Downloaded 20 times








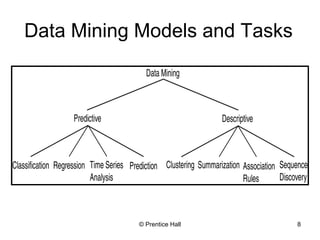
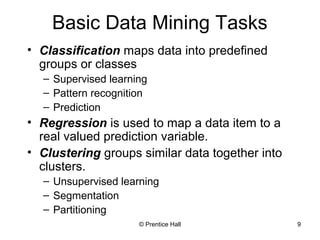

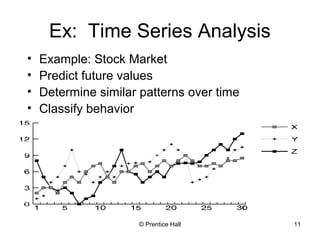

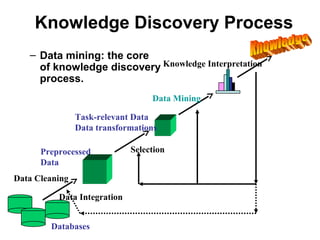
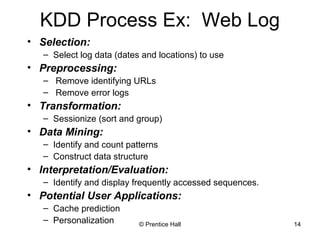
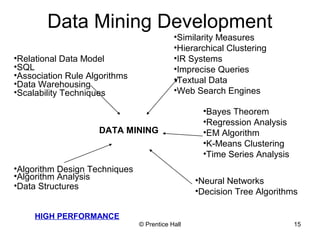
















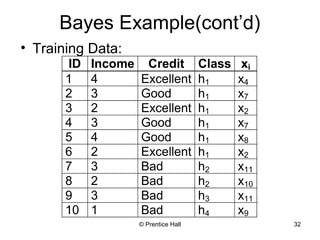









This document provides an overview and introduction to the course CIS 674 Introduction to Data Mining. It defines data mining, outlines basic data mining tasks such as classification, clustering, and association rule mining. It also discusses the relationship between data mining and knowledge discovery in databases (KDD), and highlights some issues in data mining such as handling large datasets, high dimensionality, and interpretation of results.

































































