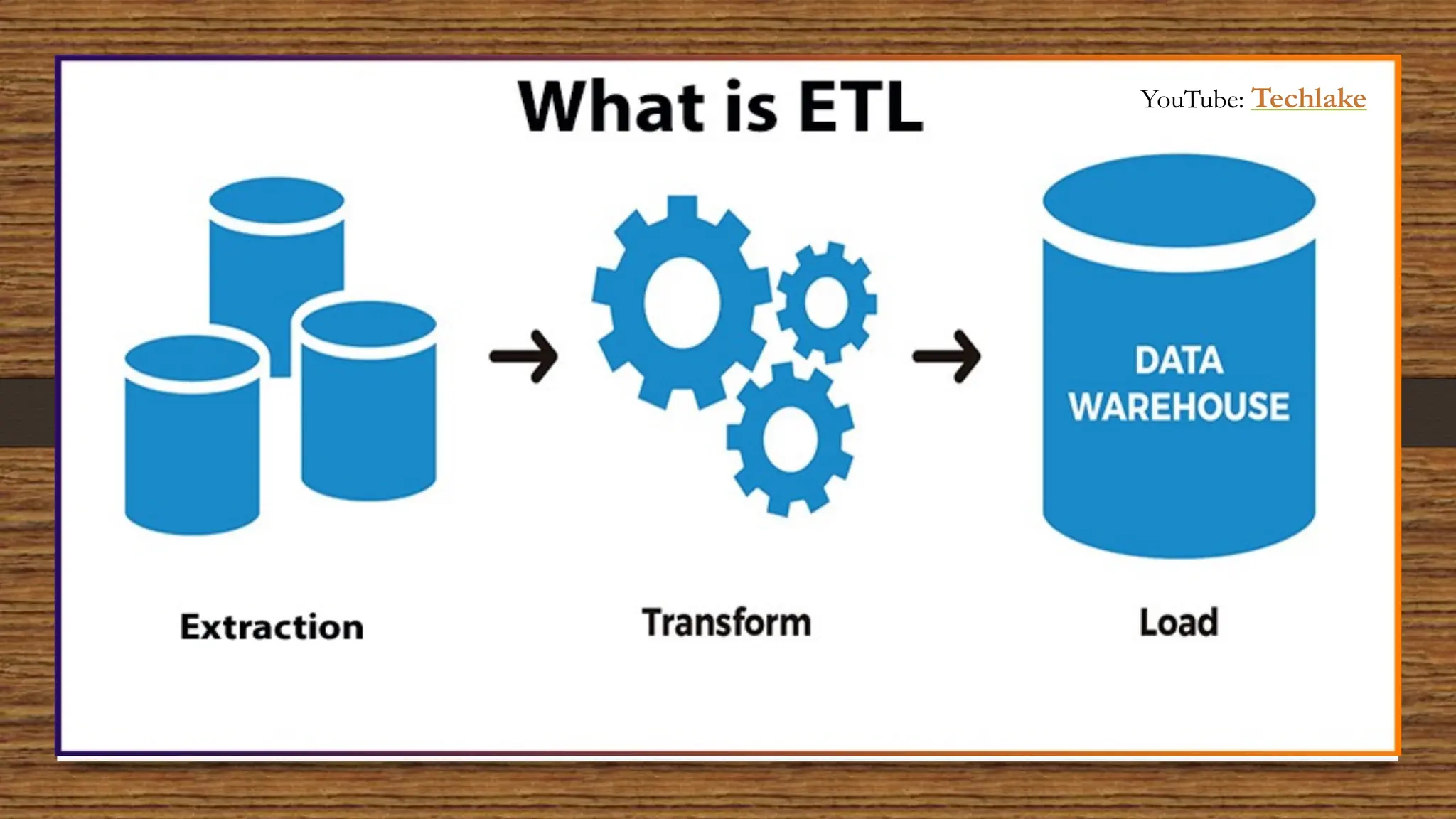
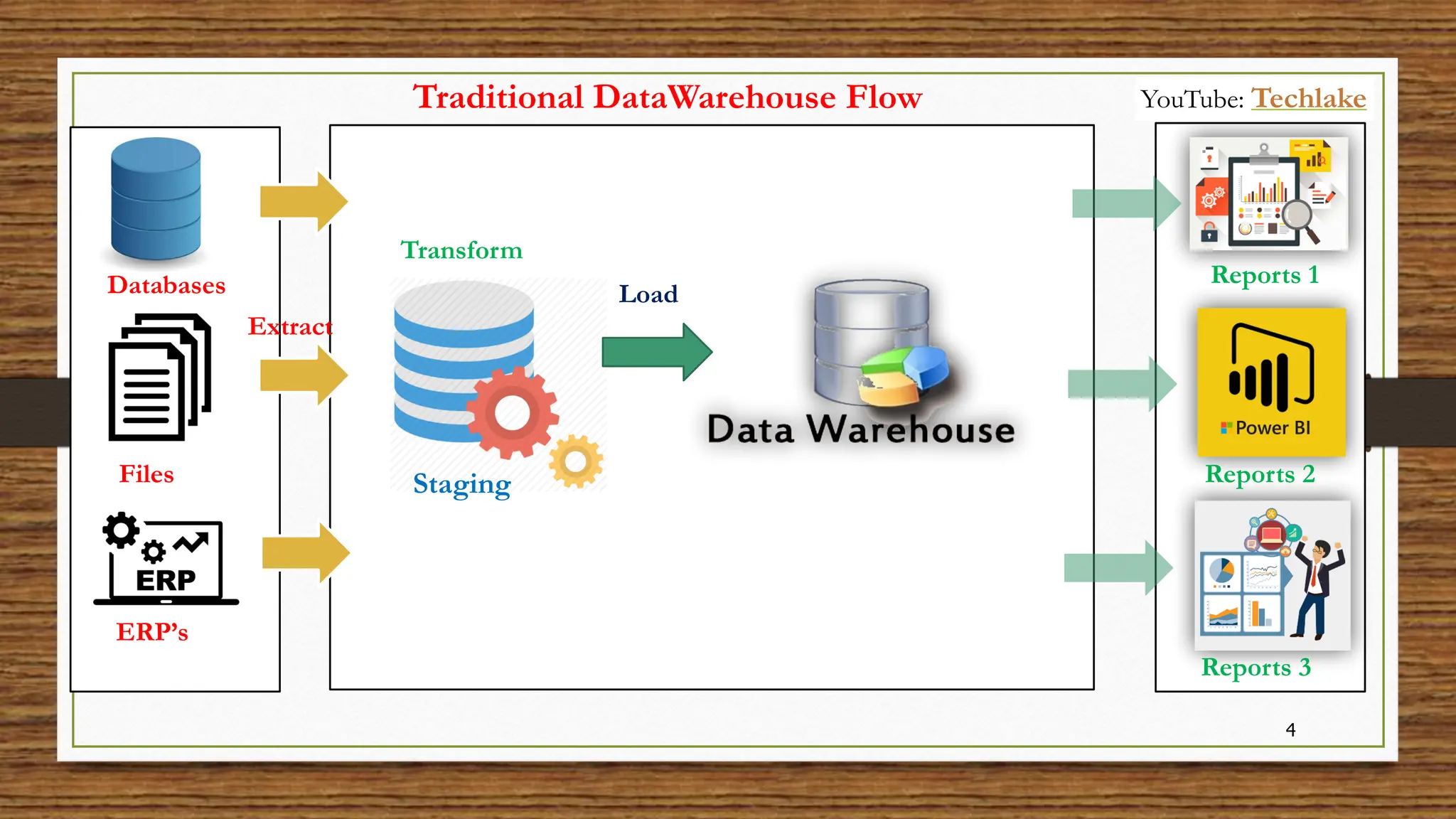
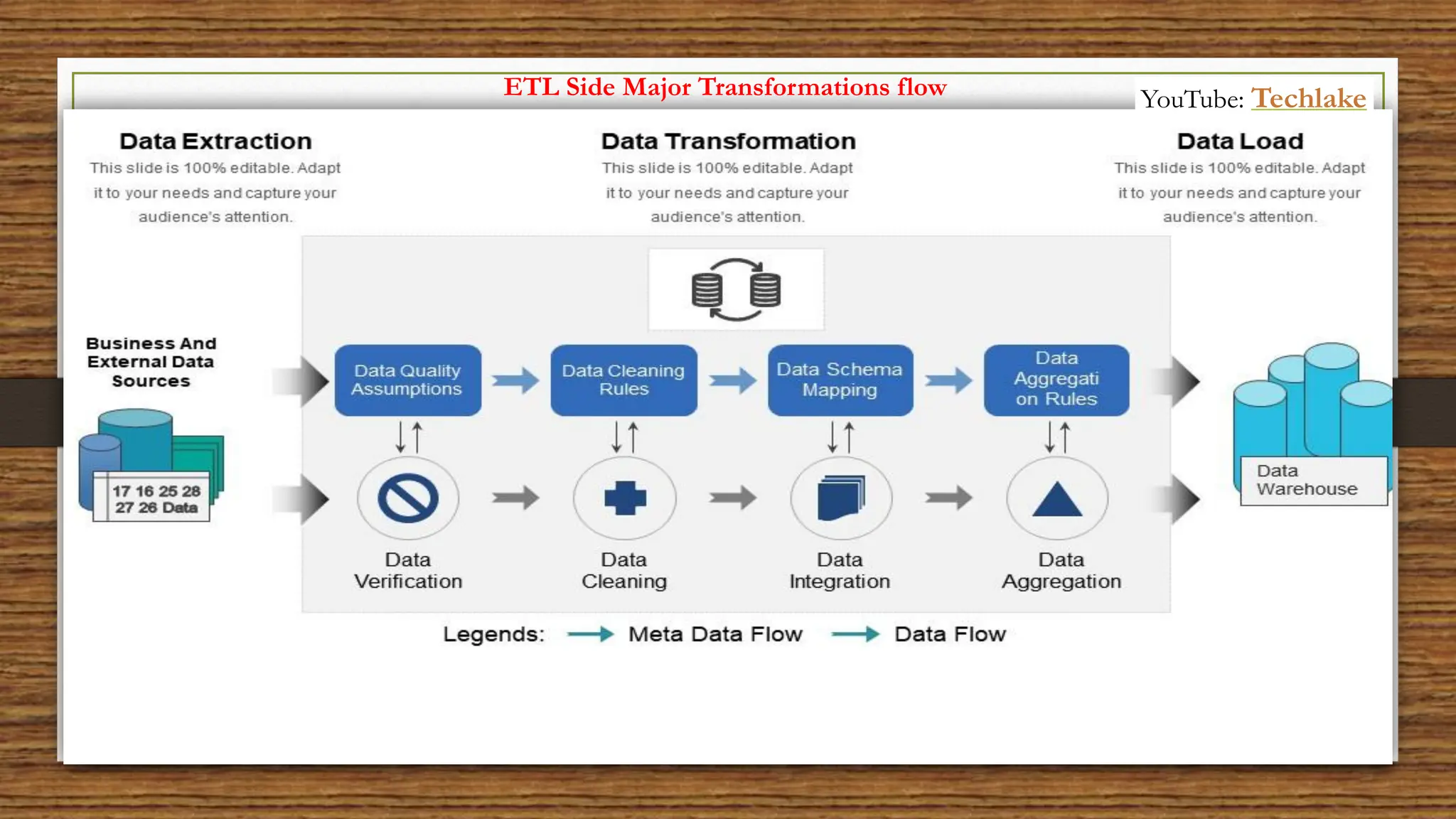
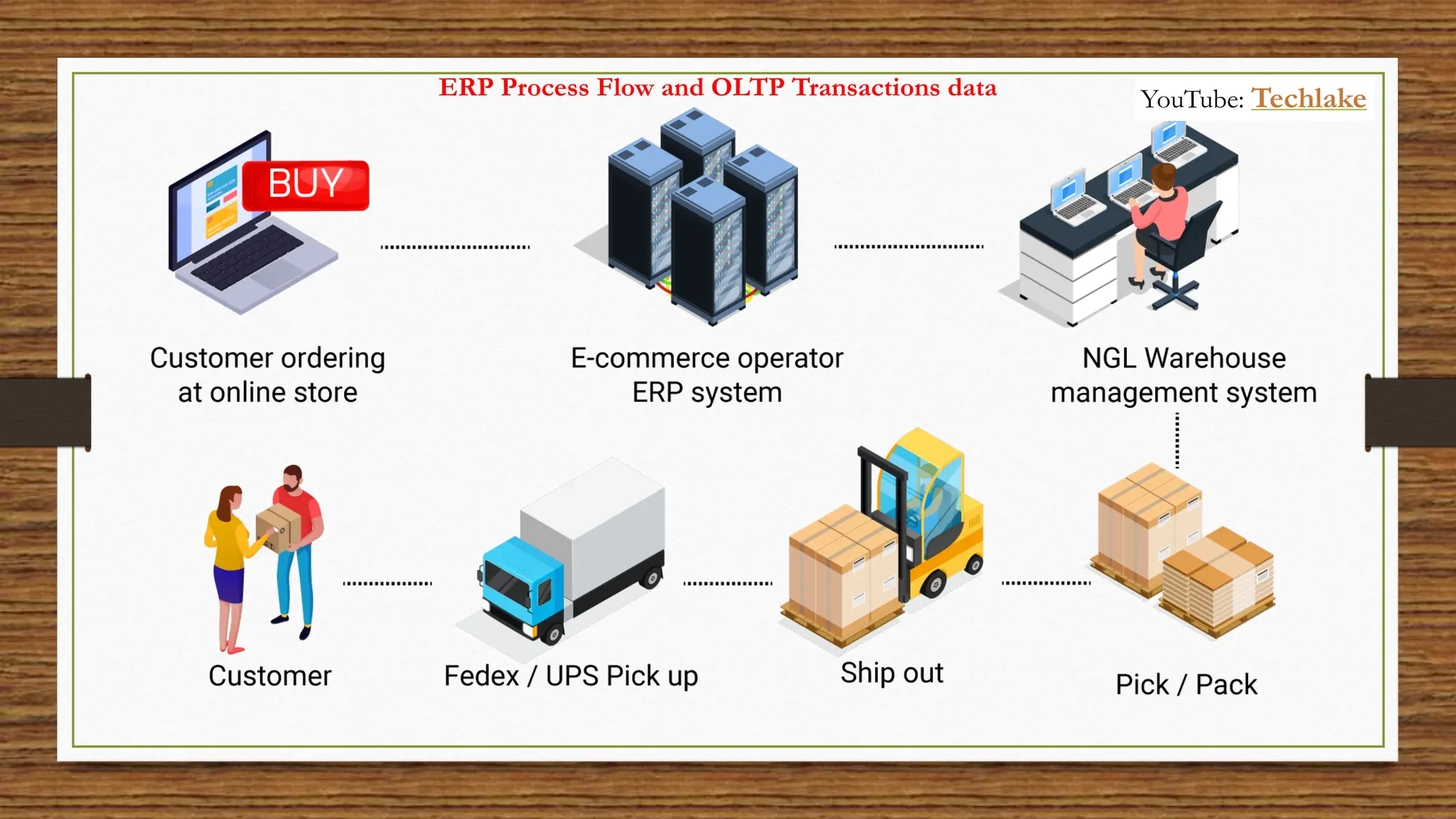
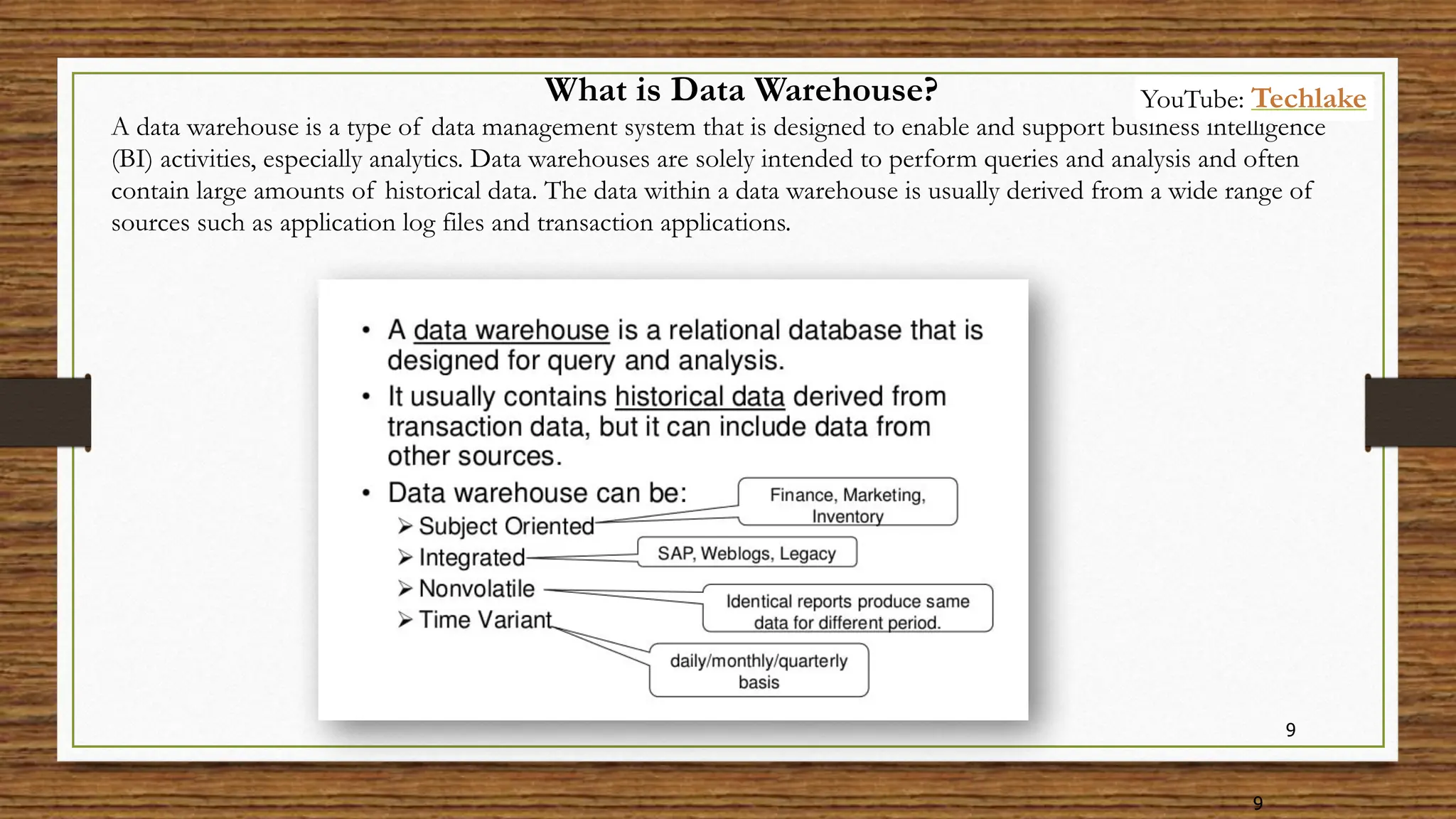
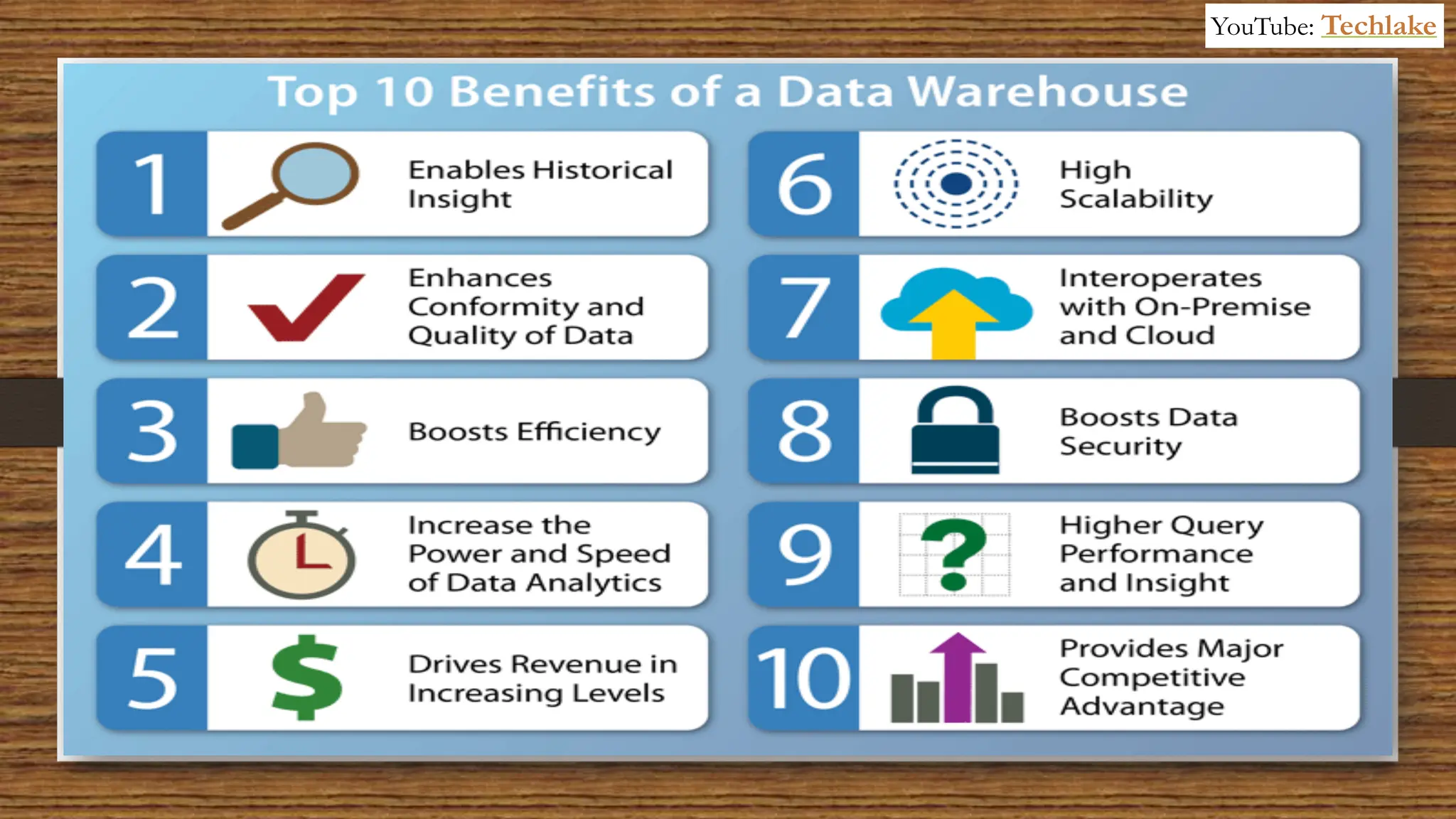
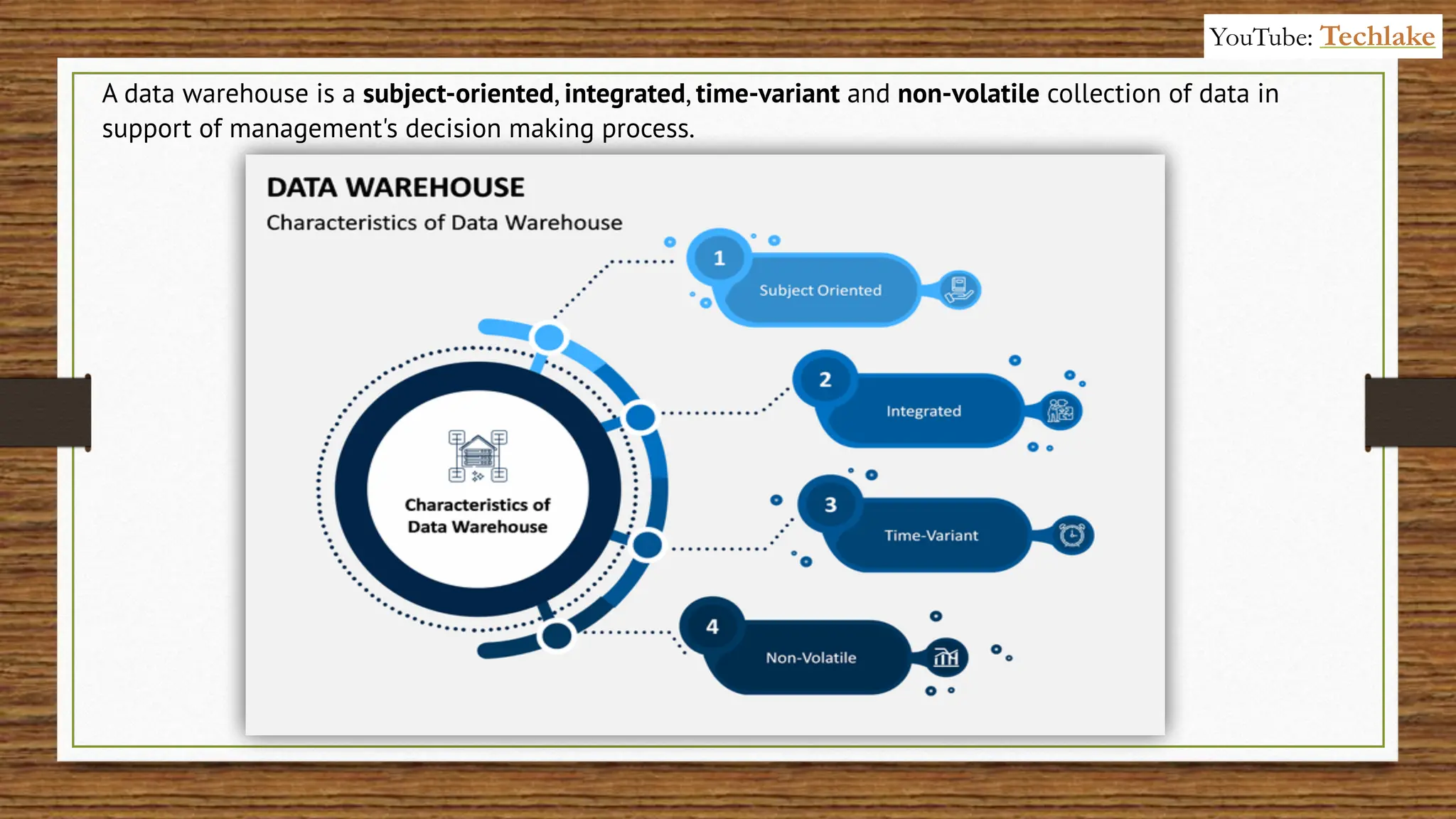
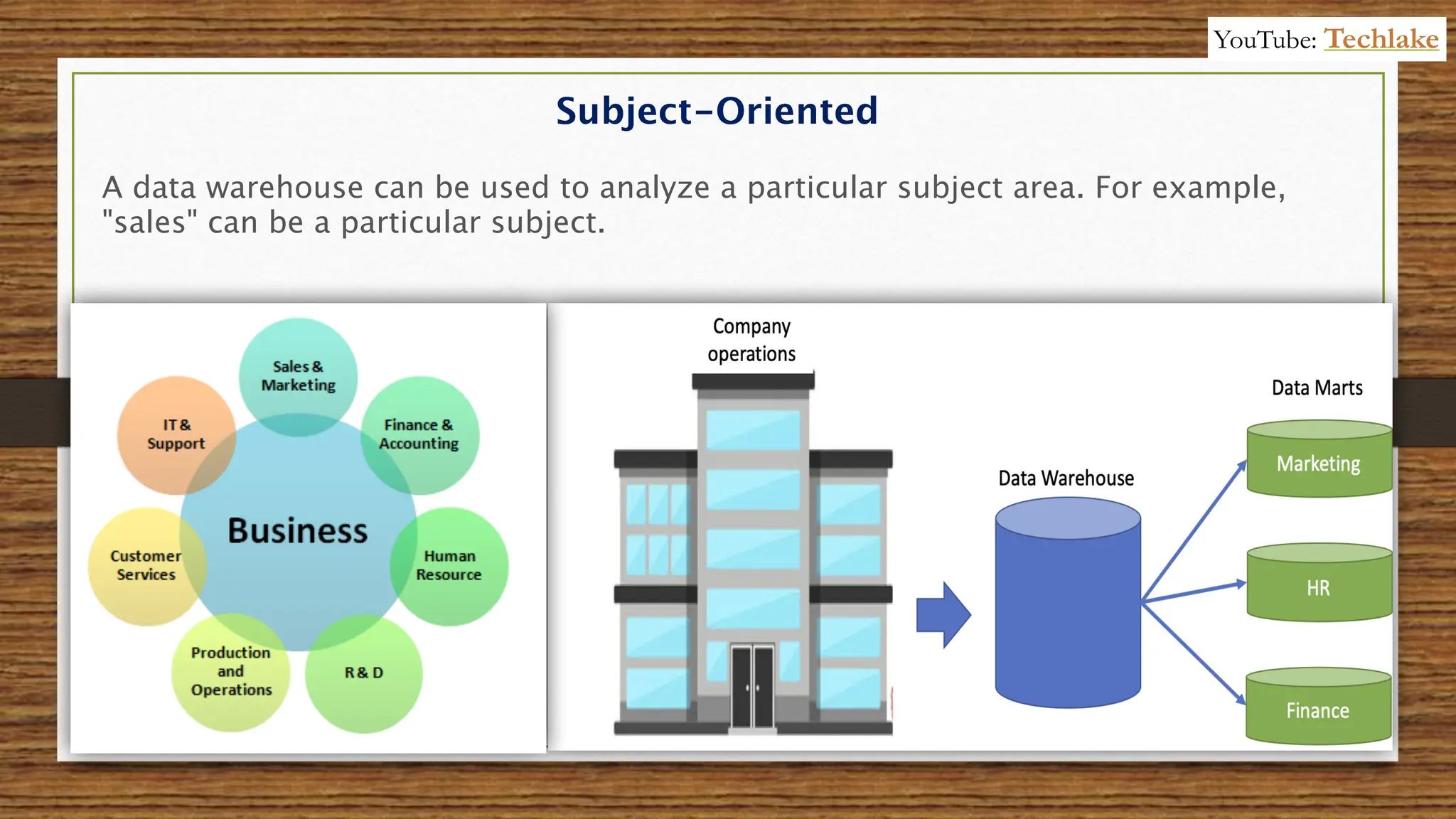
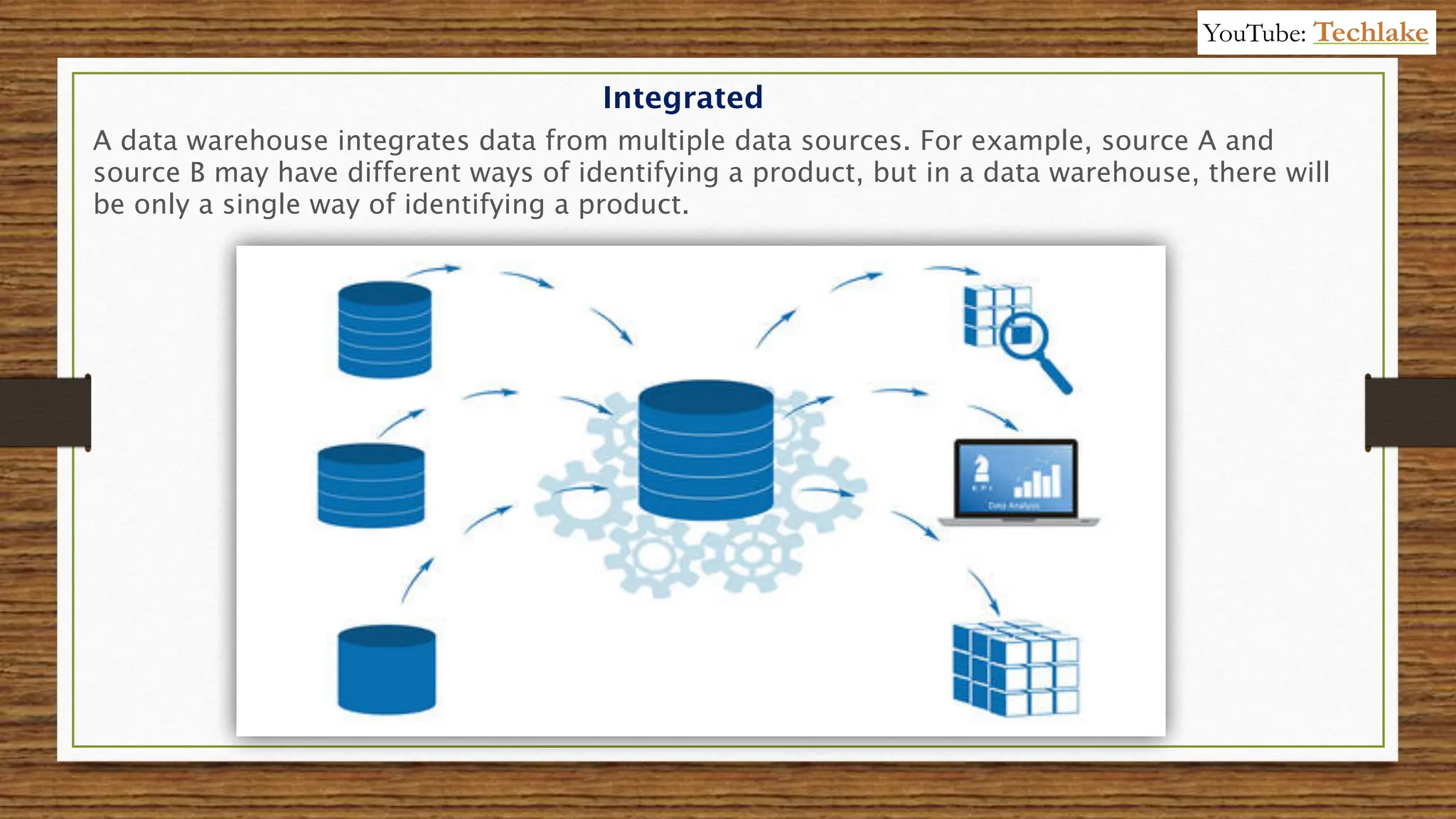
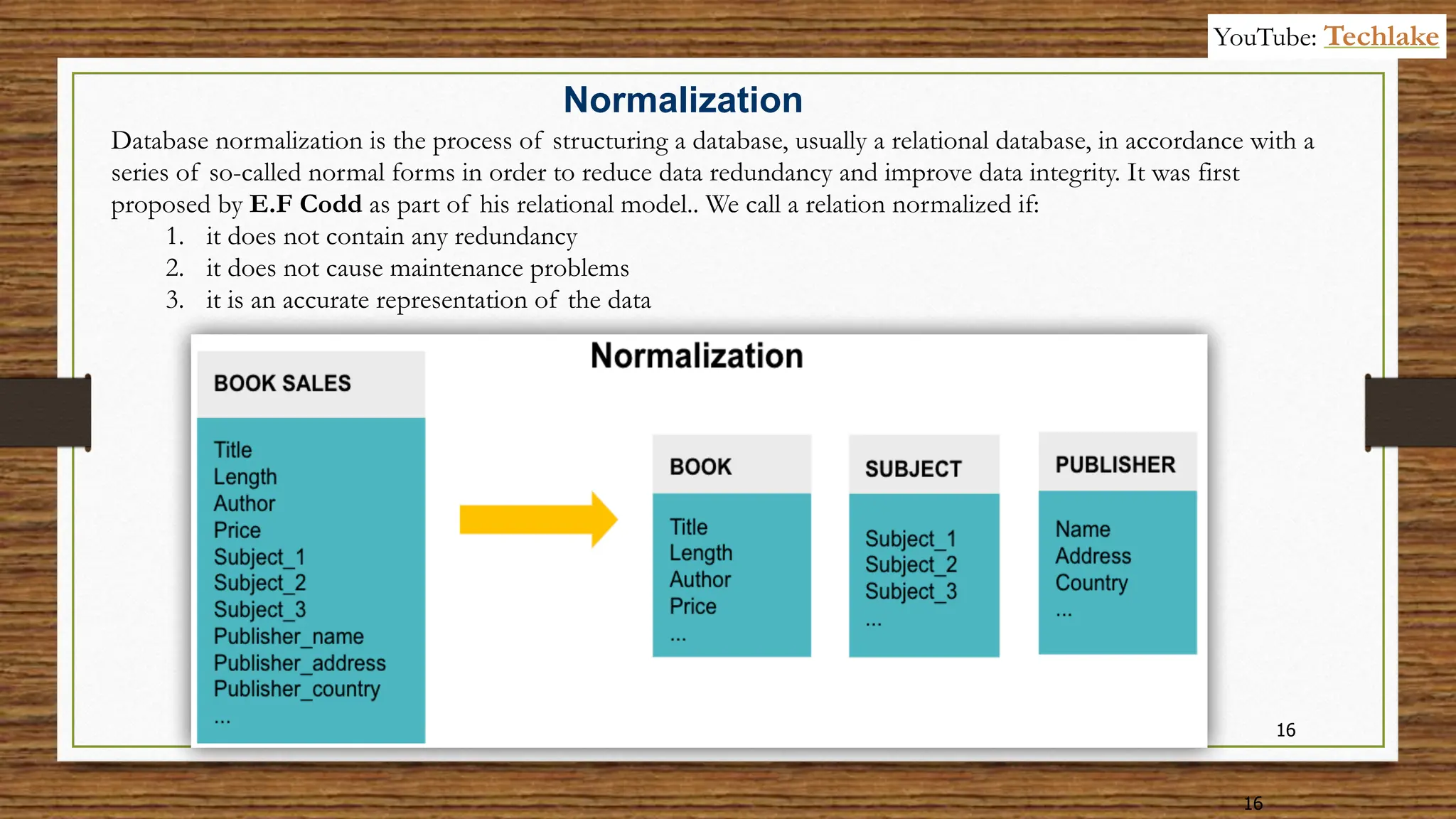
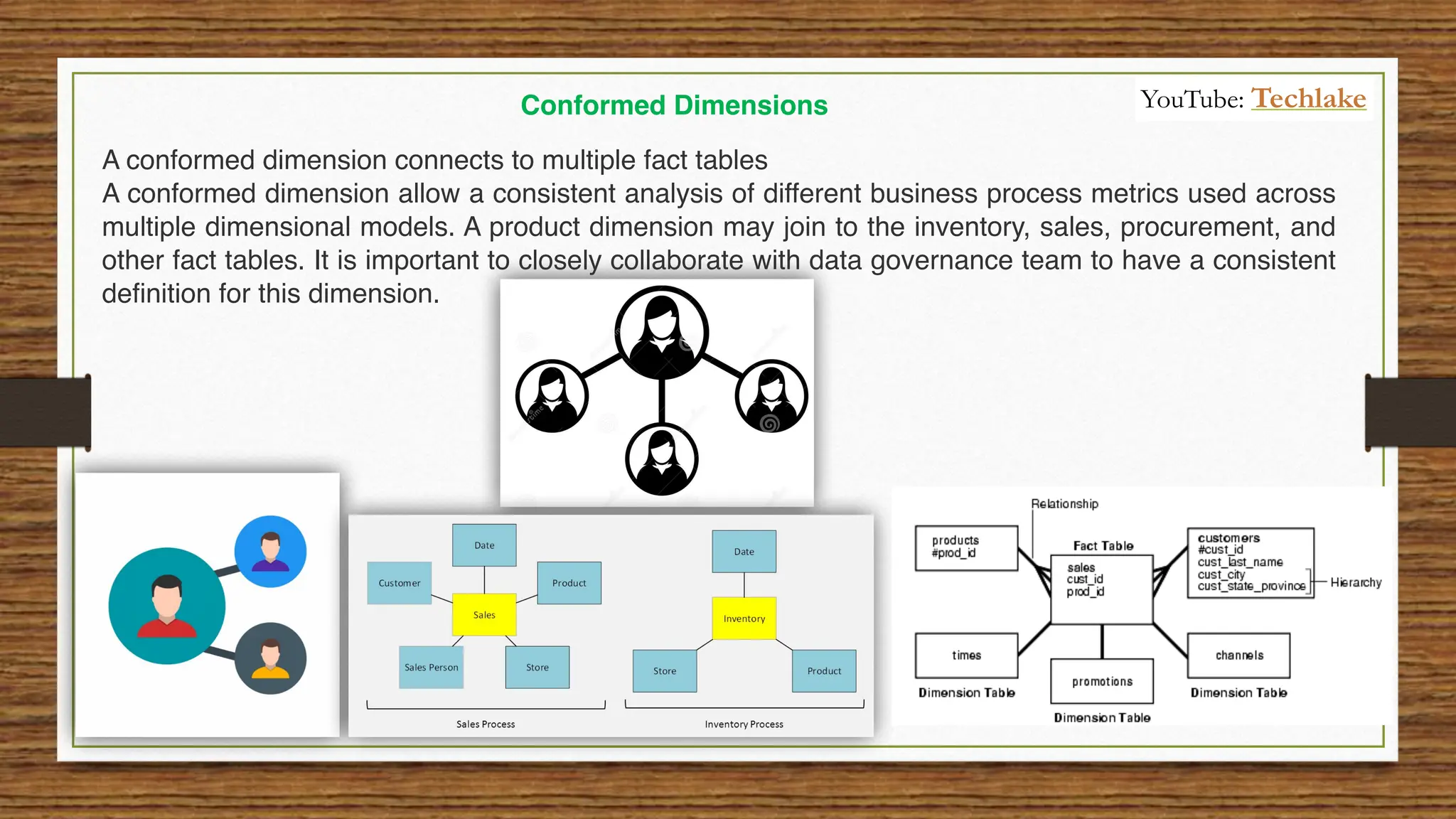
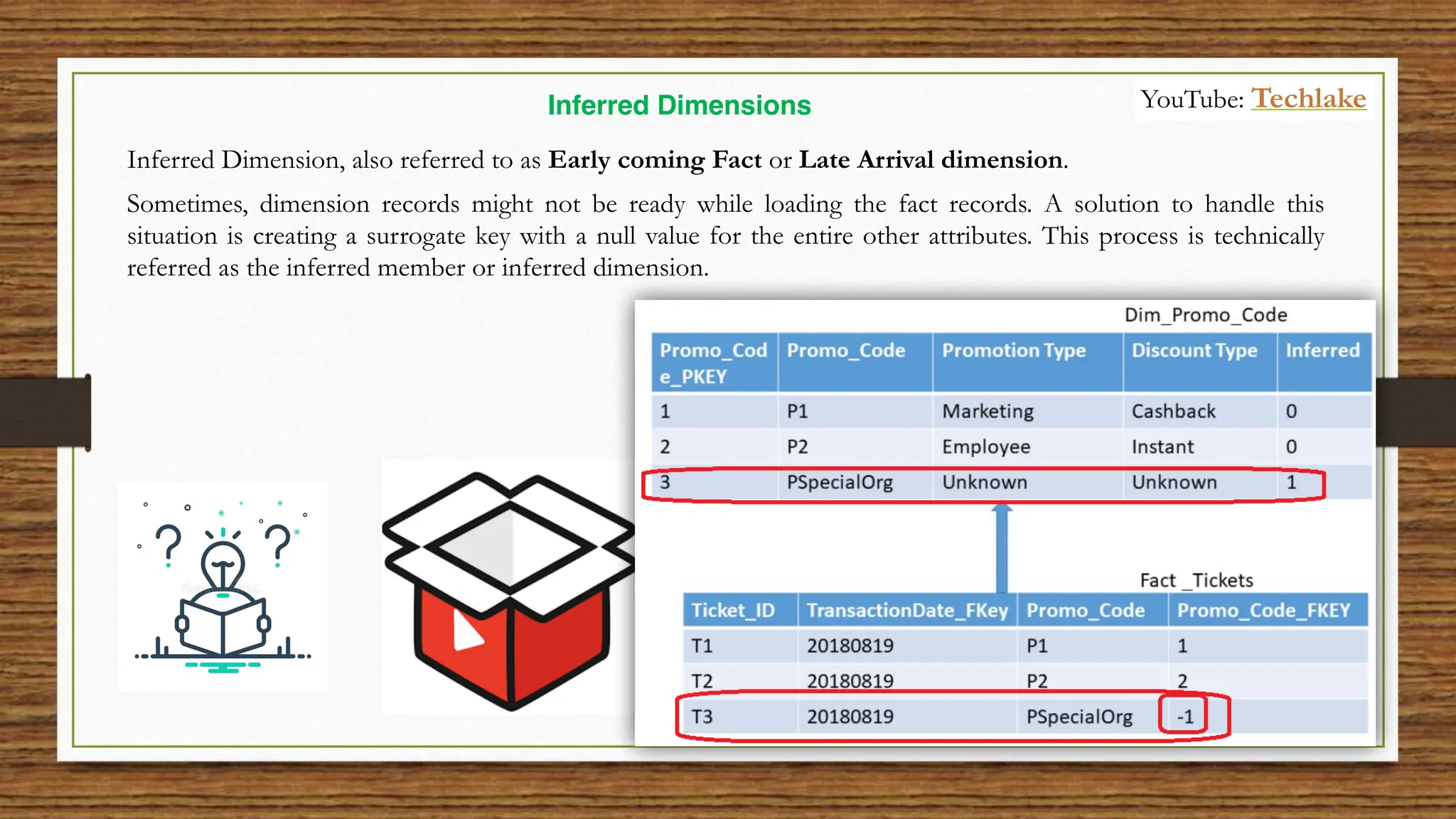
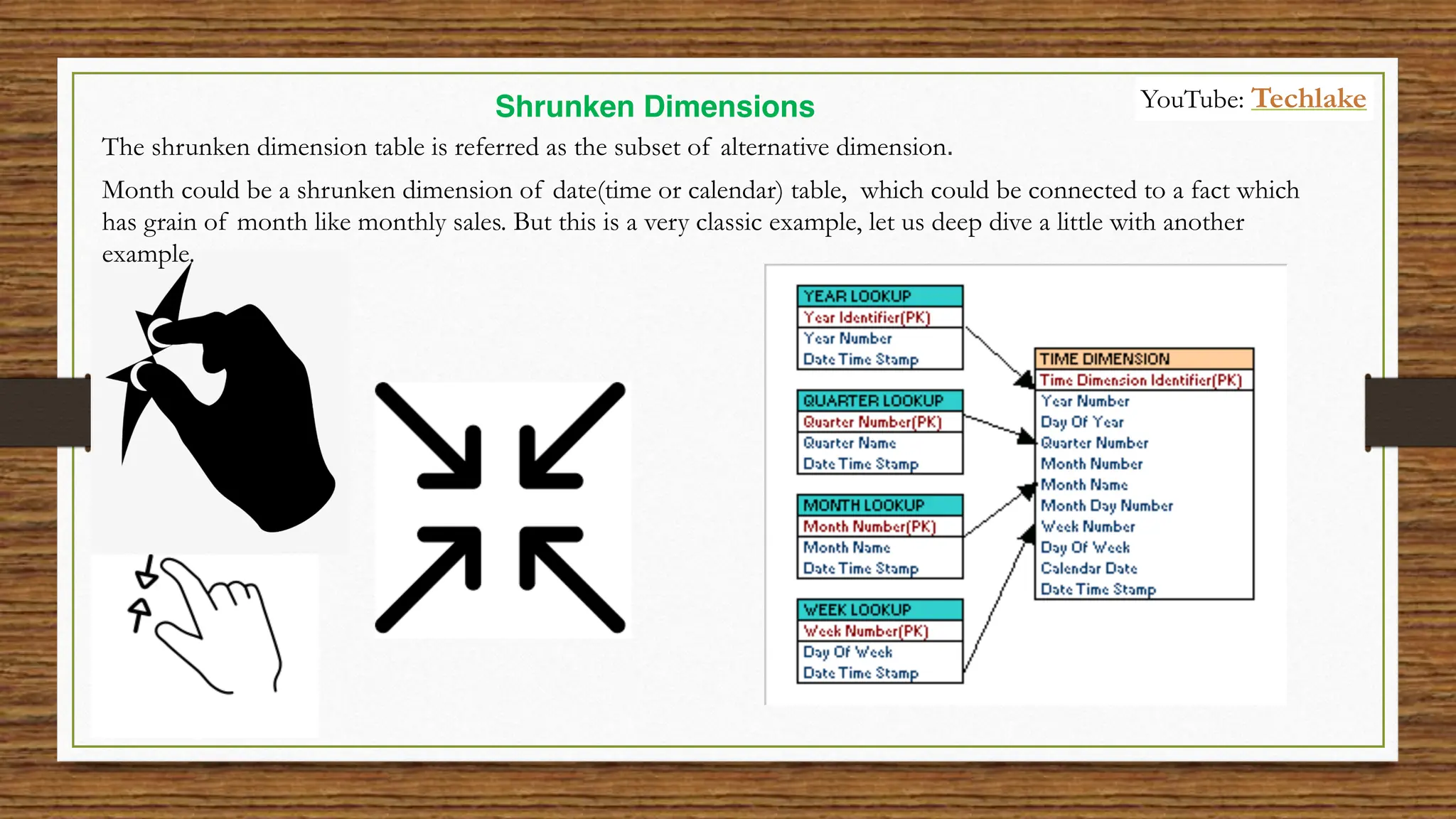
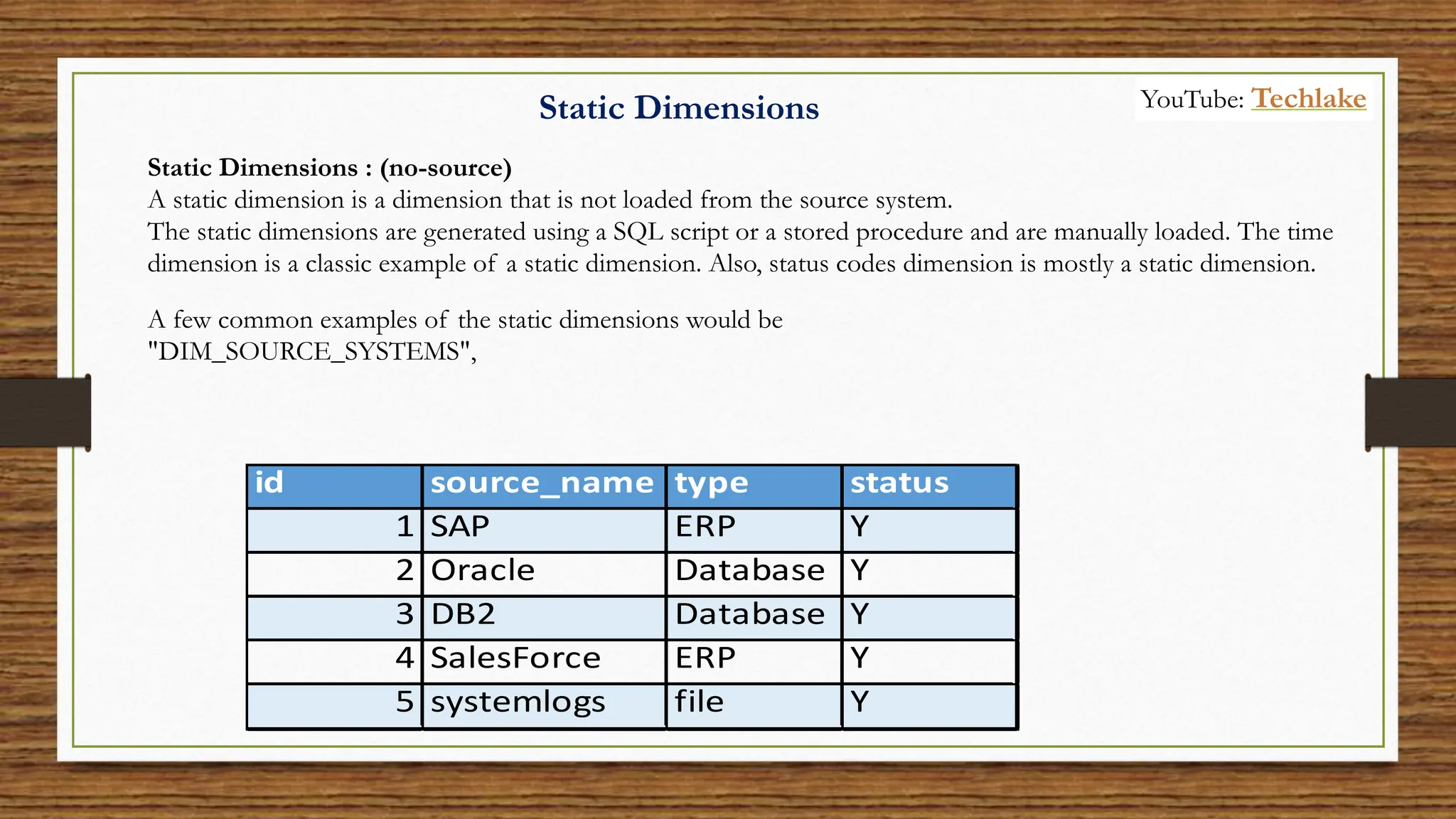
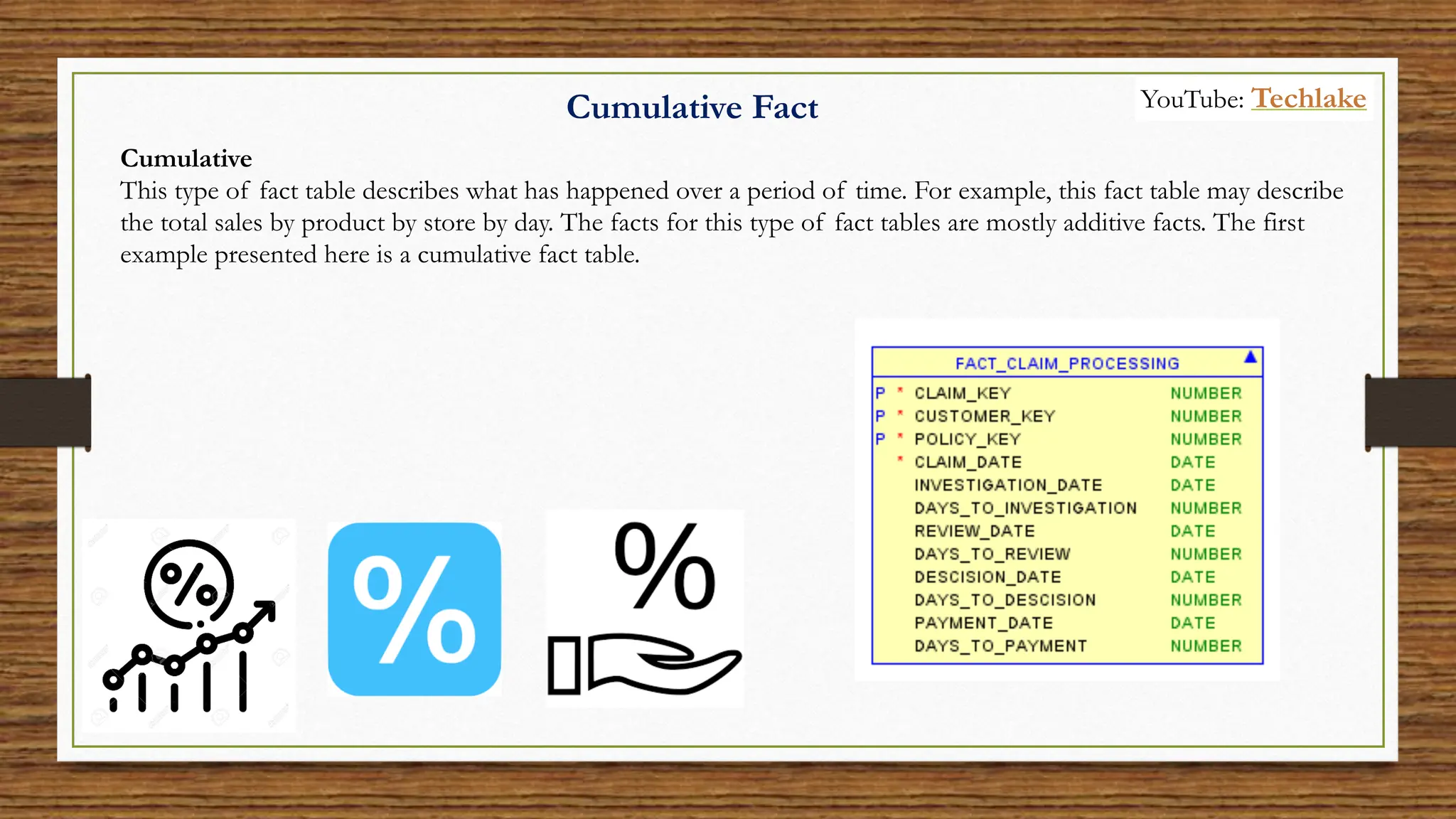
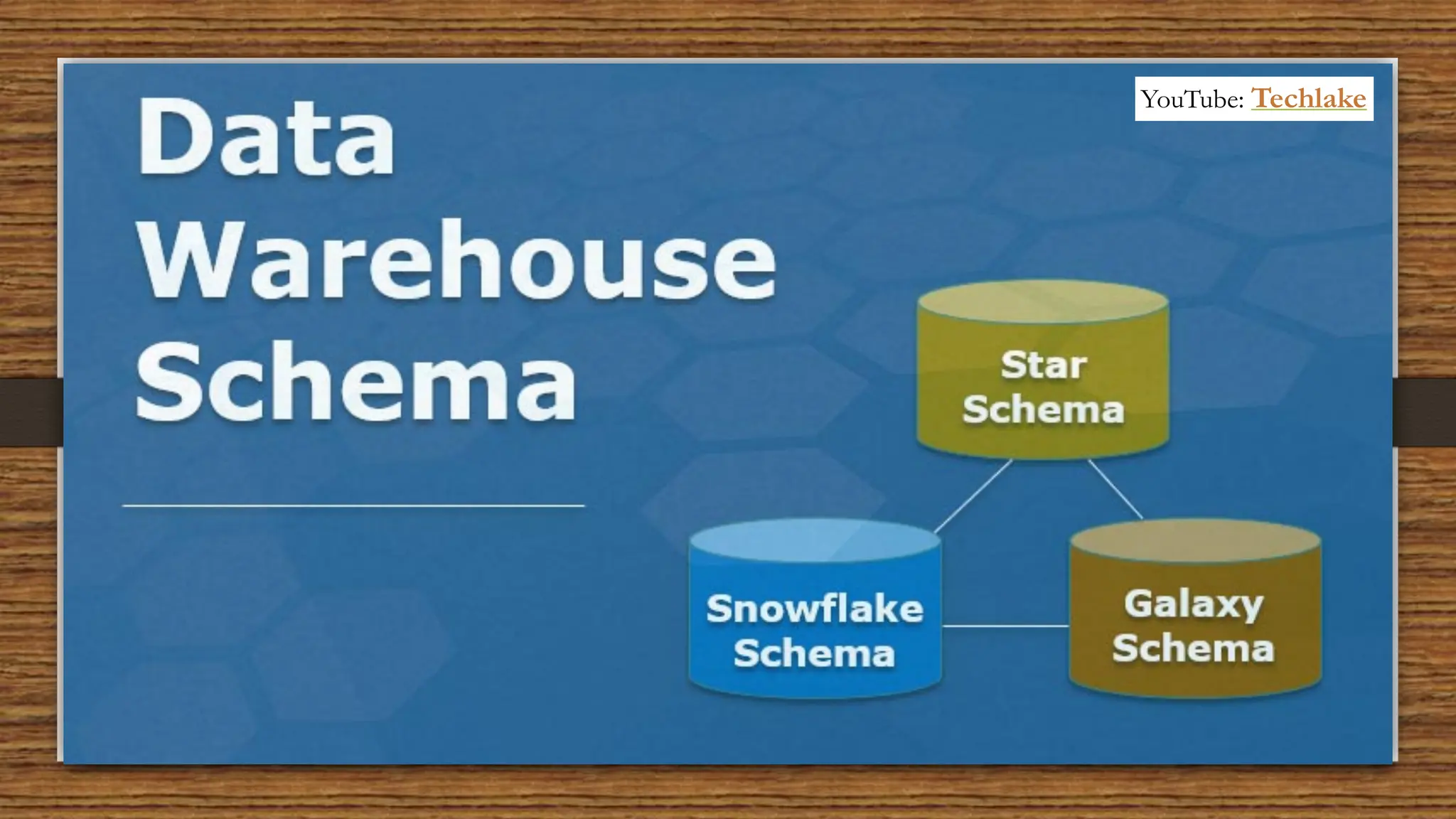
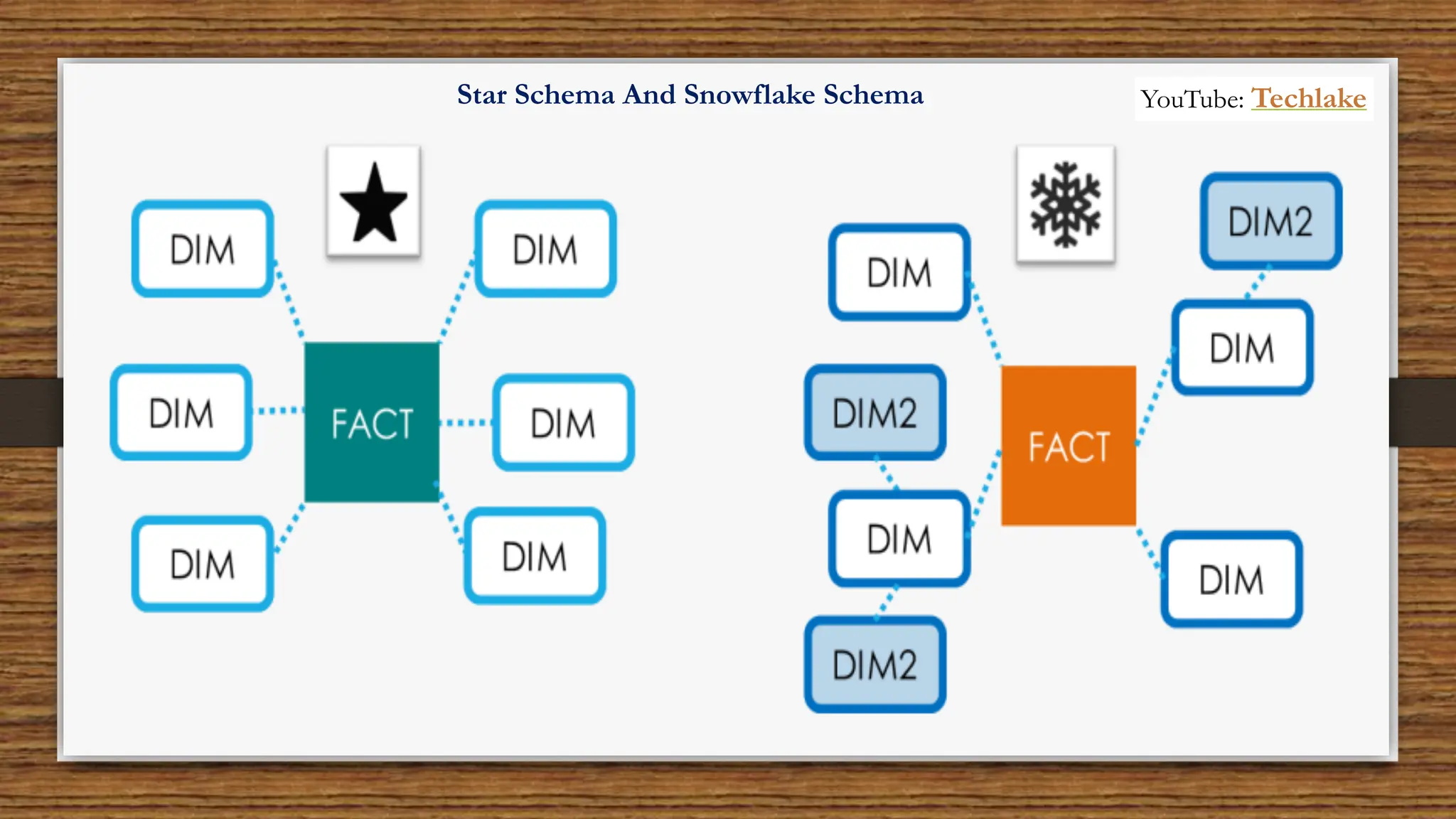
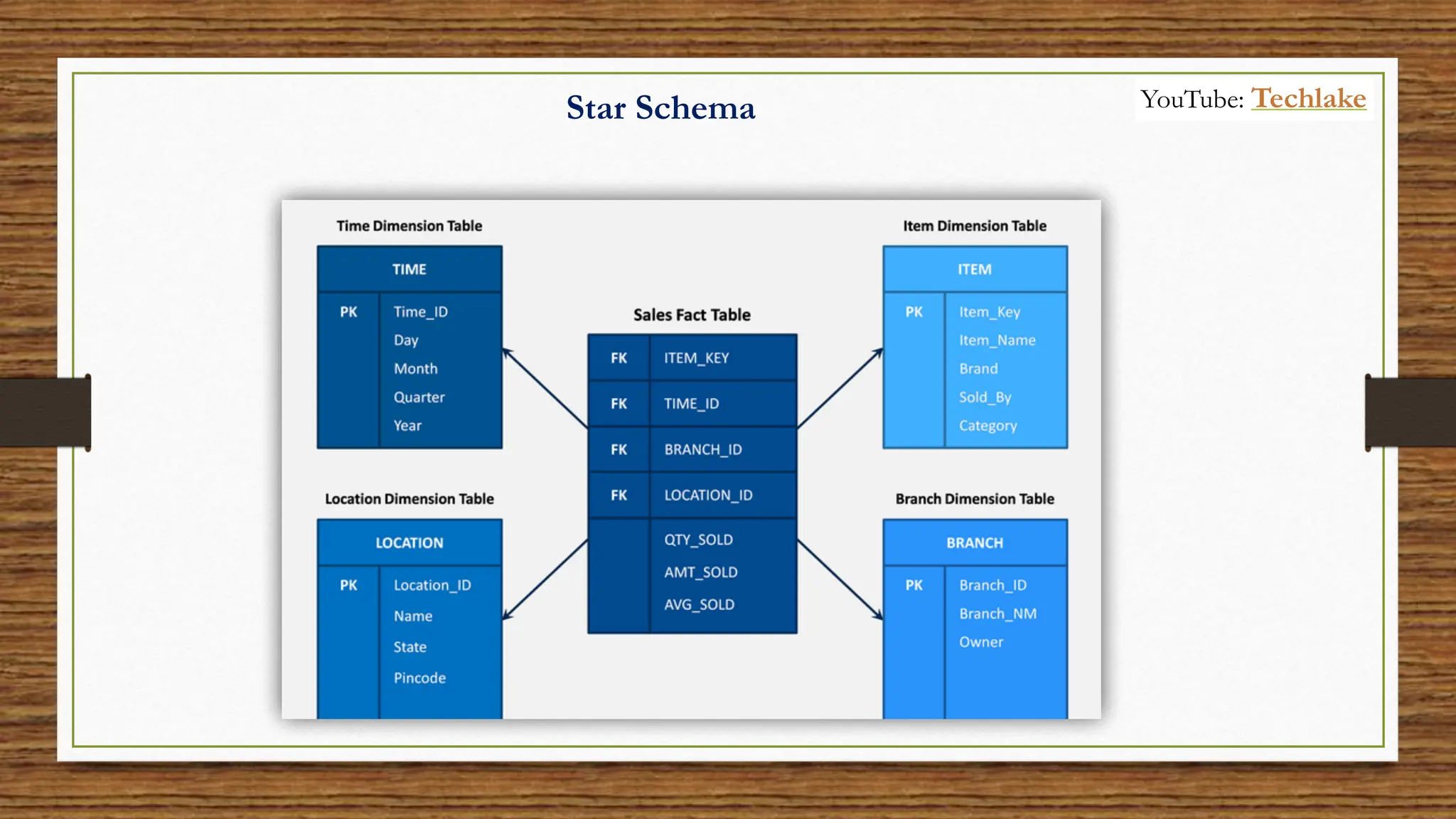
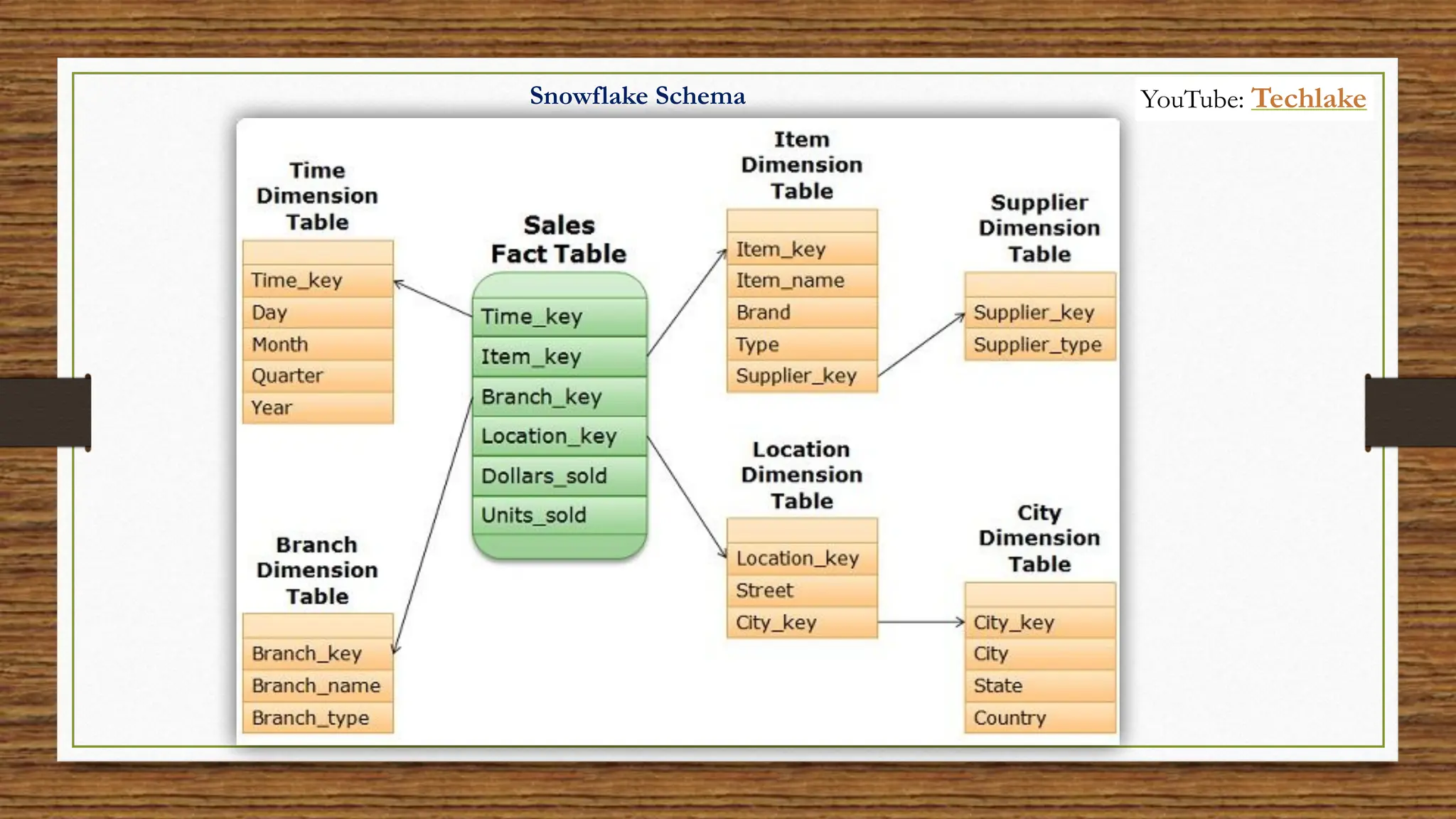
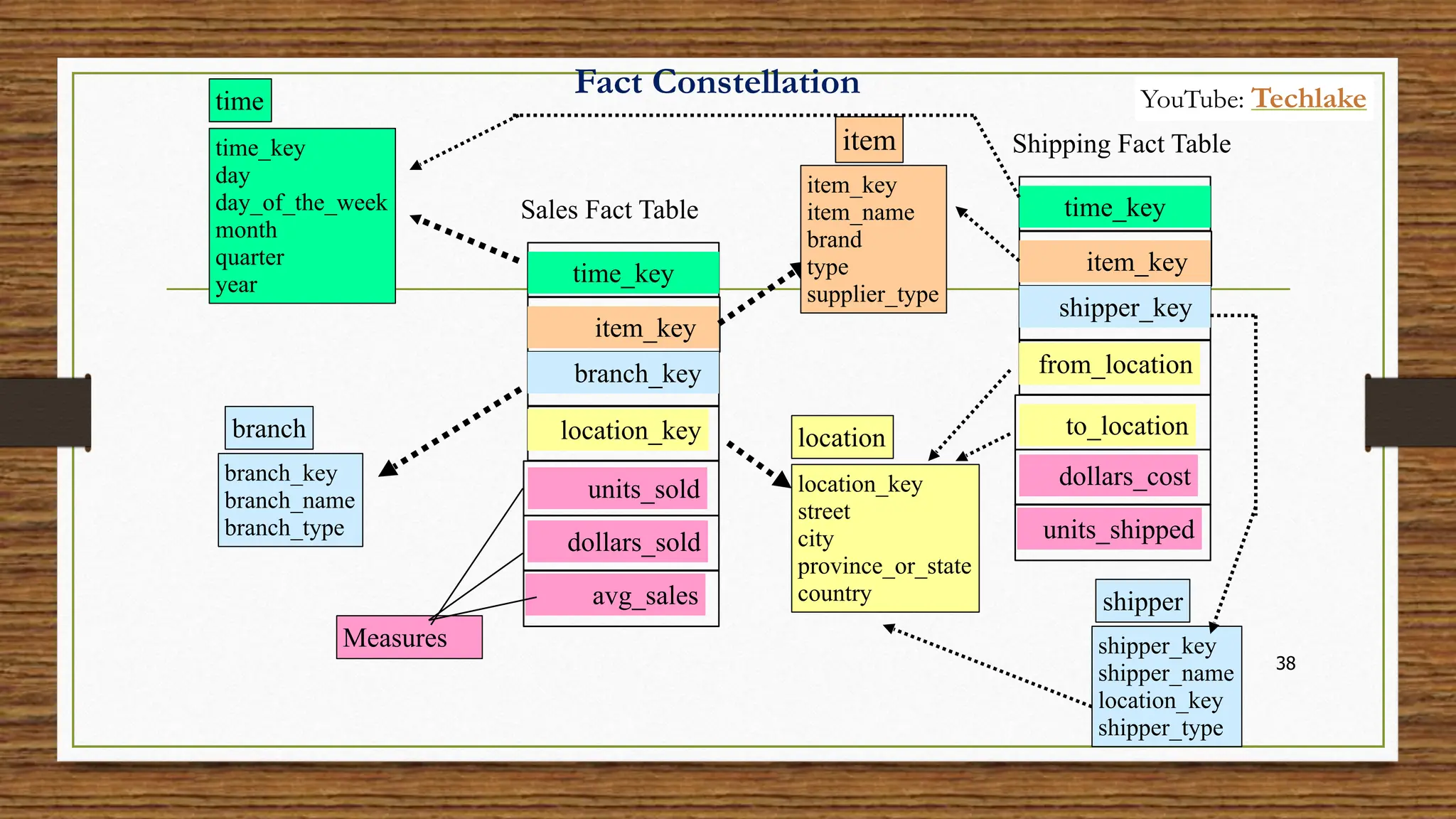
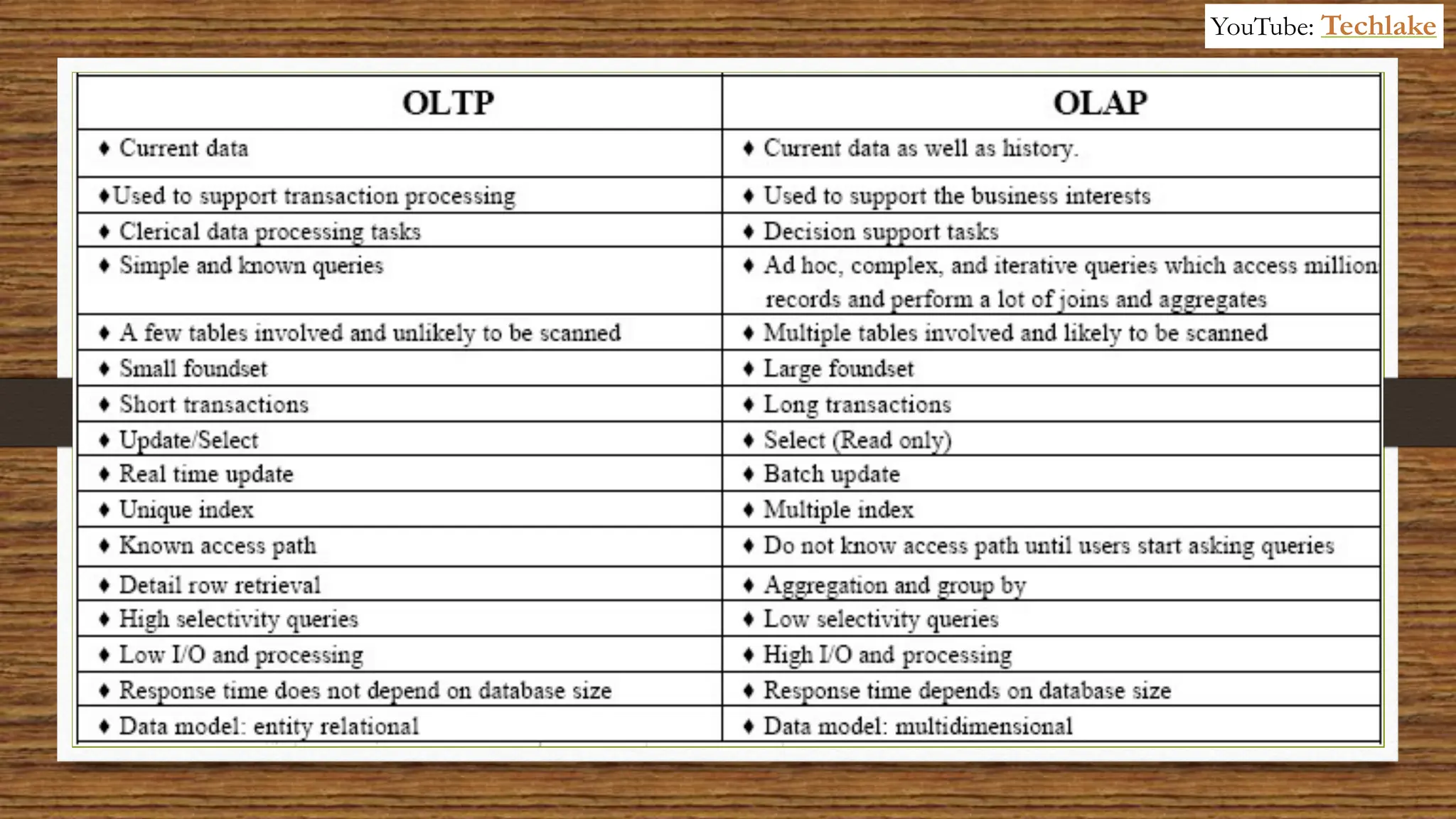
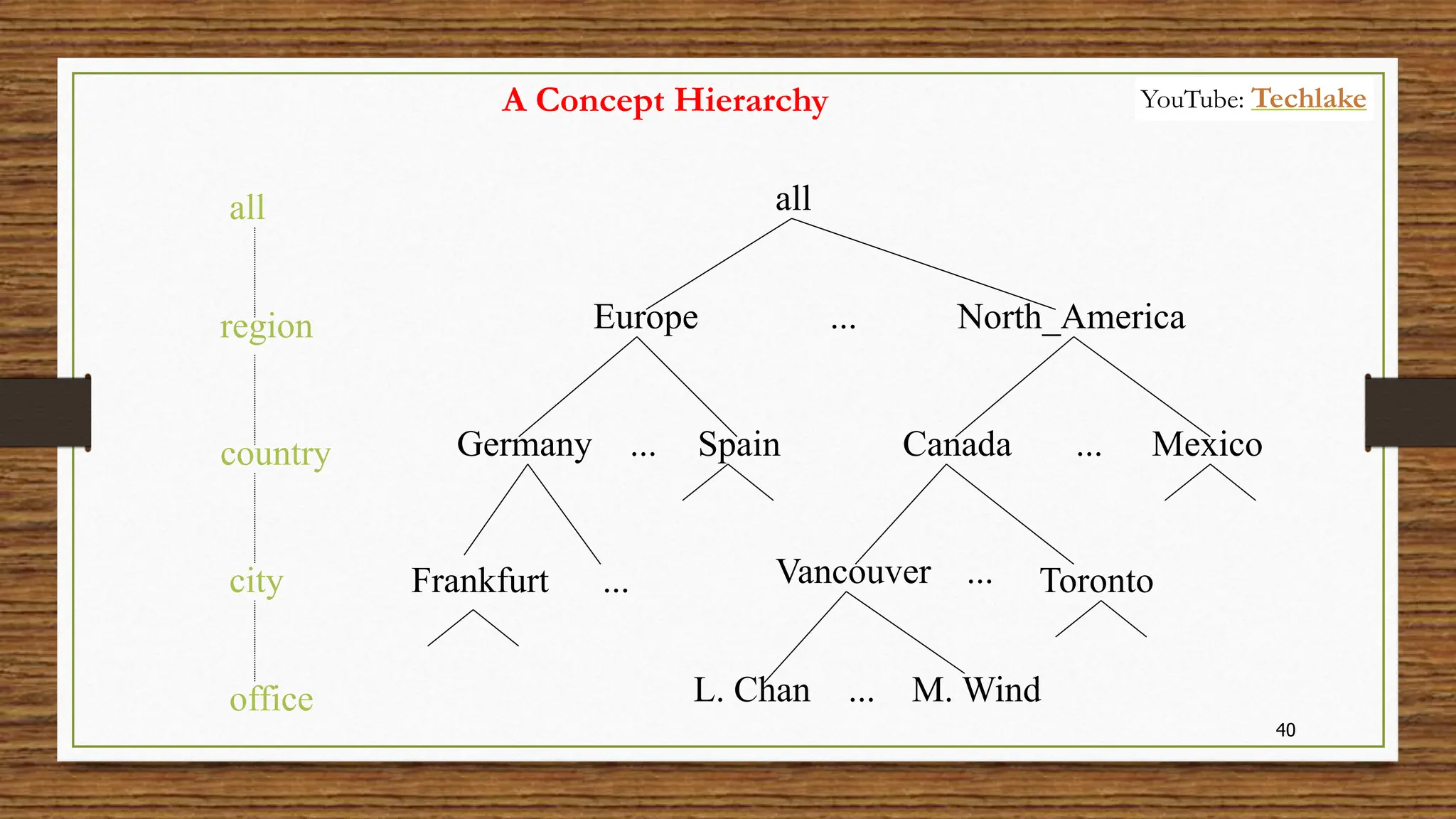
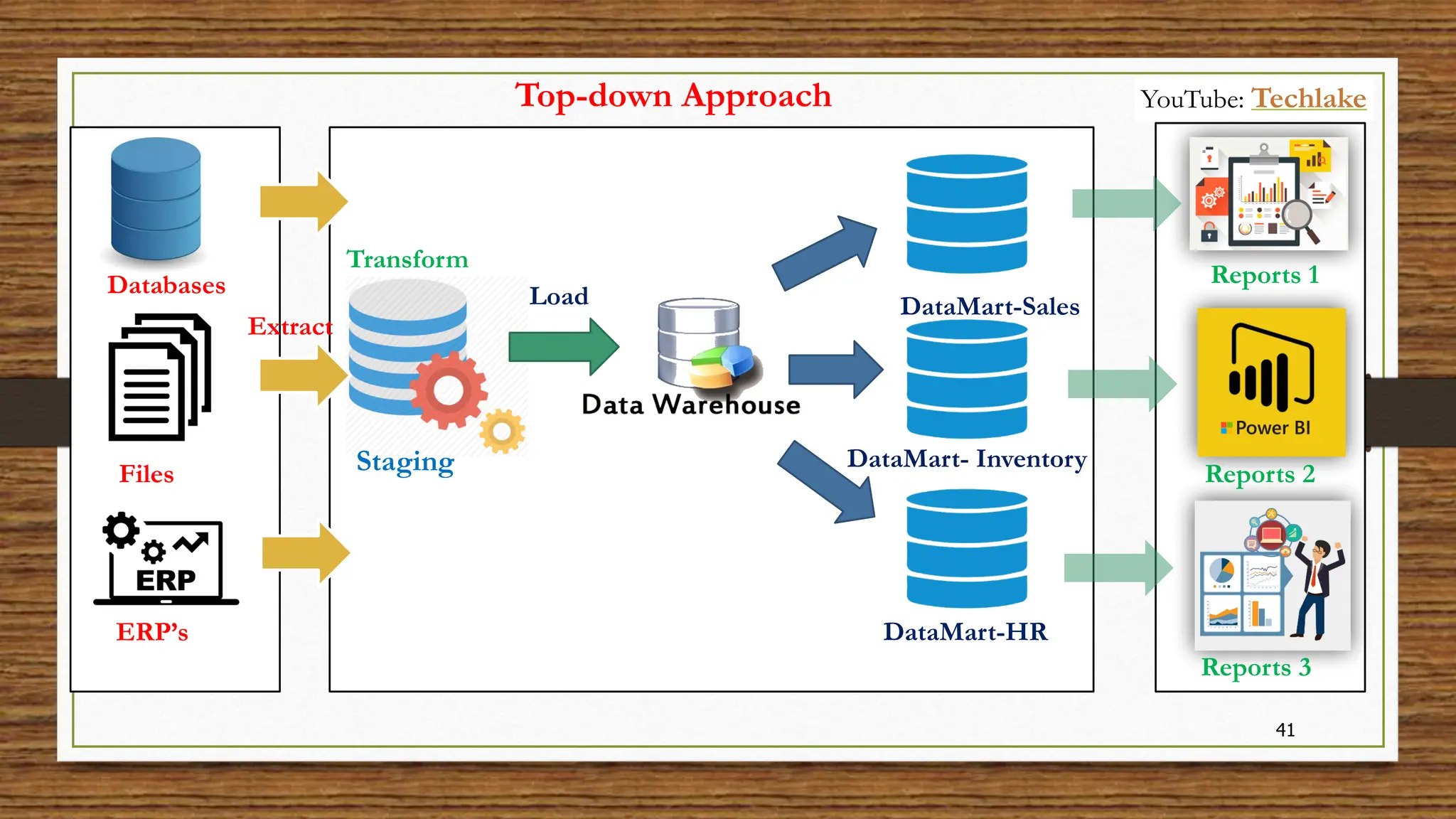
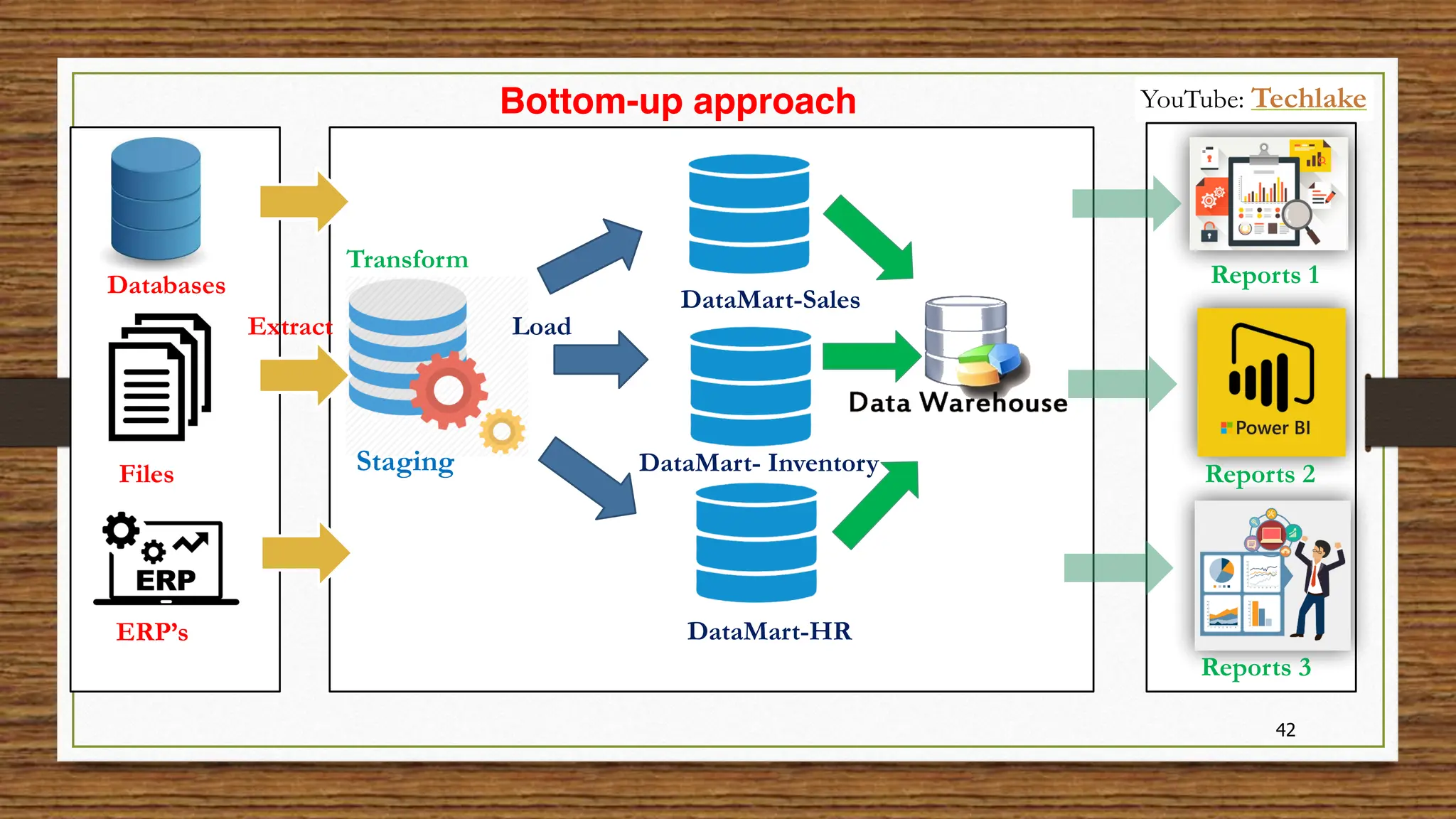
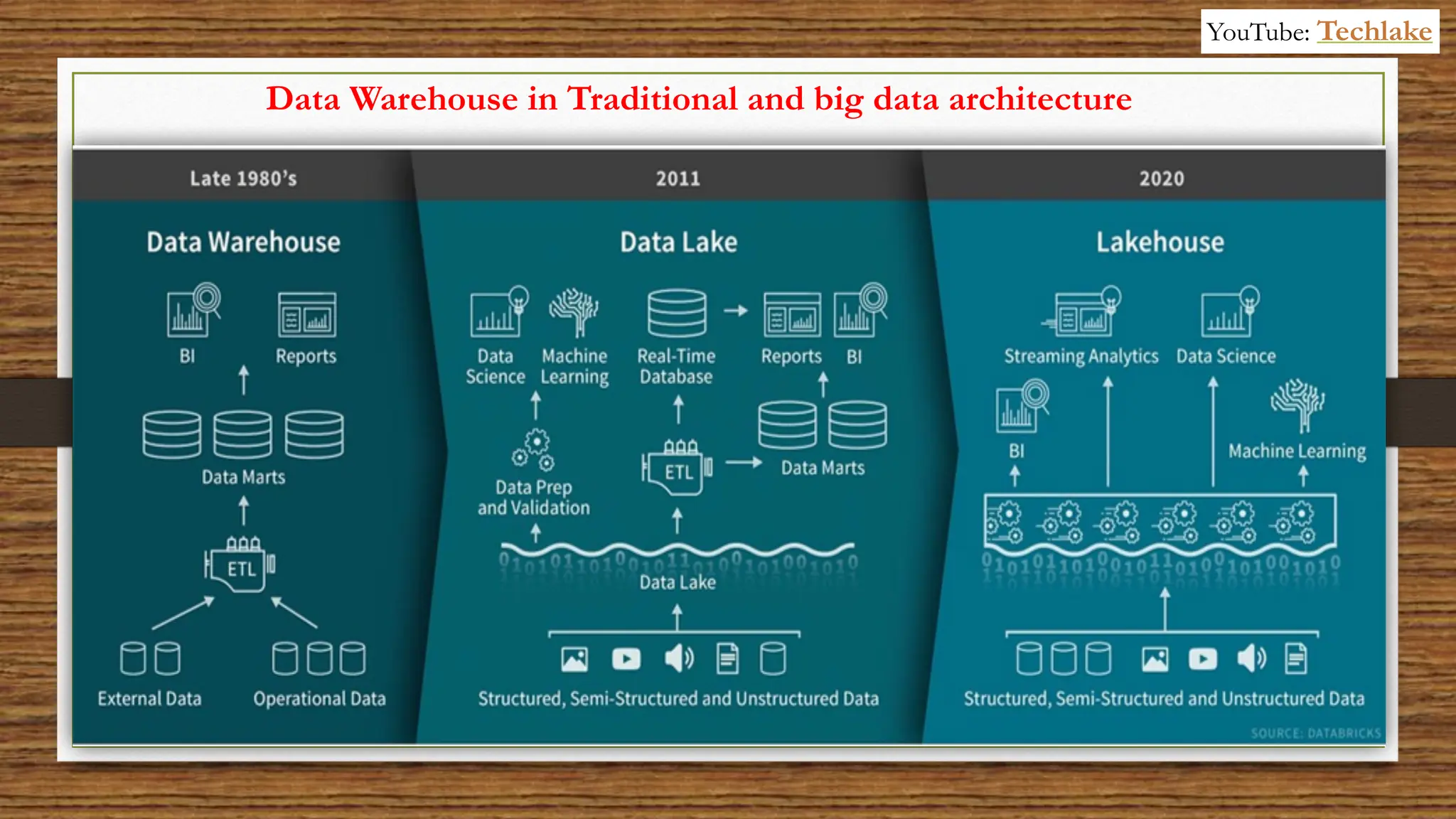
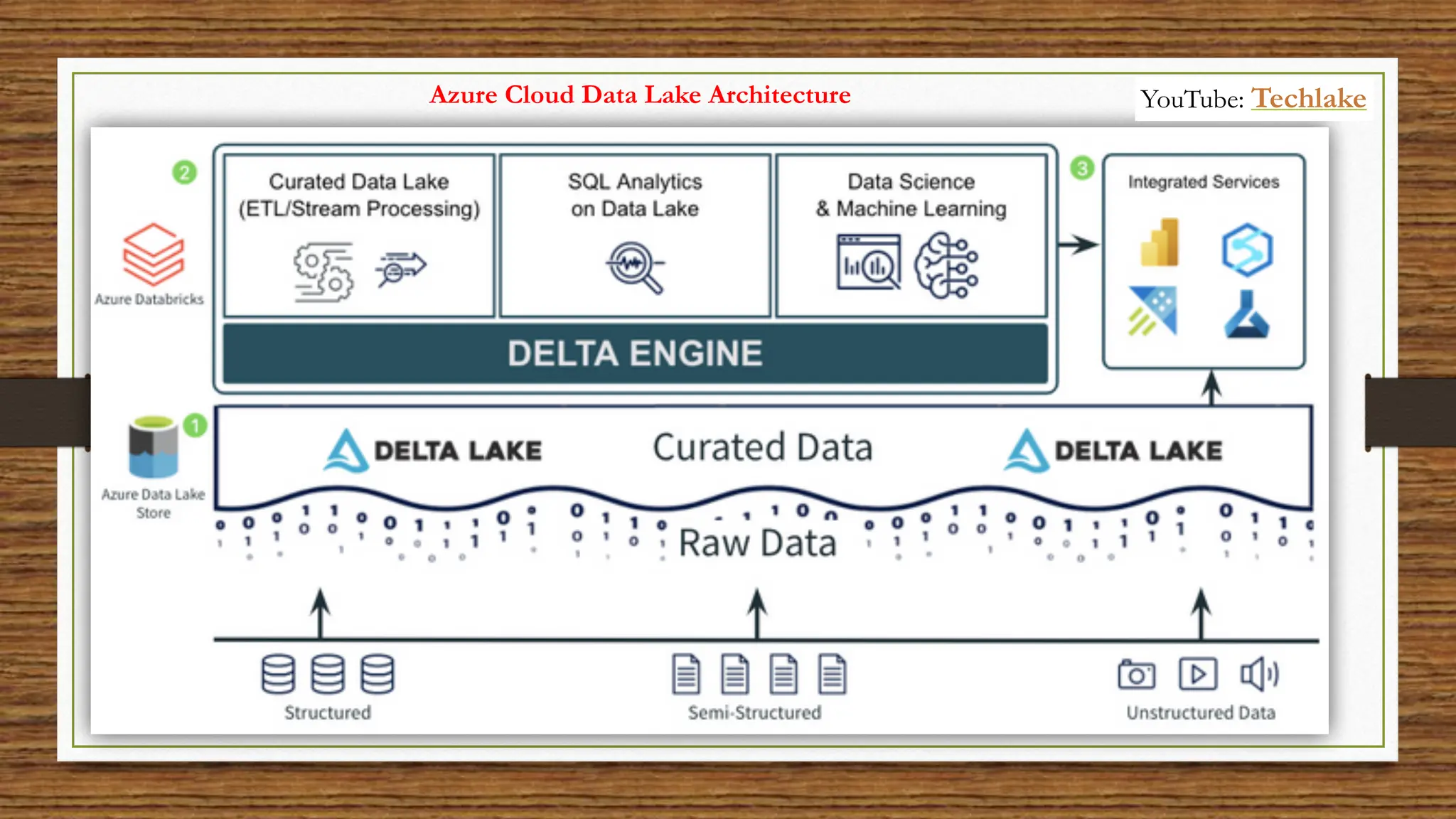
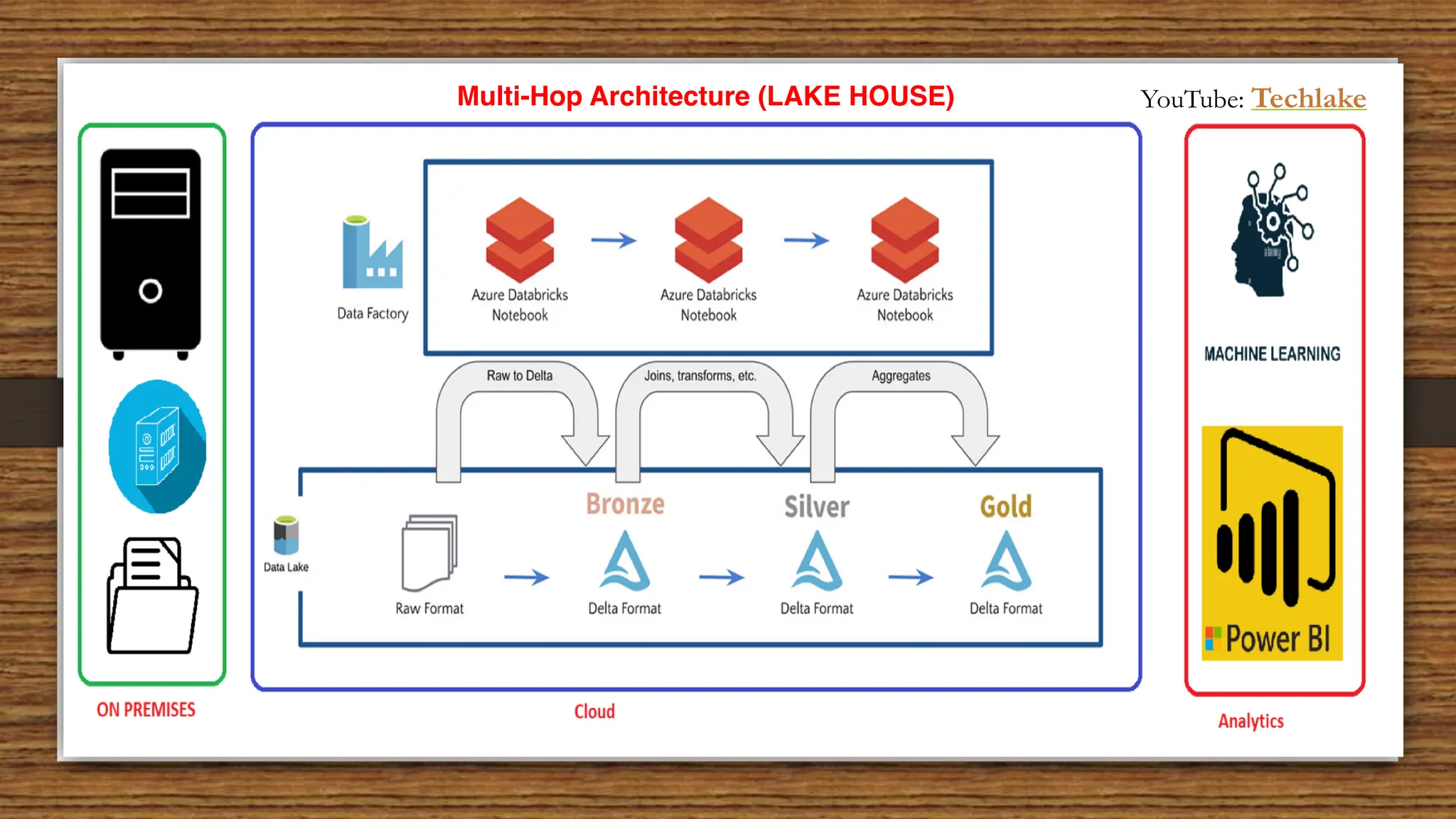
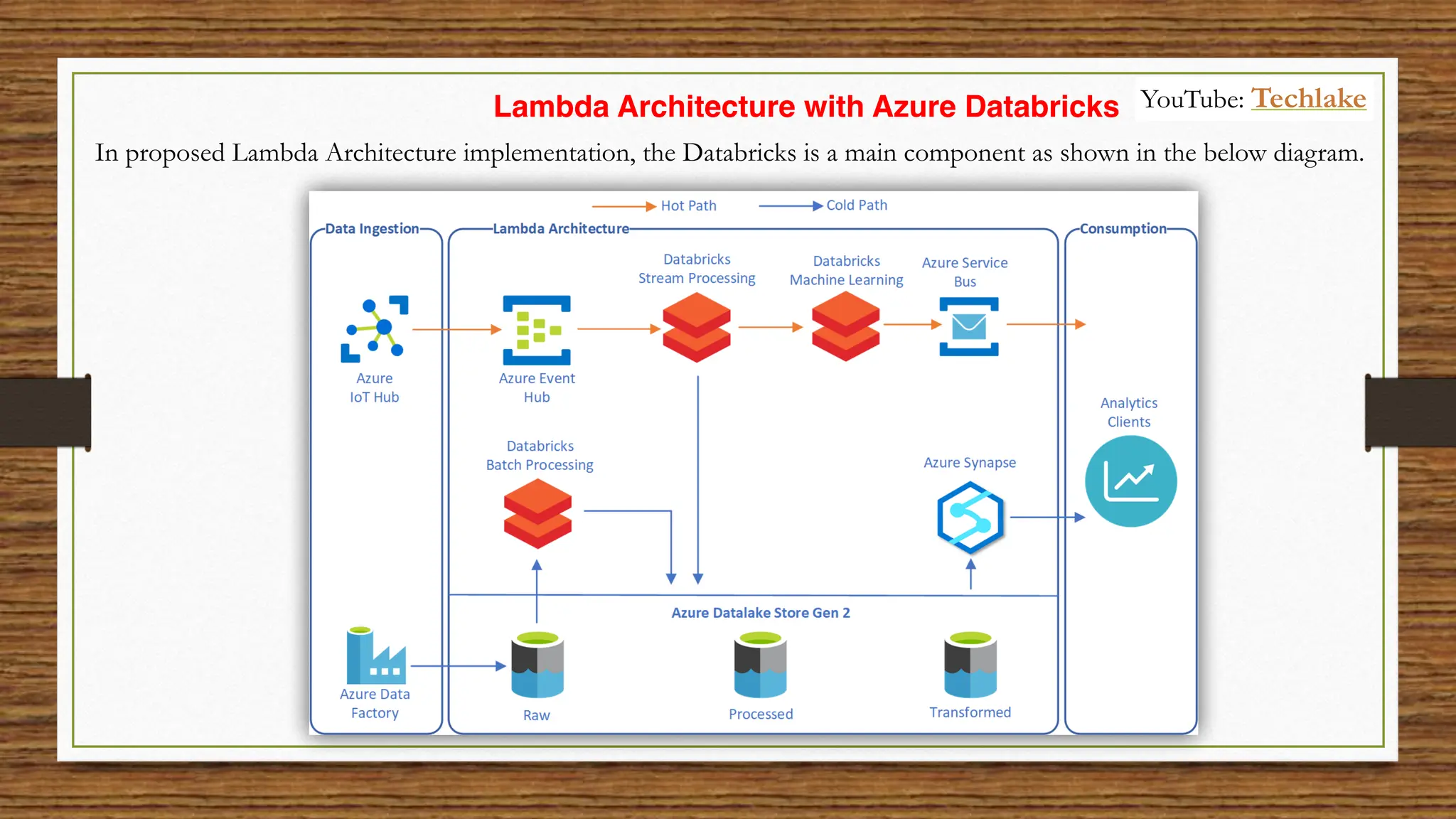
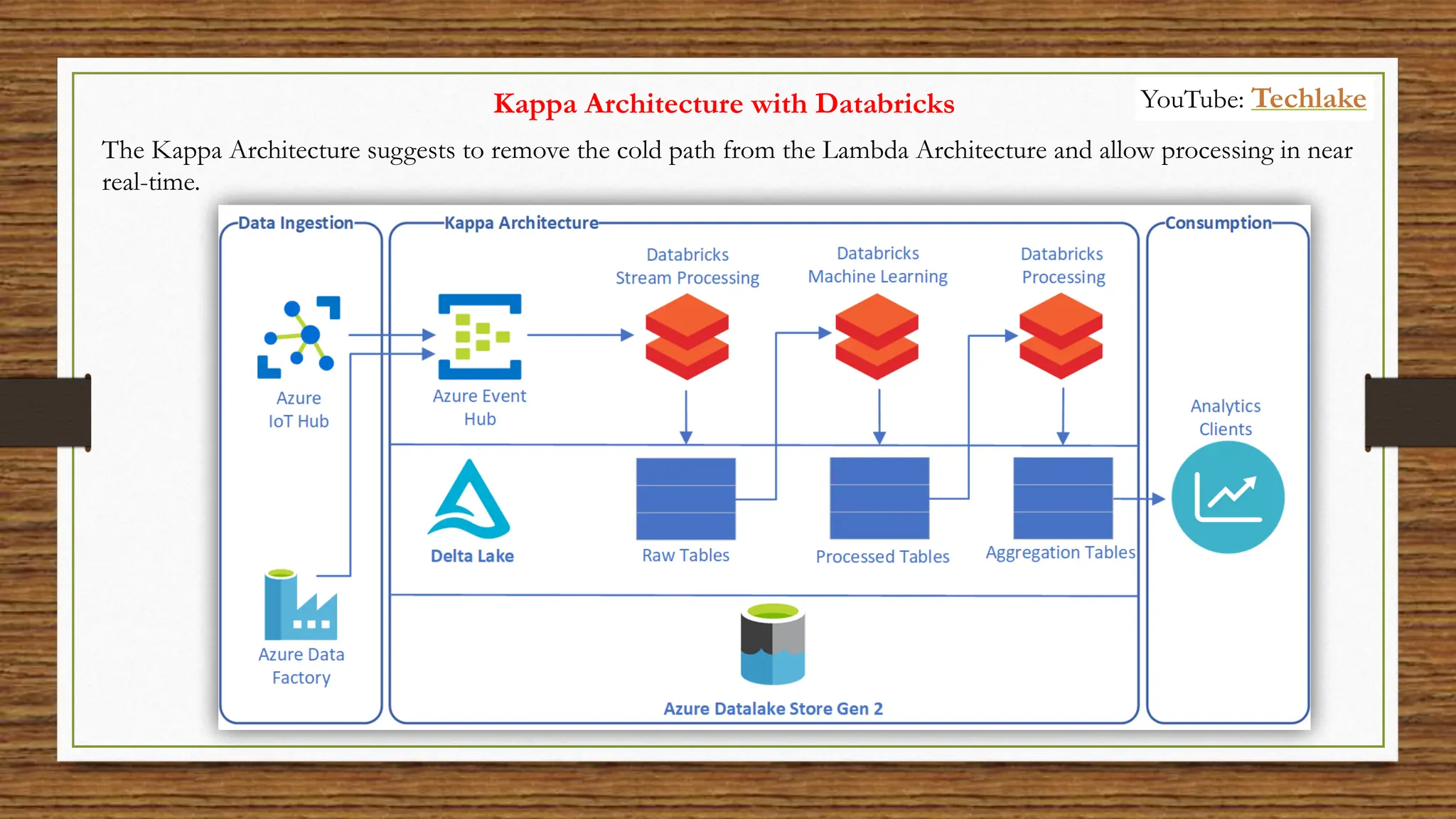
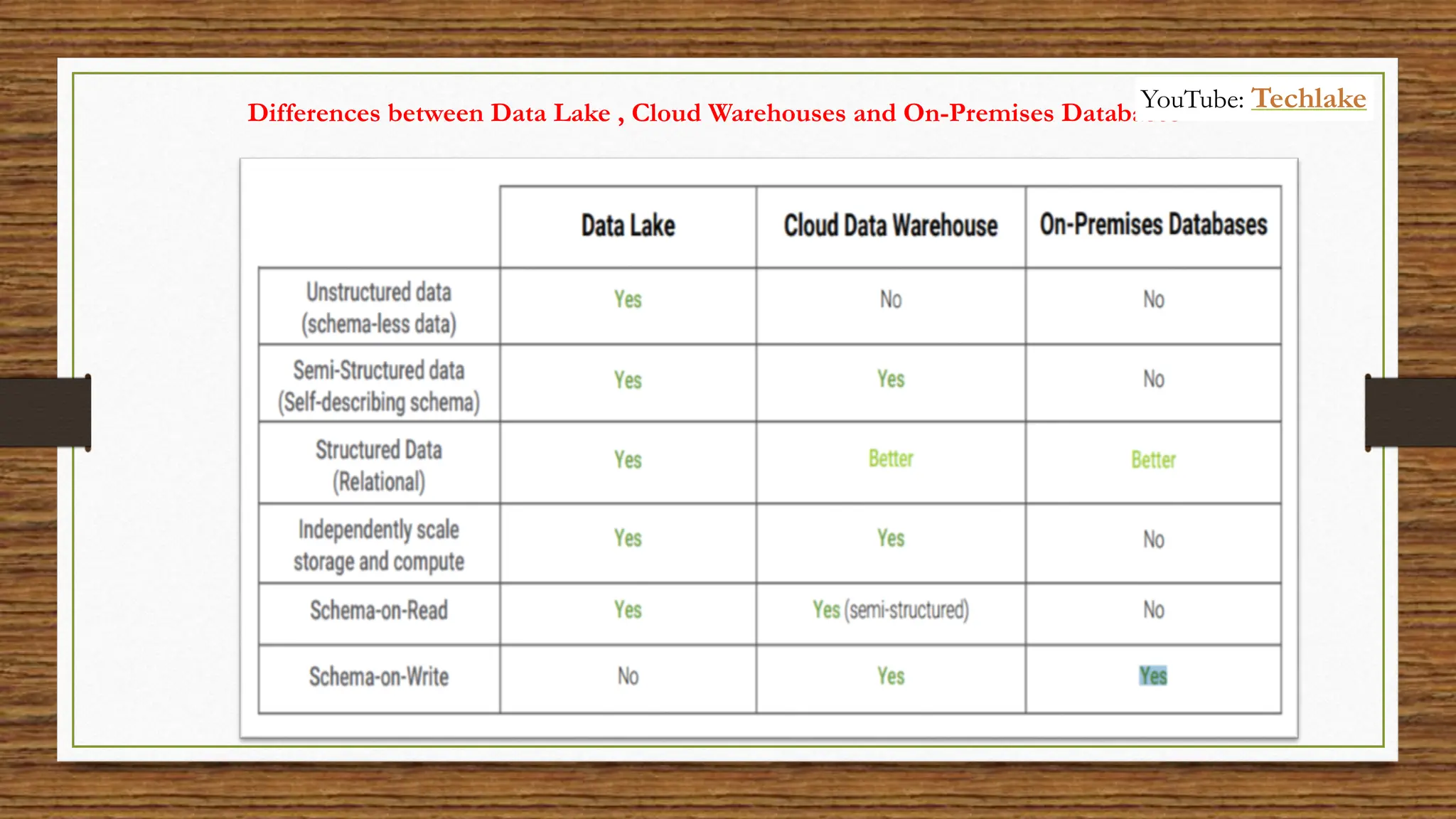
The document provides an in-depth exploration of data migration concepts, differentiating between OLTP and OLAP systems, as well as defining data warehouses and their components such as fact and dimension tables. It discusses database normalization and denormalization techniques, as well as various types of dimensions and facts utilized in data warehousing. Finally, it touches on architectural approaches for data processing including star and snowflake schemas, along with distinctions between data lakes and traditional databases.