Downloaded 60 times











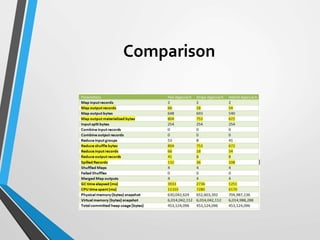
![Stripe approach (Reducer) –
pseudo code
total = 0;
method reduce(Text key, Stripe H [H1, H2, …])
total = sumValues(H);
for each Item h in H do
h.secondValue /= total;
Emit(key, H);](https://image.slidesharecdn.com/big-data-project-150518225926-lva1-app6892/85/CrystalBall-Compute-Relative-Frequency-in-Hadoop-11-320.jpg)



![Stripe approach –
Output(Reducer1)
10 [ (34,0.5000) (12,0.5000) ]
12 [ (56,0.1818) (92,0.1818) (34,0.3636) (18,0.0909) (79,0.0909) (10,0.0909) ]
18 [ (56,0.1250) (92,0.1250) (34,0.2500) (79,0.1250) (29,0.1250) (12,0.2500) ]
29 [ (56,0.1333) (92,0.1333) (34,0.2667) (18,0.0667) (79,0.0667) (10,0.0667)
(12,0.2667) ]
34 [ (56,0.2500) (92,0.1667) (18,0.0833) (79,0.0833) (29,0.0833) (10,0.0833)
(12,0.2500) ]
56 [ (92,0.2000) (34,0.3000) (29,0.1000) (10,0.1000) (12,0.3000) ]
92 [ (34,0.3333) (10,0.3333) (12,0.3333) ]](https://image.slidesharecdn.com/big-data-project-150518225926-lva1-app6892/85/CrystalBall-Compute-Relative-Frequency-in-Hadoop-15-320.jpg)
![Stripe approach –
Output(Reducer2)
79 [ (56,0.2000) (92,0.2000) (34,0.2000) (18,0.2000)
(12,0.2000) ]](https://image.slidesharecdn.com/big-data-project-150518225926-lva1-app6892/85/CrystalBall-Compute-Relative-Frequency-in-Hadoop-16-320.jpg)















This document describes a project using the MapReduce and Spark frameworks to analyze term relationships in documents. It provides pseudocode and Java code examples for MapReduce approaches like pair counting, stripes, and hybrid to output term relationship frequencies. It also includes Spark code to count the number of students by country from input data and displays the output. The document compares the different approaches and lists the tools used for the project.















![[Lecture 3] AI and Deep Learning: Logistic Regression (Coding)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture3empty-180216132805-thumbnail.jpg?width=640&height=640&fit=bounds)

















































