Downloaded 81 times
















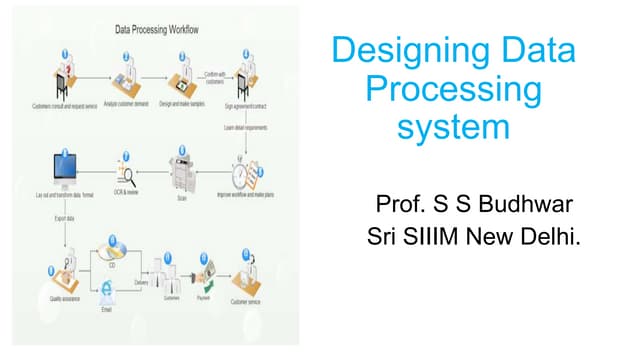
Data processing involves several key steps: 1) Data capture and collection 2) Data storage 3) Data conversion to a usable format 4) Data cleaning and validation 5) Data analysis including patterns, relationships, and groupings There are different types of data processing including scientific, commercial, automatic/manual, batch, and real-time. The type used depends on factors like the data domain and needed speed and accuracy of analysis. Proper data processing is important for obtaining reliable results.