Downloaded 14 times




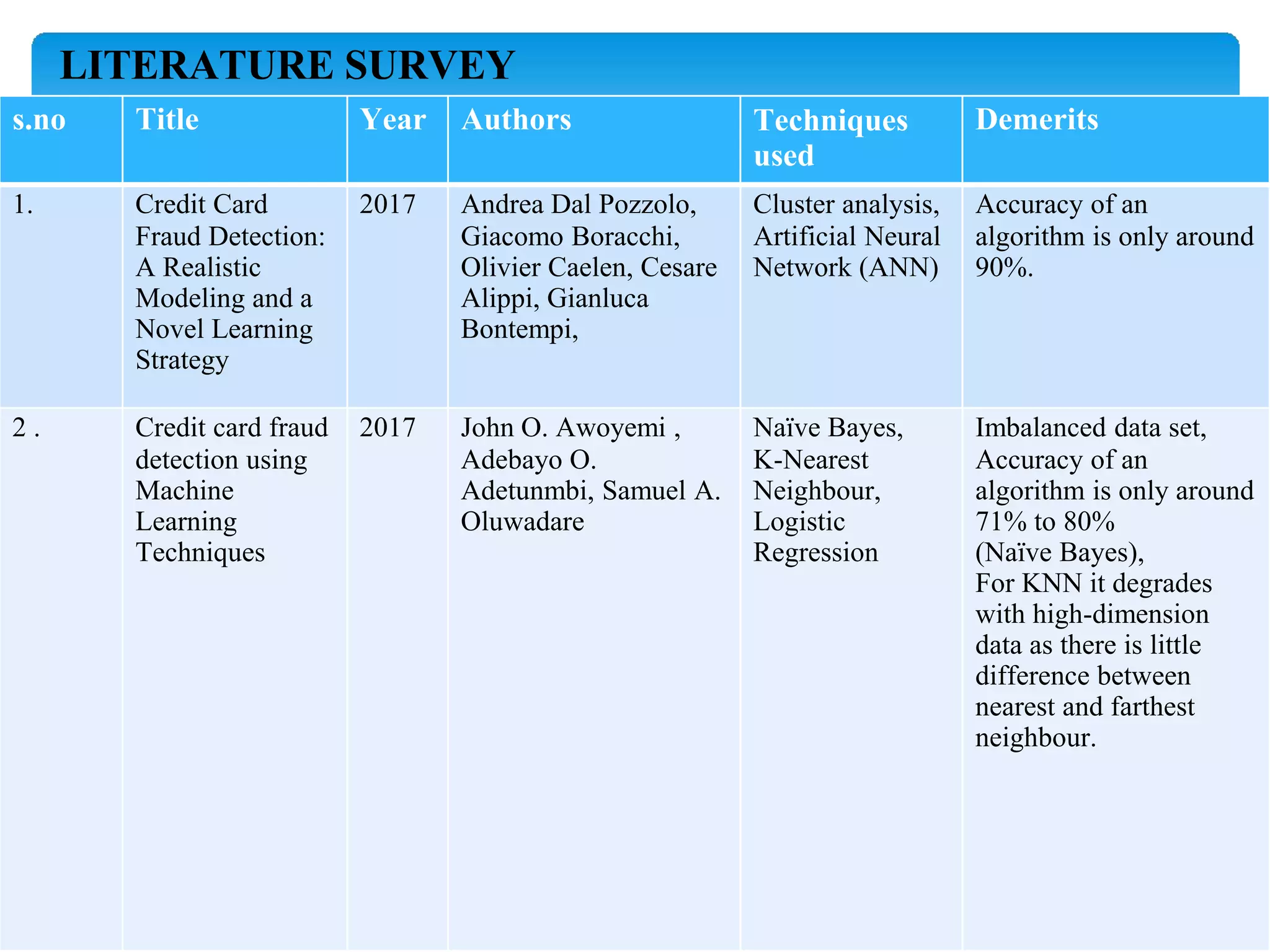
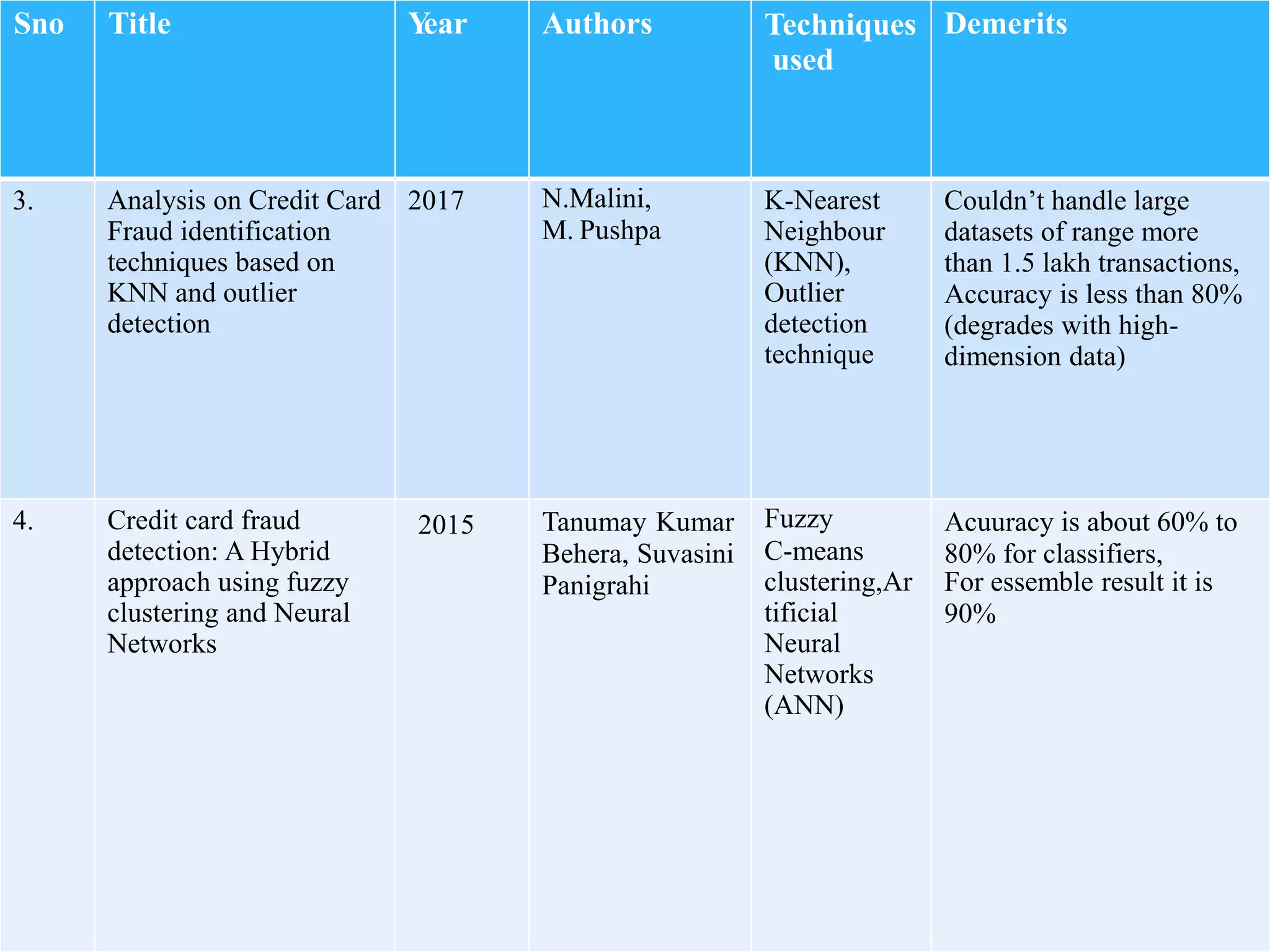


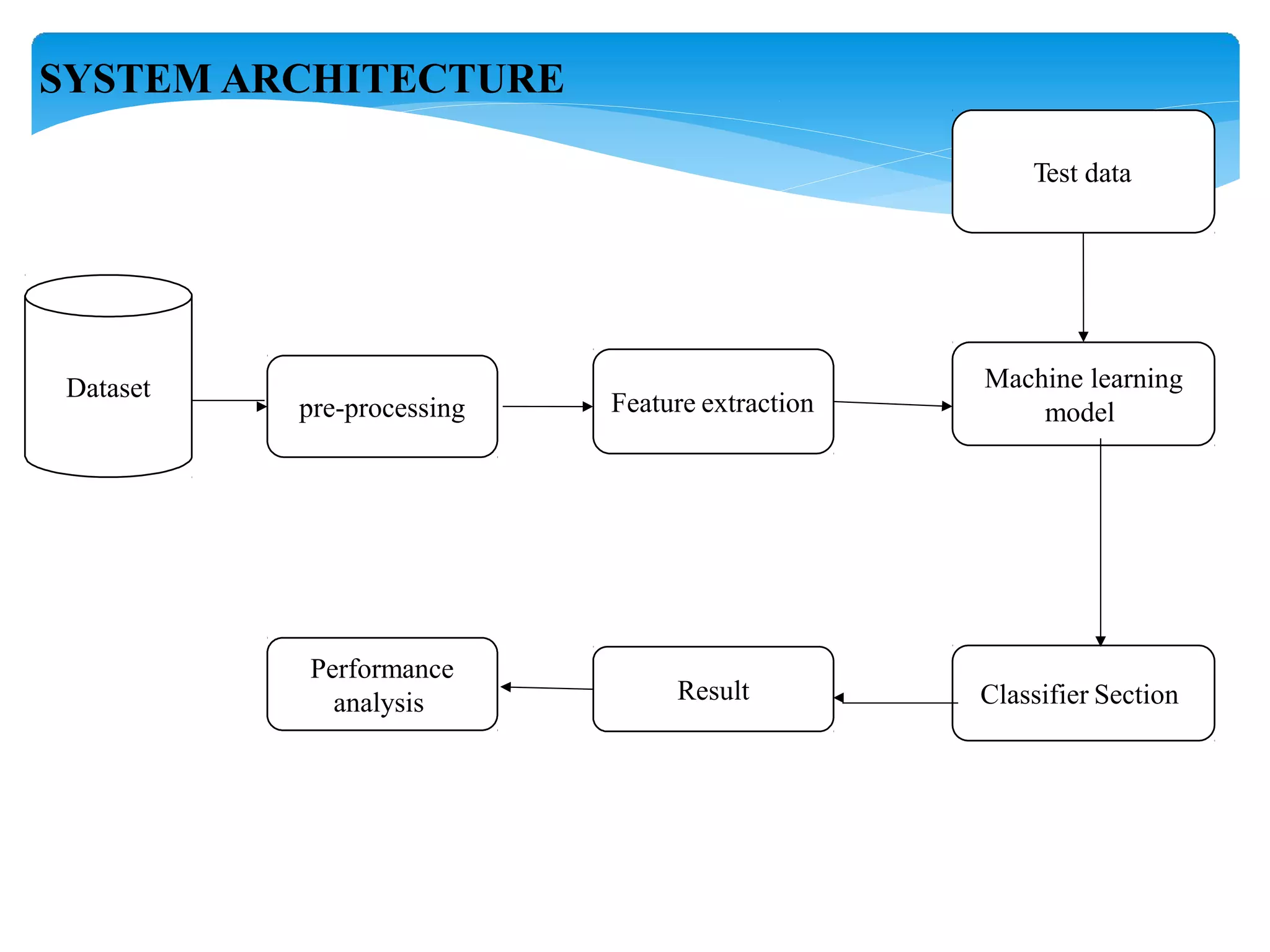




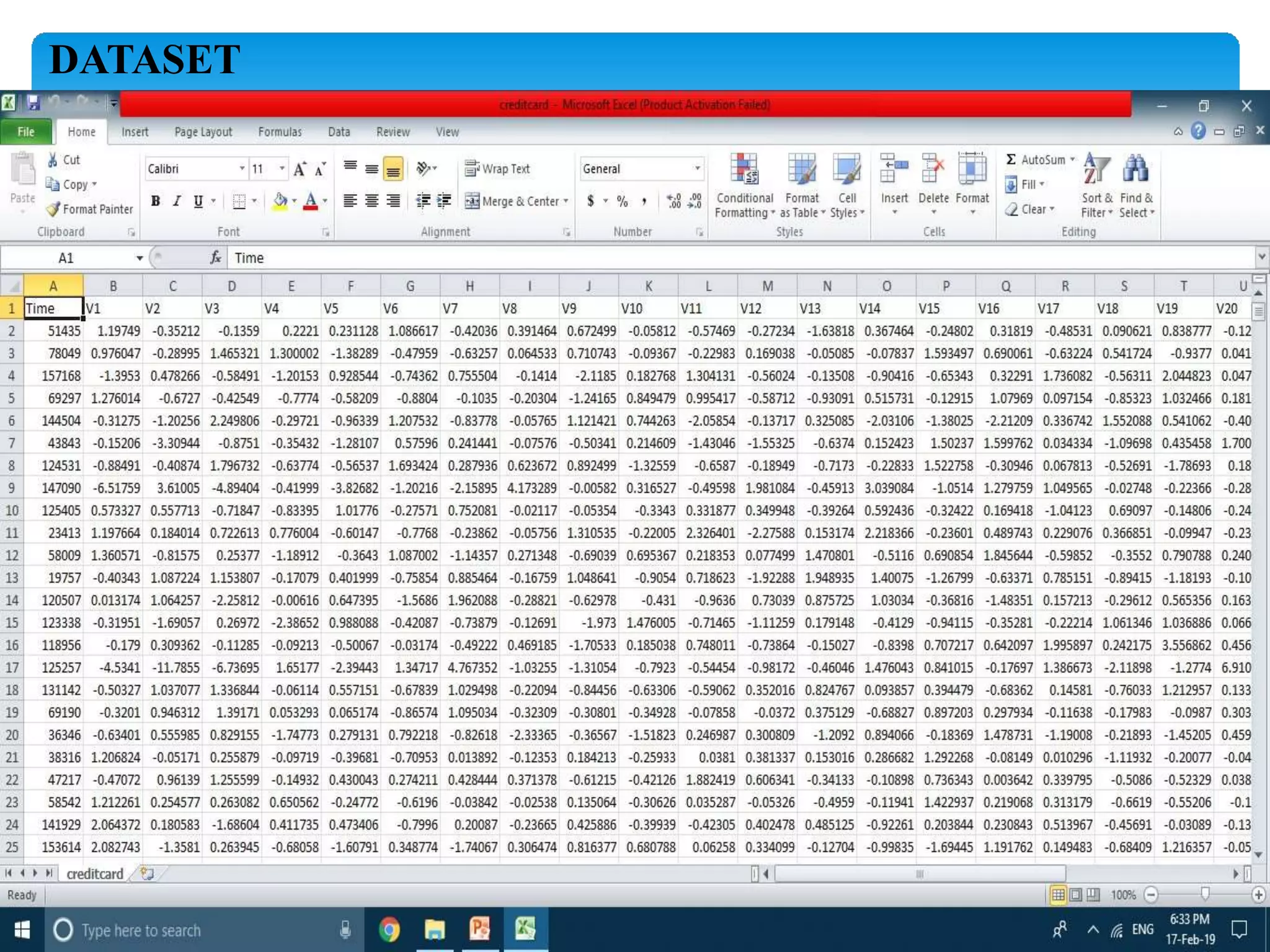


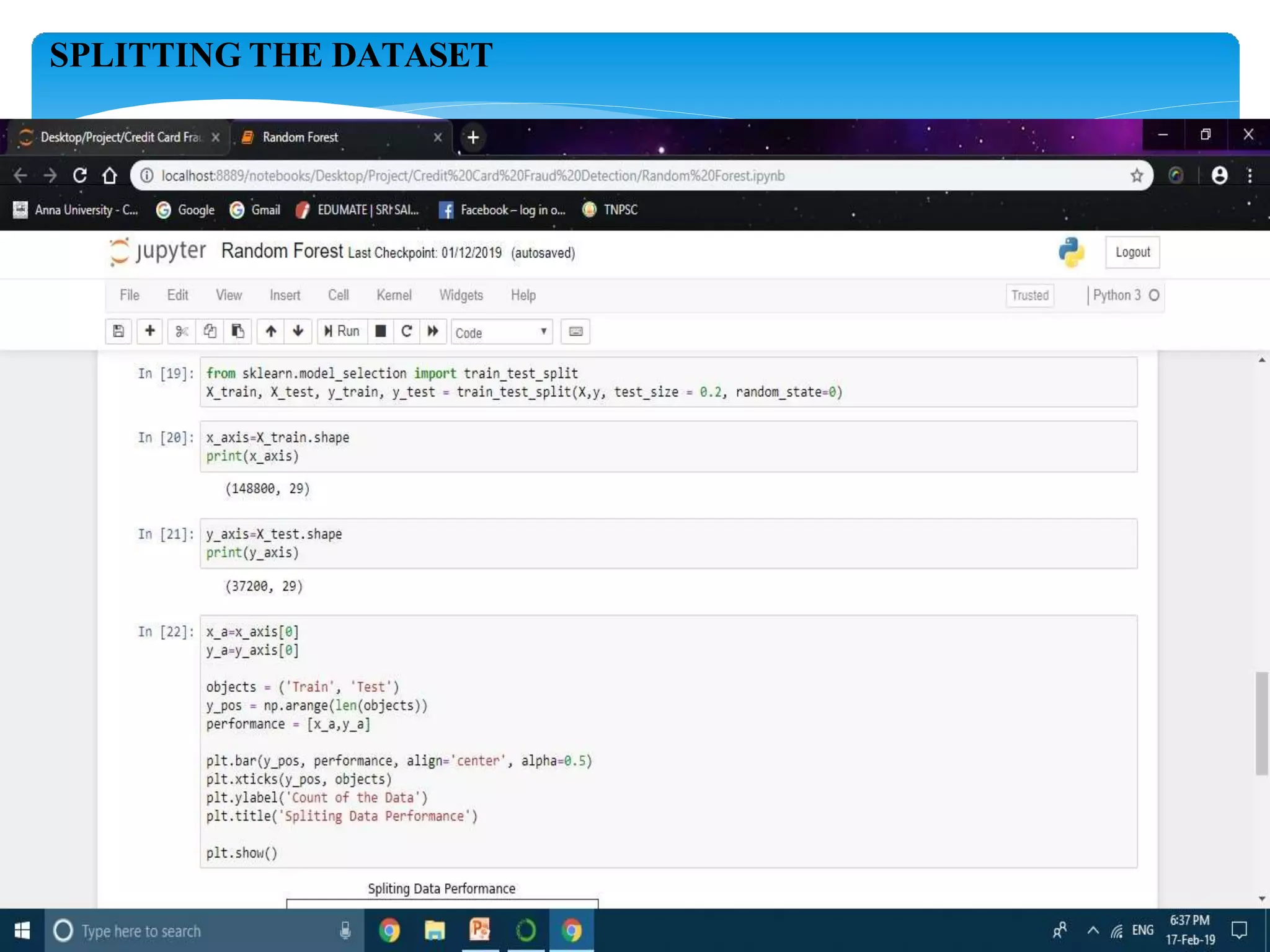
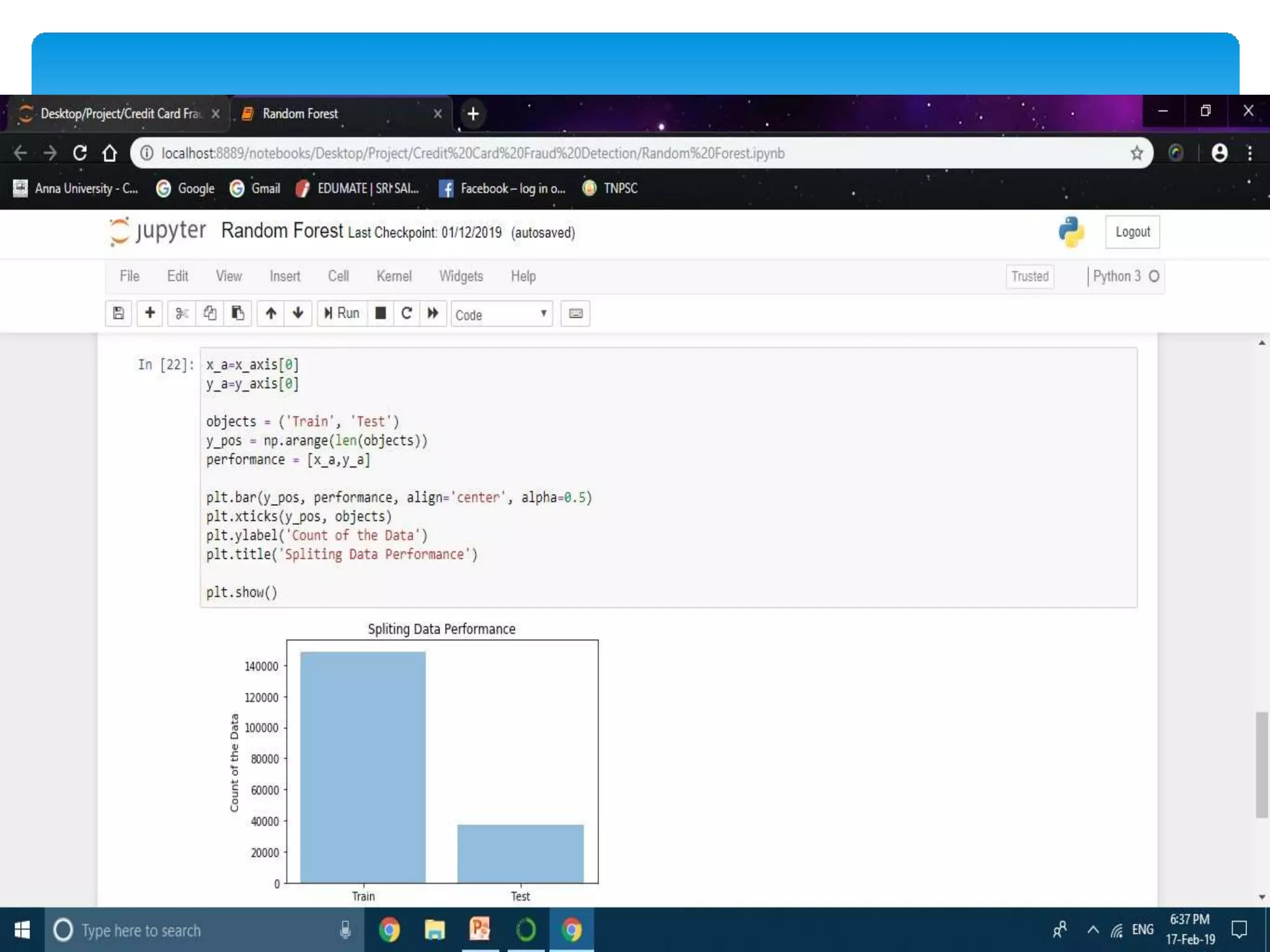





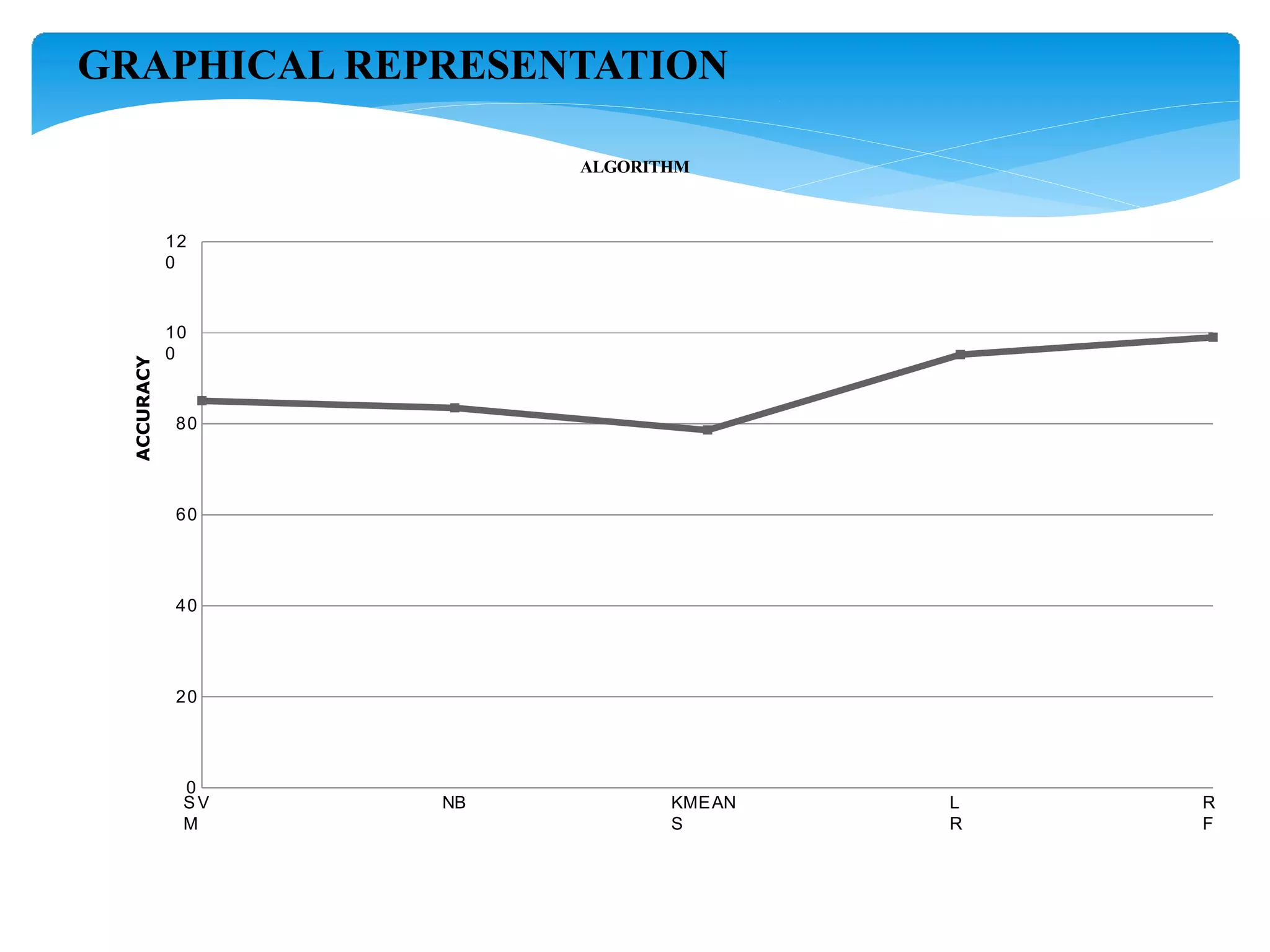




The document describes using a random forest algorithm to detect credit card fraud. It begins with an abstract that outlines analyzing a credit card dataset, applying random forest, and identifying fraud transactions with 98% accuracy. Existing methods are discussed that achieve 60-70% accuracy. The proposed system uses random forest classification to analyze the dataset, which can process large amounts of data quickly and achieve 98% accuracy. Literature on the topic is surveyed. Random forest and the system architecture are described in more detail, including modules for data collection, preprocessing, feature extraction, model evaluation and visualization of results. The random forest model achieves 98.6% accuracy, outperforming other methods. Conclusions discuss potential improvements like using more data and preprocessing techniques.



































































