STUDENT NAME :SANGEETHA T
REGISTER NUMBER : 422323106022
INSTITUTION : TCET - VANDAVASI
DEPARTMENT : ECE – II ND YEAR
DATE OF SUBMISSION : 15-05-2025
GITHUB REPOSITORY LINK:
https://github.com/Sangee56/sangeetha.a.git
PROBLEM STATEMENT
The increasingprevalence of credit card fraud in the digital era necessitates the development
of robust and efficient fraud detection systems.
This project aims to develop a machine-learning model to detect credit card fraud. The
model will be trained on a dataset of historical credit card transactions and evaluated on a
holdout dataset of unseen transactions.
4.
ABSTRACT
● AI-Powered CreditCard Fraud Detection and Prevention
● Credit card fraud poses a significant threat to financial institutions and consumers,
resulting in substantial financial losses and eroding customer trust. Traditional rule-
based fraud detection systems, while effective to some extent, often struggle to keep
up with evolving fraud tactics. This paper presents an AI-powered approach to credit
card fraud detection and prevention, leveraging machine learning algorithms and real-
time data analysis to improve detection accuracy and reduce false positives. The
proposed system utilizes a combination of supervised learning for known fraud
patterns and anomaly detection for identifying previously unseen threats. Key
techniques include data preprocessing, feature engineering, and the application of
advanced models such as random forests, gradient boosting, and deep learning neural
networks. This AI-driven framework not only enhances security but also provides a
scalable, adaptive solution for mitigating financial fraud in a rapidly changing digital
landscape.
5.
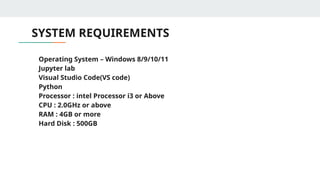
SYSTEM REQUIREMENTS
• OperatingSystem – Windows 8/9/10/11
• Jupyter lab
• Visual Studio Code(VS code)
• Python
• Processor : intel Processor i3 or Above
• CPU : 2.0GHz or above
• RAM : 4GB or more
• Hard Disk : 500GB
6.
OBJECTIVES
● This projecttackles the critical challenge of credit card fraud
detection and prevention.
● Our goal is to develop effective methods using machine learning,
anomaly detection, and deep learning to identify fraudulent
activities.
● Objective : Enhancing financial transaction security and
minimizing fraudulent losses.
DATASET DESCRIPTION
● DataDescription: The dataset was retrieved from an open-source website,
Kaggle.com. It contains data on transactions made in 2013 by European credit card users
in two days only. The dataset consists of 31 attributes and 284,808 rows.
○ Twenty-eight attributes are numeric variables that, due to the confidentiality and privacy of the customers.
○ Time: which contains the elapsed seconds between the first and other transactions of each Attribute.
○ Amount : Which is the amount of each transaction
○ Claswhich contains binary s : variables where 1 is a case of fraudulent transaction, and 0 is not as case of
fraudulent transaction.
● Dataset : https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
10.
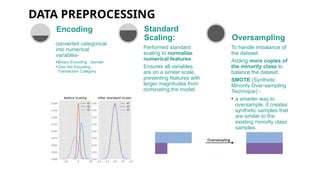
DATA PREPROCESSING
converted categorical
intonumerical
variables-
•Binary Encoding : Gender
•One Hot Encoding :
Transaction Category
Encoding
Performed standard
scaling to normalize
numerical features.
Ensures all variables
are on a similar scale,
preventing features with
larger magnitudes from
dominating the model.
Standard
Scaling:
To handle imbalance of
the dataset.
Adding more copies of
the minority class to
balance the dataset.
SMOTE (Synthetic
Minority Over-sampling
Technique) -
• a smarter way to
oversample, it creates
synthetic samples that
are similar to the
existing minority class
samples.
Oversampling
11.
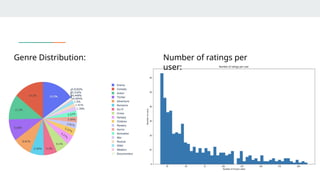
EDA (Exploratory DataAnalysis)
Data
CleaningRemoved the
columns that are
not required for
model building
No nulls were
there & Rectified
inappropriate
datatype
Feature
Engineering
Created Some
new features as
required
•For e.g., is_fraud_cat
for categorical
analysis,
•for numerical analysis
age' , 'trans_month',
'trans_year',
'month_name’,etc.
Categorical
Variable
Analysis
Visualized -
•Transaction
categories and
gender distribution,
both for the entire
dataset and
specifically for
fraudulent
transactions.
•Top 10 fraudulent
transactions by job,
city, and state
Numerical
Variable
Analysis
Visualized Overall
Skewness
Class balance –
• Not Fraud
(99.4%)
• Fraud (0.6%)
Bivariate
Analysis -
Vizualisation with
'is_fraud'
• age groups ,
• latitudinal &
longitudinal
distance and
• month & year.
12.
FEATURE ENGINEERING
Credit cardfraud involves unauthorized use of credit cards to obtain goods, services, or
funds. It affects both individuals and businesses, leading to financial losses and compromised
personal information. Some common types of credit card fraud are:
Card Not Present Fraud:
● Occurs when the physical card isn’t present during a transaction (common in online or
over-the-phone purchases). In 2023, card not present fraud accounted for an estimated
$9.49 billion in losses.
Account Takeover Fraud:
● Fraudsters gain access to a victim’s account to make unauthorized transactions. In
2023, account takeover attacks increased by 354% year-over-year, resulting in almost
$13 billion in losses
14.
MODEL BUILDING
Data collection:
Thefirst phase will involve collecting a dataset of historical credit card transactions. The
data will be collected from various sources, including banks, credit card companies, and
merchants.
Data Cleaning:
• Impute the missing values with the column's mean, median, or mode.
• Drop the rows with missing values.
• Use a machine learning model to predict the missing values like isnull() and heatmap().
Normalize the data:
Normalization is scaling the data so that all features have similar values. This can
improve the performance of machine learning models by making the parts more
comparable.
Model training:
The second phase will involve training the machine learning model on the collected data.
The model will be prepared using a supervised learning algorithm like SVM.
Model evaluation:
The third phase will involve evaluating the machine learning model's performance on a
holdout dataset of unseen transactions. The model's performance will be evaluated using
accuracy, precision, and recall metrics.
15.
MODEL BUILDING
Machine Learning
Technique
•Logistic Regression:
• Interpretability: Provides straightforward interpretations of coefficients
for understanding feature impact on fraud likelihood.
• Simplicity: Easy implementation and understanding facilitate
communication with stakeholders.
• Random Forest:
• Complex Relationship Capture: Excels at capturing complex data
relationships to detect subtle fraud patterns.
• Minimal Feature Engineering: Requires minimal feature manipulation,
suitable for challenging feature selection scenarios.
Anomaly Detection
Technique
• Isolation Forest:
• Efficient Anomaly Detection: Efficiently isolates anomalies (fraudulent
transactions) in high-dimensional data.
• Distribution Agnostic: Robust against various fraud patterns without
assuming specific data distributions.
Deep Learning
Technique
• Neural Network (MLP Classifier):
• Nonlinear Pattern Detection: Captures nonlinear data relationships for
sophisticated fraud detection.
• Scalability: Handles large data volumes and adapts to real-time fraud
detection needs.
MODEL EVALUATION
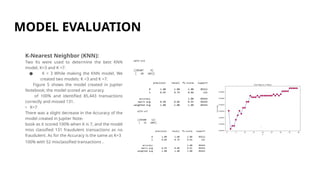
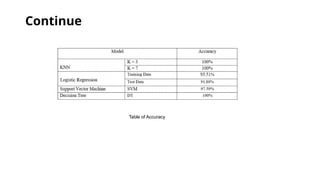
K-Nearest Neighbor(KNN):
Two Ks were used to determine the best KNN
model, K=3 and K =7.
● K = 3 While making the KNN model, We
created two models: K =3 and K =7.
Figure 5 shows the model created in Jupiter
Notebook; the model scored an accuracy
of 100% and identified 85,443 transactions
correctly and missed 131.
• K=7
There was a slight decrease in the Accuracy of the
model created in Jupiter Note-
book as it scored 100% when K is 7, and the model
miss classified 131 fraudulent transactions as no
fraudulent. As for the Accuracy is the same as K=3
100% with 52 misclassified transactions .
19.
Continue
Logistic Regression (L.R.):
○The last model created using Jupiter Notebook is Logistic Regression; the model managed to score an
Accuracy on Training data of 93.51% , while it scored an Accuracy score on Test Data of 91.88%, as
presented in blew Figure.
20.
Continue
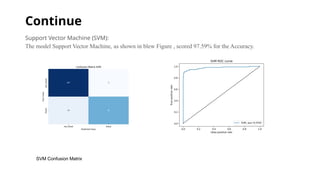
Support Vector Machine(SVM):
The model Support Vector Machine, as shown in blew Figure , scored 97.59% for the Accuracy.
SVM Confusion Matrix
DEPLOYMENT
Integrate the trainedmachine learning models into the retail
organization’s fraud detection system. Ensure seamless
interoperability with existing infrastructure and workflows.
Provide ongoing support and maintenance to monitor model
performance, address emerging fraud threats, and fine-tune
algorithms as necessary
25.
Card Skimming:
● Fraudstersuse devices to
capture card information
from ATMs or point-of-sale
terminals. Card skimming
costs consumers and financial
institutions over $1 billion
annually.
Phishing Scams:
● Trick victims into providing
card information through fake
emails, texts, or websites
26.
VISUALIZATION OF RESULTS& MODEL INSIGHTS
Inferences :
• Achieves a perfect accuracy (1.00), indicating it classified all transactions correctly (might be due to overfitting on the training data).
• Both precision and recall are high for both fraudulent and non-fraudulent transactions.
• F1-scores are also high for both classes.
• ROC-AUC score (0.9930) suggests excellent discriminative ability between classes.
• ROC Curve: Close to top-left corner, indicating good TPR-FPR trade-off.
• Precision-Recall Curve: Fairly close to top-left corner, indicating good precision-recall balance.
FUTURE SCOPE
1. Evolutionof AI/ML Techniques
Generative AI: This cutting-edge approach revolutionizes fraud
prevention. By combining adaptive learning, large dataset
handling, improved anomaly detection, and reduced false
positives, generative AI enhances our ability to stay ahead of
fraudsters.
Explainable AI (XAI): Researchers are working on making
complex AI models more interpretable. XAI ensures that we
understand why a model makes specific predictions, which is
crucial for trust and accountability.
Hybrid Models: Combining different ML techniques—such as
neural networks, decision trees, and clustering—allows us to
leverage their strengths and mitigate their weaknesses
30.
TEAMS MEMBERS ANDCONTRIBUTIONS
HEMALATHA S : PROBLEM STATEMENT & ABSTRACT ,OBJECTIVE, FEATURE
ENGINEERING ,DEPLOYMENT,SOURCE CODE
SANGEETHA T : DATA SET DESCRIPTION & PREPROCESSING , EDA , MODEL
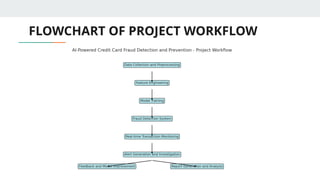
BUILDING, FLOWCHART OF THE PROJECT WORKFLOW
MAGESHWARAN P : MODEL BUILDING & FUTURE SCOPE, SYSTEM
REQUIEMENTS, MODEL EVALUATION