Download as PDF, PPTX







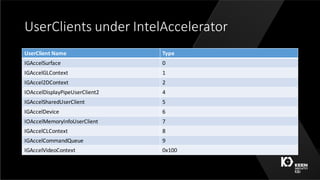





















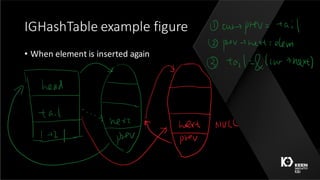










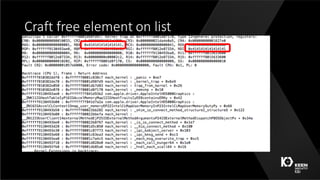


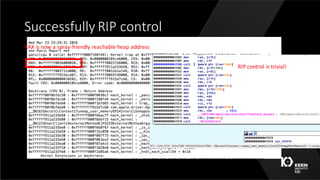



















This document summarizes a presentation given by three security researchers from Tencent KEEN Security Lab at CanSecWest 2016 about compromising Apple graphics. They discuss fuzzing Apple's graphics drivers to find vulnerabilities by targeting interfaces that are reachable from the Safari sandbox. As a case study, they describe a race condition vulnerability they discovered in AppleIntelBDWGraphics that could lead to a double free and kernel code execution on macOS systems with Intel Broadwell graphics. They provide tips for making fuzzing more effective, such as targeting less restricted interfaces and leveraging relationships between different graphics interfaces and objects.














































































