Downloaded 11 times







![10
A Query Filters Outbound Data
{$and:[{“name”:”buzz”},{“prefs”:{$exists:true}}]](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-10-320.jpg)
![11
How About Using It To Filter Inbounds?
{$and:[{“name”:”buzz”},{“prefs”:{$exists:true}}]}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-11-320.jpg)
![12
$exists And $type Already in MQL
{“name”:{$type:2}}
{$or:[{“age”:{$exists:false}}, {“age”:{$type:16}} ]}
{$and: [
{$name: {$type:2}},
{$or:[
{$and:[{"weight”:{$type:16}}, {"height":{$type:16}}]}
,{$and:[{"weight”:{$exists:0}}, {"height":{$exists:0}}]}
]}
])
Ensure “name” exists (because not null) and is a string:
“age” optional but if exists must be a 32bit integer:
“name” required as string and weight and height both
required integers or both not present:](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-12-320.jpg)
![13
… And MQL Goes Way Beyond…
{$or:[
{$and:[
{“name”: {$type:2}},
{“numClues”: {$gt: 0}}, {“numClues”:{$type:16}},
{“birthday”: {$type: 9}},
{“hiredate”: {$type: 9}},
{$or: [{“prefs”:{$exists:false}},
{“prefs”:{$type:3}} ]
}
]
},
{“name”: {$exists:false}}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-13-320.jpg)

![16
Code For The Future…Today
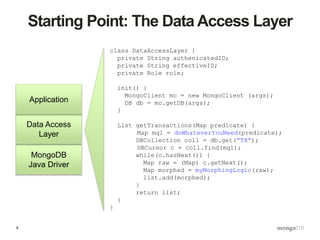
class DataAccessLayer {
someWriteOperation(Map data) {
if(ValidationEnabledInMongoDBengine) {
collection.insert(data); // Not yet
} else {
Map mql = getMQL(); // we’ll see this shortly!
// {$or:[{“age”:{$exists:false}},
// {“age”:{$type:16}}]}
ValidationResult vr = MQLValidator.validate(mql,data);
if(vr.ok()) {
collection.insert(data);
}
}
}
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-16-320.jpg)
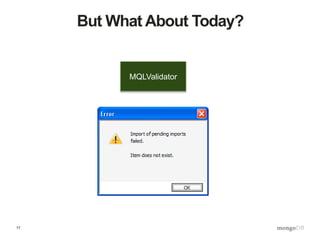

![19
Bridge MQL to PQL
class MQLValidator {
private PQLFilter pqlfilter;
validate(Map mql, Map data) {
boolean rc;
if(MQLValidationAvailableAsLibrary) {
rc = ActualMongoDBMQL.validate(mql, data);
} else {
Map pqlfilter = convertMQLtoPQL(mql);
// {or:[{“null”: “age”},
// {“type”: {“age”: “INT”}}]}
rc = pqlfilter.eval(pql, data);
}
return rc;
}
Map convertMQLtoPQL(Map mql) { // ~200 lines }
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-19-320.jpg)

![21
MQL Is Easy To Navigate
{$or:[
{$and:[
{“name”: {$type:2}},
{“numClues”: {$gt: 0}}, {“numClues”:{$type:16}},
{“birthday”: {$type: 9}},
{“hiredate”: {$type: 9}},
{$or: [{“prefs”:{$exists:false}},
{“prefs”:{$type:3}} ]
}
]
},
{“name”: {$exists:false}}
]
}
• “Walk”, not “parse”
• Operators distinct from operands
• Operands are native type (e.g. Date)](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-21-320.jpg)

![23
The Validations Collection
> db.validations.find()
{
“collectionName”: “product”,
“validations”: [
{ “name”: “simple”, “type”: “MQL”, “expr”:
{__$or:[{“age”:{__$exists:false}},
{“age”:{__$type:16}} ]}
]
}
{
“collectionName”: “transaction”,
“validations”: [
{ “name”: “frontOffice”, “type”: “MQL”, “expr”:
{ … lots of MQL here …}
}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-23-320.jpg)
![24
Various “Levels” of Validation
> db.validations.find()
{
“collectionName”: “foo”,
“defaultValidation”: “initialSetup”,
“validations”: [
{“name”: “initialSetup”, …},
{“name”: “frontOffice”, …},
{“name”: “middleOffice”, …},
{“name”: “backOffice”, …}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-24-320.jpg)
![25
Multiple Types: Schema By Example
> db.validations.find()
{
“collectionName”: “foo”,
“validations”: [
{ “name”: “simple”,
“type”: “SBE”,
“expr”:
{ “name!”: “string”,
“age”: “integer”,
“petNames”: [ “string” ],
“bday!”: “date”
}
}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-25-320.jpg)
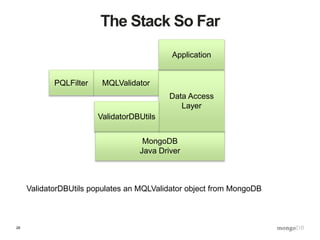


![29
Concept: Post Query Operations (PQO)
{ ssn: { $hash: model }, birthdate: null }
{$and:[{“name”:”buzz”},{“prefs”:{$exists:true}}]](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-29-320.jpg)

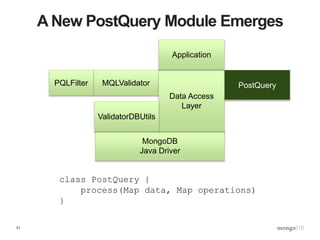

![33
The Postquery Collection
> db.postquery.find()
{
“collectionName”: “product”,
“operations”: [
{ “name”: “basicPI”, “type”: “PQO”, “expr”:
{“ssn”:null}
}
]
}
{
“collectionName”: “customerIndo”,
“operations”: [
{ “name”: “personalData”, “type”: “PQO”,
“expr”:
{ … lots of PQO here …}
}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-33-320.jpg)
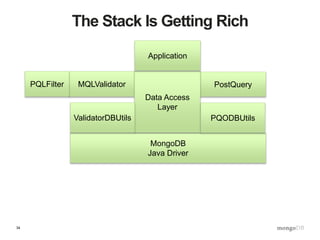

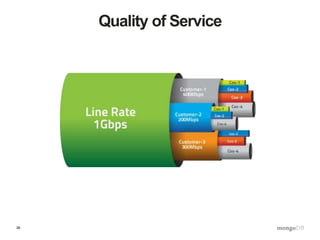


![39
The QOS Collection
> db.qos.find()
{
“collectionName”: “product”,
“qos”: [
{ “function”: “someReadOperation”,
“rule”: “std”,
“maxtime”: 250 },
{ “function”: “someReadOperation”,
“rule”: “reporting”,
“blackout”: { “start”: “08:00”, “end”: “17:00”},
“maxtime”: 2000}
“ … ”
}
]
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-39-320.jpg)
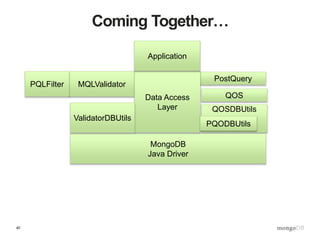

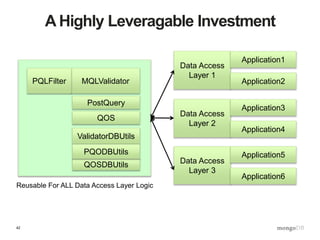

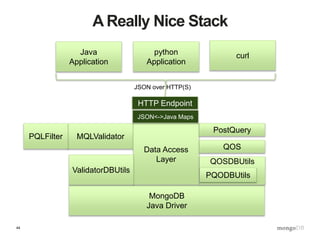



![48
Robust, Validated Data Ingest
$ curl –d @trades.json
-H X-Portal-Id:prodadm
-H X-Portal-PW:thePassword
https://refdata:8080trades?op=load
-o response.json
$ cat response.json
{ “assignedBatchID”: “B123”,
“numItemsExamined”: 13245,
“numItemsInserted”: 13242,
“numItemsRejected”: 3,
“errors”: [ { type: “valfail”, rule: “front … ],
“batchMD5”: “e19c1283c925b3206685ff522acfe3e6”
}](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-48-320.jpg)
![49
Concept: The control_ Collection
> show collections
books
control_
customer
firms
> db.control_.find()
{
“collectionName”: “product”,
“qos”: [ … ],
“validations”: [ … ]
“operations”: [… ]
}
• Single namespace for capabilities
• Easier to add new capabilities
• Tighter (therefore better) security/entitlement](https://image.slidesharecdn.com/s2gkweapscidjbxwefua-signature-f33f9d457a157501d52f3b0bdf9c135f6167d4bf55c7ba71661ee00b8fc15612-poli-150605212815-lva1-app6892/85/Data-Management-3-Bulletproof-Data-Management-49-320.jpg)
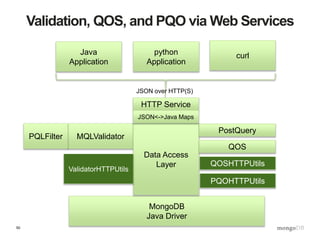






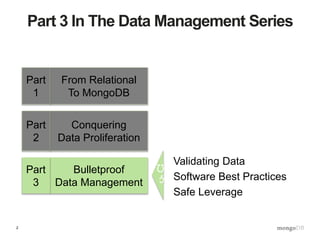
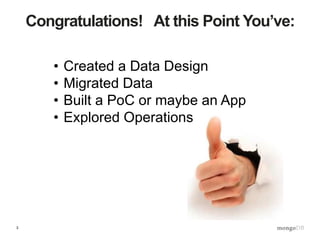
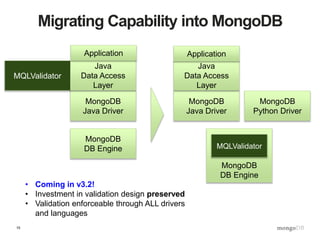
The document discusses best practices for data management in MongoDB, focusing on data validation, redaction, and quality of service (QoS) features. It outlines the architecture for implementing a validation and post-query operation model using Java, alongside various techniques for managing and optimizing data access. Additionally, it provides examples of how to integrate these features with a web service, emphasizing an organized and robust approach to data governance.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


