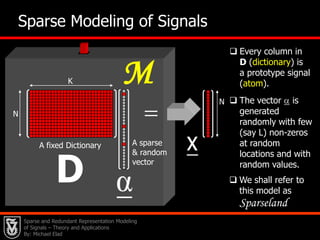
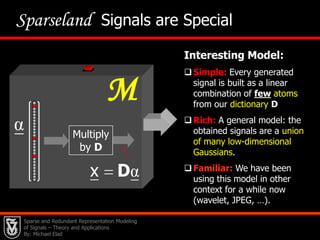
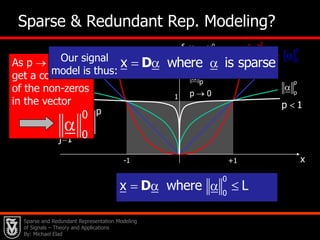
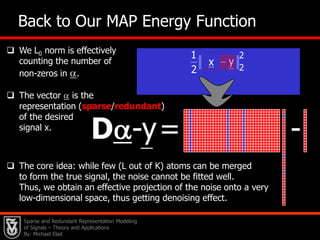
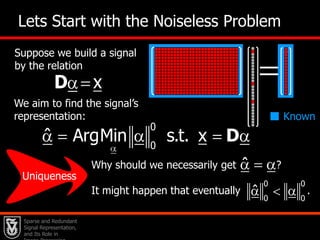
This document presents an overview of sparse and redundant representation modeling of images, focusing on denoising and applications in image processing. Michael Elad discusses theoretical foundations, numerical problems, and various algorithms associated with sparse representations, including the K-SVD algorithm for dictionary learning. The findings highlight the effectiveness of these models in achieving state-of-the-art results in image denoising and related tasks.











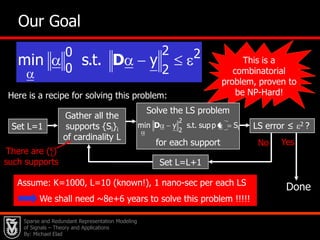









![20 Relaxation – The Basis Pursuit (BP)Instead of solvingSolve InsteadThis is known as the Basis-Pursuit (BP) [Chen, Donoho & Saunders (’95)].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-31-320.jpg)


![Interior point methods [Chen, Donoho, & Saunders (‘95)] [Kim, Koh, Lustig, Boyd, & D. Gorinevsky (`07)].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-34-320.jpg)
![Sequential shrinkage for union of ortho-bases [Bruce et.al. (‘98)].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-35-320.jpg)
![Iterative shrinkage [Figuerido & Nowak (‘03)] [Daubechies, Defrise, & De-Mole (‘04)] [E. (‘05)] [E., Matalon, & Zibulevsky (‘06)] [Beck & Teboulle (`09)] … Sparse and Redundant Representation Modeling of Signals – Theory and Applications By: Michael Elad](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-36-320.jpg)
![21 Go Greedy: Matching Pursuit (MP)The MPis one of the greedy algorithms that finds one atom at a time [Mallat & Zhang (’93)].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-37-320.jpg)



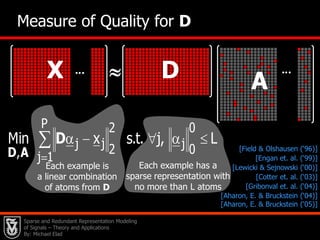
![22Pursuit Algorithms?Why should they workThere are various algorithms designed for approximating the solution of this problem: Greedy Algorithms: Matching Pursuit, Orthogonal Matching Pursuit (OMP), Least-Squares-OMP, Weak Matching Pursuit, Block Matching Pursuit [1993-today].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-42-320.jpg)
![Relaxation Algorithms: Basis Pursuit (a.k.a. LASSO), Dnatzig Selector & numerical ways to handle them [1995-today].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-43-320.jpg)
![Hybrid Algorithms: StOMP, CoSaMP, Subspace Pursuit, Iterative Hard-Thresholding [2007-today].](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-44-320.jpg)




![Average performance results are available too, showing much better bounds [Donoho (`04)] [Candes et.al. (‘04)] [Tanner et.al. (‘05)] [E. (‘06)] [Tropp et.al. (‘06)] … [Candes et. al. (‘09)]. Sparse and Redundant Representation Modeling of Signals – Theory and Applications By: Michael Elad](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-49-320.jpg)





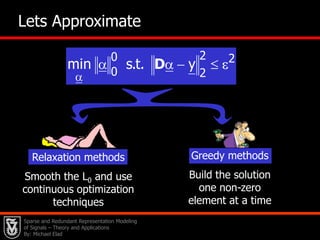
![29DXAEach example has a sparse representation with no more than L atomsEach example is a linear combination of atoms from DMeasure of Quality for D[Field & Olshausen (‘96)][Engan et. al. (‘99)][Lewicki & Sejnowski (‘00)][Cotter et. al. (‘03)][Gribonval et. al. (‘04)][Aharon, E. & Bruckstein (‘04)] [Aharon, E. & Bruckstein (‘05)]Sparse and Redundant Representation Modeling of Signals – Theory and Applications By: Michael Elad](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-56-320.jpg)

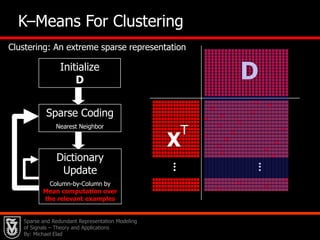
![31DInitialize DSparse CodingUse Matching PursuitXTDictionary UpdateColumn-by-Column by SVD computation over the relevant examples The K–SVD Algorithm – General [Aharon, E. & Bruckstein (‘04,‘05)]Sparse and Redundant Representation Modeling of Signals – Theory and Applications By: Michael Elad](https://image.slidesharecdn.com/cssparsejune2010-110519001047-phpapp02/85/C-s-sparse-june_2010-58-320.jpg)