PRESENTATIONOUTLINE
• Introduction
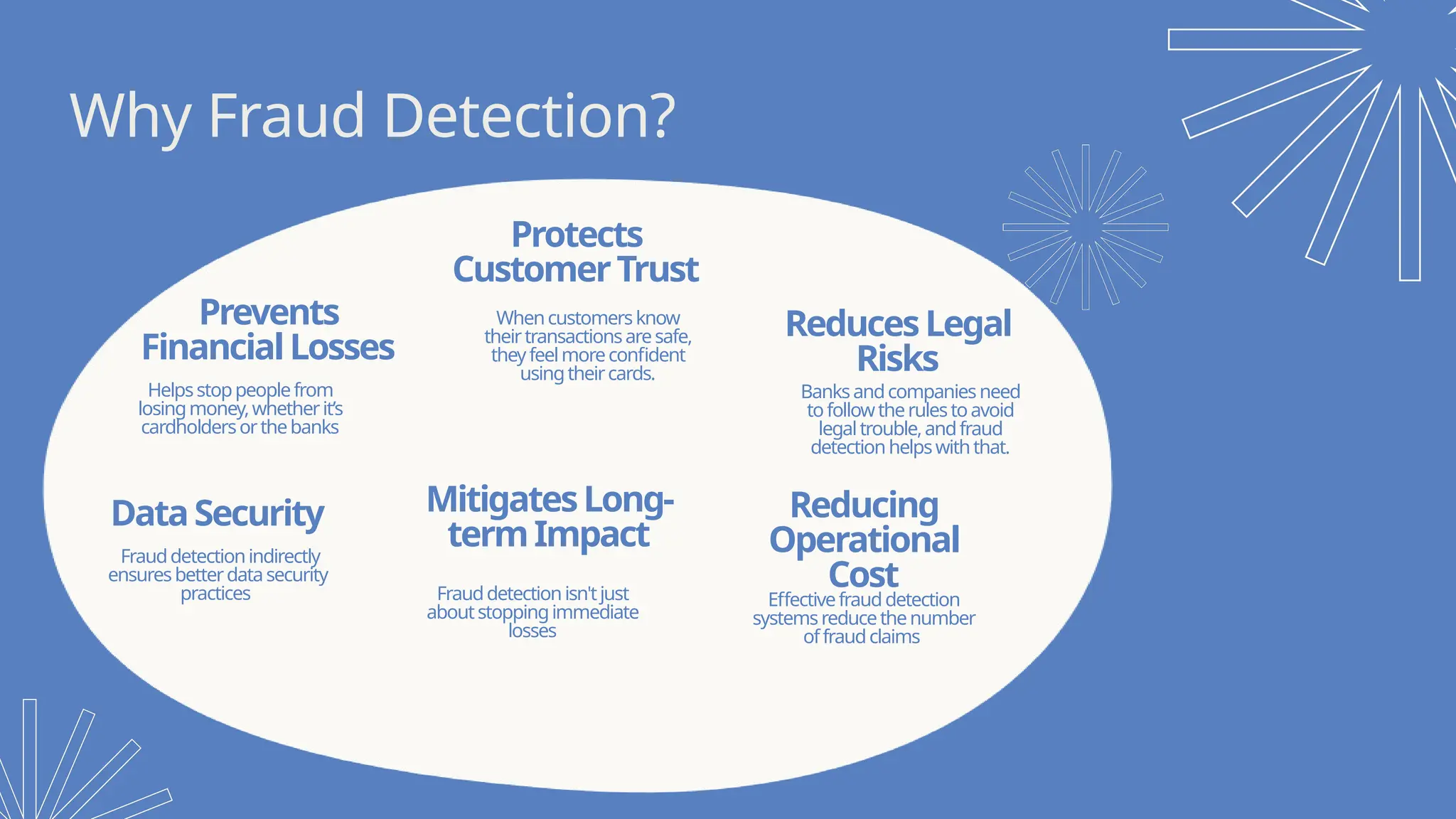
• WhyFraud Detection?
• Problem Statement
• Dataset Overview
• Data Processing
• Anomaly Detection
• Algorithms Used
• Results
• Conclusion
• References
3.
Unauthorized purchases madeusing stolen
or compromised credit cards.
Increasingly sophisticated fraud methods.
Why It’s More Critical Today:
The growth of digital transactions and online
shopping creates more opportunities for
fraud.
Key Challenge:
Fraud represents less than 1% of
transactions, making detection within large
datasets difficult.
Solution Approach:
Use advanced machine learning models and
anomaly detection algorithms to differentiate
between legitimate and fraudulent
transactions.
Project Goal: Efficiently and accurately detect
fraud using machine learning techniques.
Write your topic here
Write your topic here
Introduction
Write your topichere
Write your topic here
ProblemStatement
Credit card fraud is a significant issue, leading to substantial financial losses globally. The
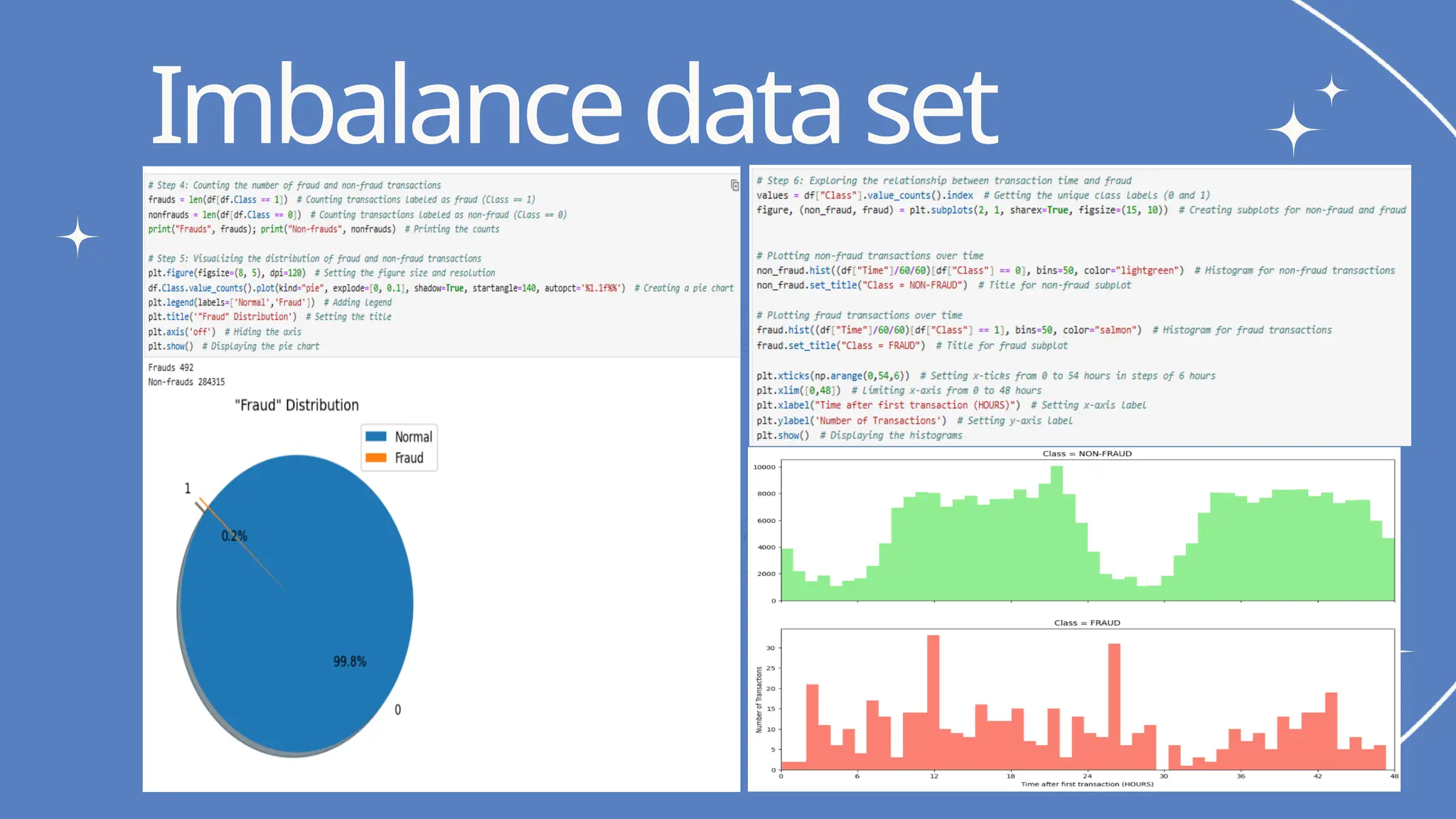
challenge is to detect fraudulent transactions in a highly imbalanced dataset, where less
than 1% of transactions are fraudulent.
Our goal is to build a model that can: Accurately identify fraudulent transactions in a large
dataset. Minimize false positives while maintaining high detection rates. Leverage anomaly
detection algorithms like Isolation Forest to distinguish between normal and fraudulent
transactions.
6.
Write your topichere
Write your topic here
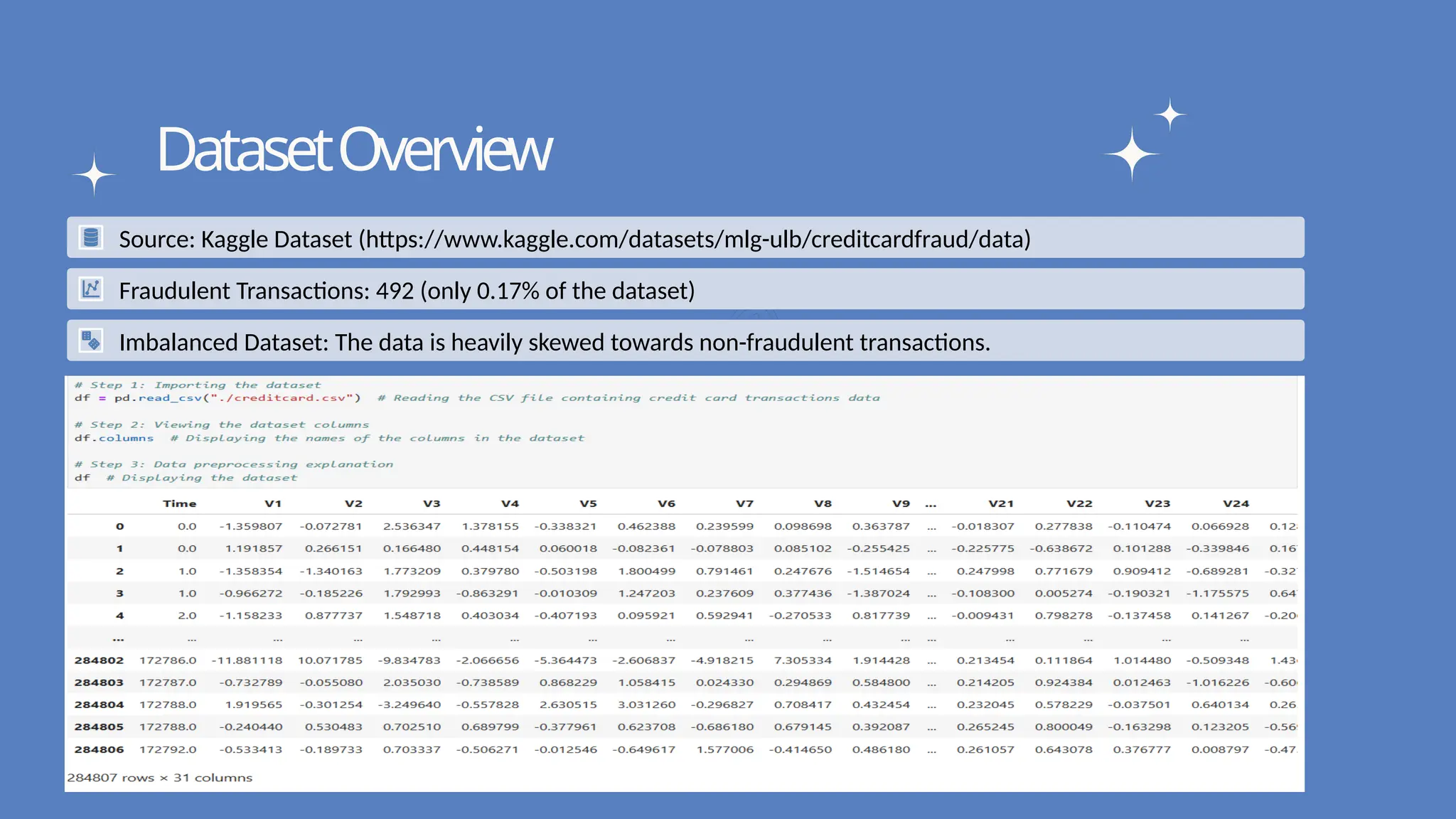
DatasetOverview
Source: Kaggle Dataset (https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud/data)
Fraudulent Transactions: 492 (only 0.17% of the dataset)
Imbalanced Dataset: The data is heavily skewed towards non-fraudulent transactions.
Write your topichere
Write your topic here
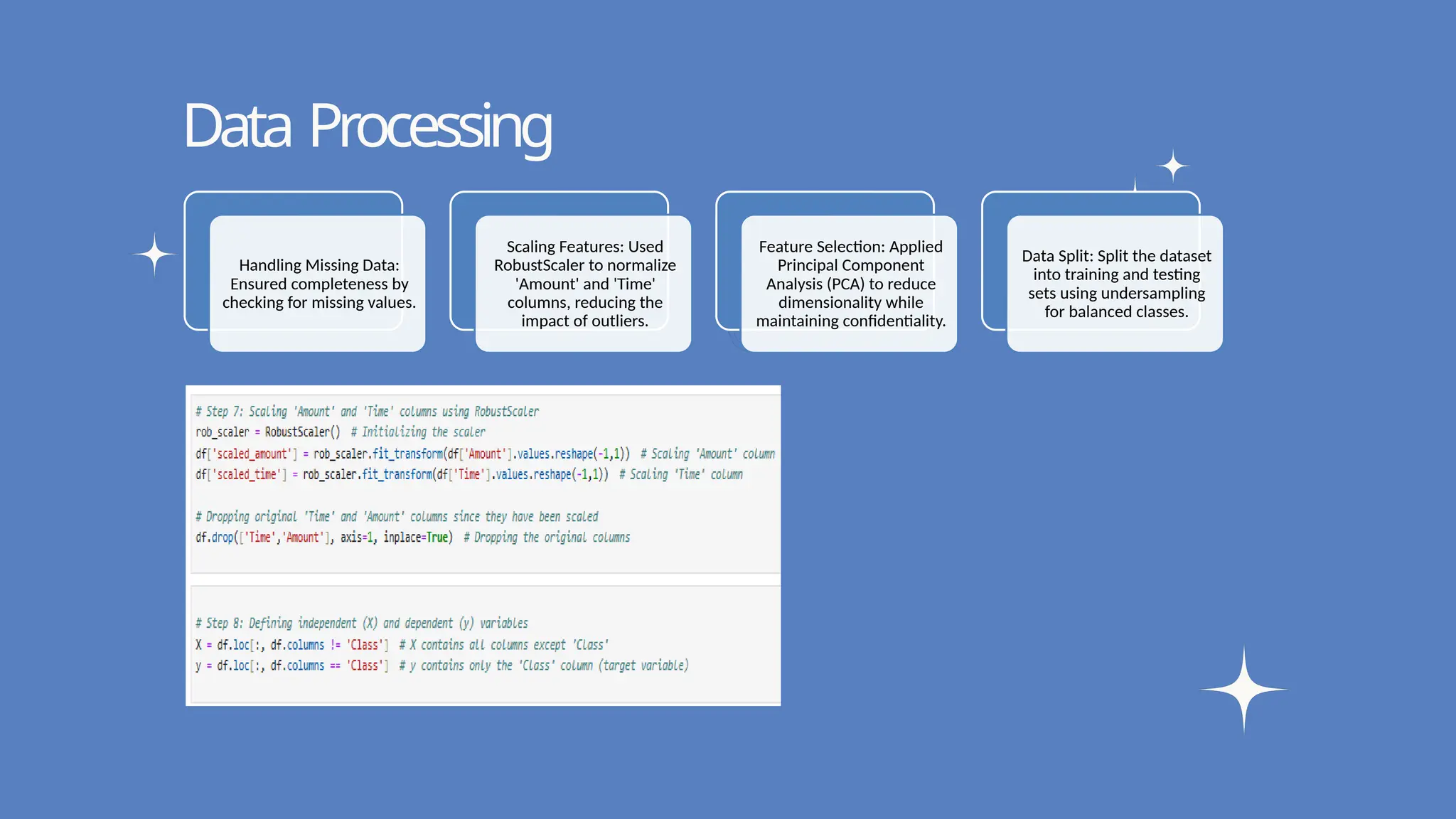
Data Processing
Handling Missing Data:
Ensured completeness by
checking for missing values.
Scaling Features: Used
RobustScaler to normalize
'Amount' and 'Time'
columns, reducing the
impact of outliers.
Feature Selection: Applied
Principal Component
Analysis (PCA) to reduce
dimensionality while
maintaining confidentiality.
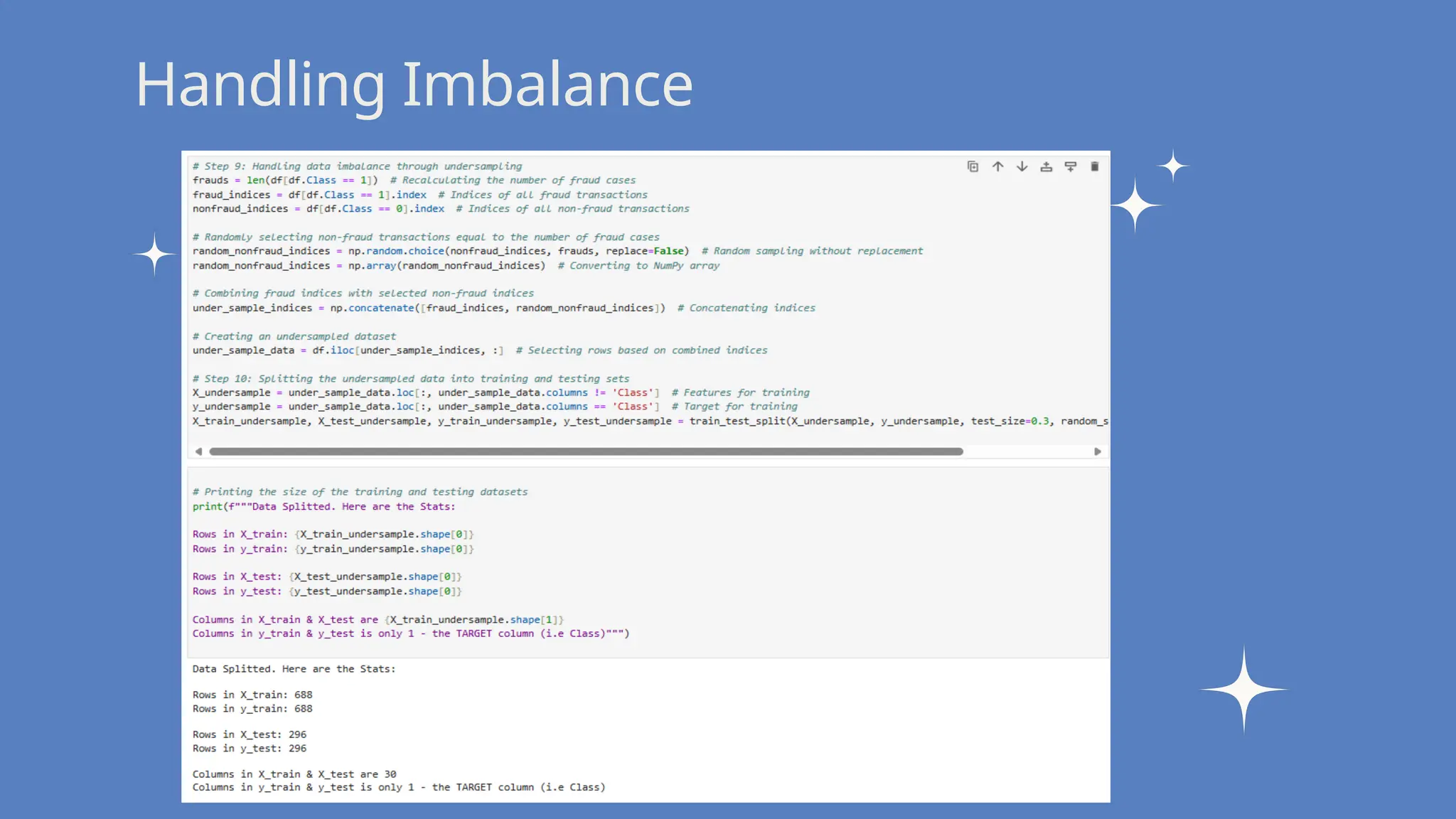
Data Split: Split the dataset
into training and testing
sets using undersampling
for balanced classes.
9.
Write your topichere
Write your topic here
WhatisAnomalyDetection?
In the context of credit card fraud detection, anomaly detection
techniques are crucial for identifying suspicious activities that deviate
from typical transaction patterns.
Anomaly Detection is the task of identifying rare or unusual data
points, known as anomalies, which significantly differ from the
normal patterns within the data.
Why is Fraud Detection an Anomaly Detection Problem?
Rarity of Fraudulent Transactions: Fraudulent transactions are
significantly rarer compared to legitimate ones, classifying them as
anomalies within the dataset.
Challenge for Models: Models must accurately identify these
anomalies while minimizing false positives, ensuring legitimate
transactions are not misclassified as fraud.
Write your topichere
Write your topic here
Algorithms Used: Logistic Regression
It is a binary classification algorithm that models the probability
of a binary outcome (e.g., fraudulent vs. non-fraudulent
transactions). It is effective for distinguishing between two
categories, such as identifying fraudulent transactions in credit
card data.
Why Logistic Regression?
Fast and easy to implement, making it ideal for real-time fraud
detection systems.
Perfectly suited for problems with two possible outcomes: fraud
or non-fraud.
It provides probability scores that are easily interpretable, giving
insight into how likely a transaction is to be fraudulent.
12.
Write your topichere
Write your topic here
Model Training and Evaluation
13.
Write your topichere
Write your topic here
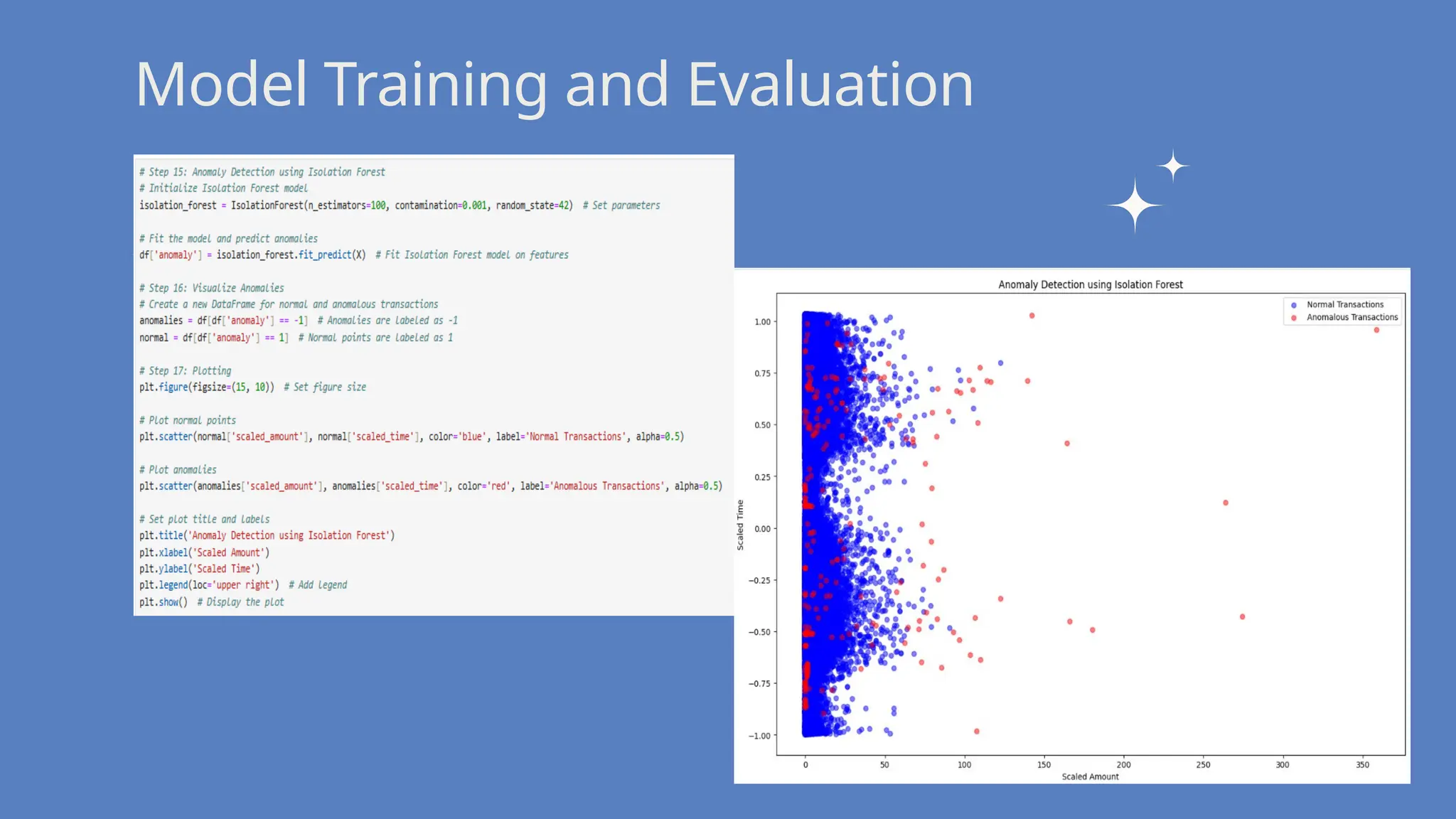
Algorithms Used: Isolation Forest
Isolation Forest is an unsupervised learning algorithm designed for anomaly
detection. It excels in identifying rare events, which is crucial in fraud detection,
where fraudulent transactions are anomalies compared to non-fraudulent ones.
How it works: For a given transaction, if it requires fewer splits to isolate it in the
tree, it’s considered an anomaly (fraudulent).The algorithm assigns an anomaly
score to each transaction, where transactions with high anomaly scores are flagged
as potential fraud.
It works well in high-dimensional datasets like credit card transactions where
fraudulent transactions are rare and behave differently from normal transactions.
14.
Write your topichere
Write your topic here
Model Training and Evaluation
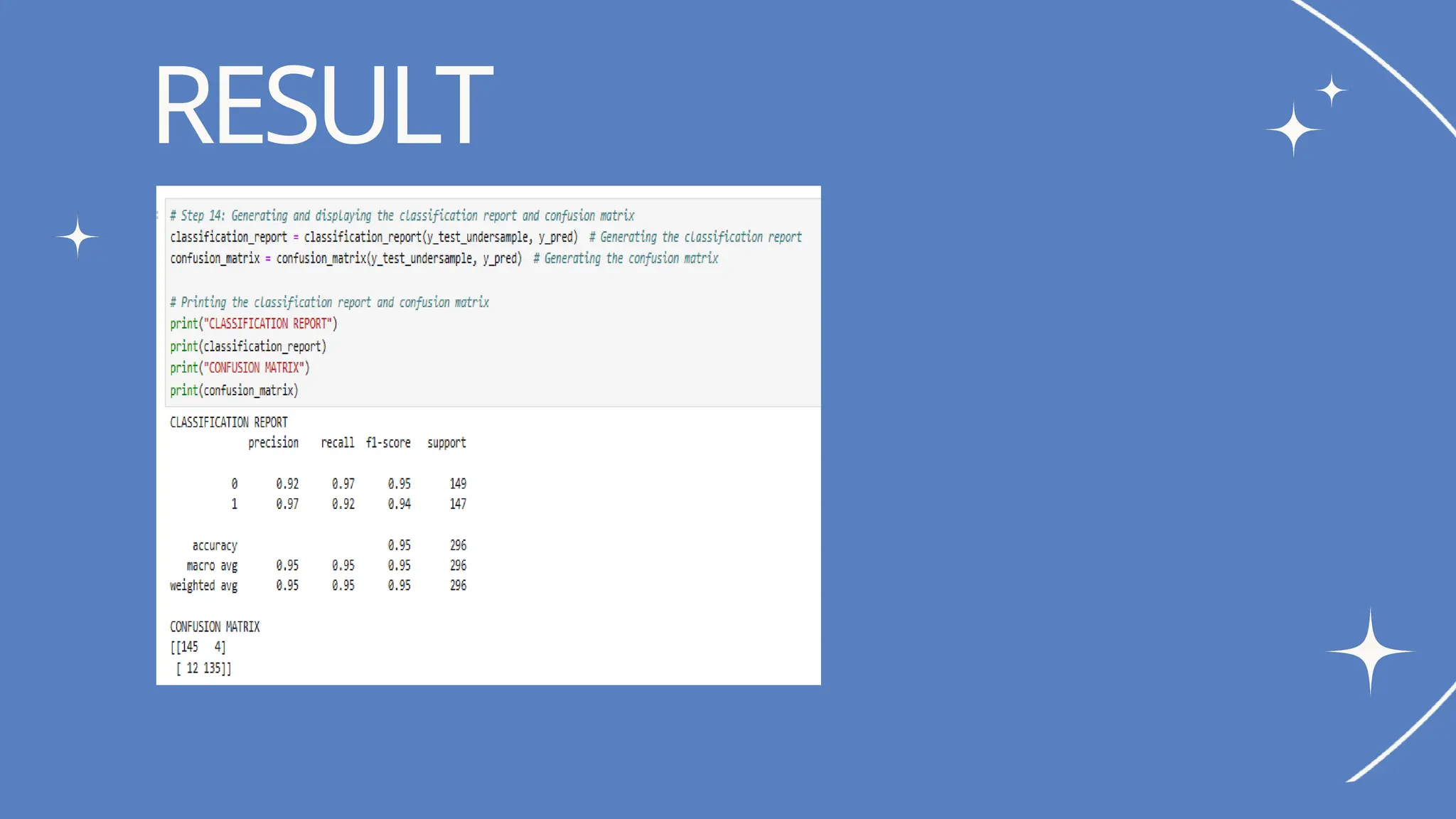
CONCLUSION
This credit cardfraud detection project effectively utilized Logistic Regression and
Isolation Forest algorithms to identify fraudulent transactions in a dataset characterized
by an imbalanced distribution of fraud cases. By preprocessing the data with
RobustScaler and implementing these models, we successfully distinguished between
legitimate and fraudulent transactions.
The Logistic Regression model provided interpretable insights into key features
influencing fraud, while Isolation Forest effectively detected anomalies, enhancing our
ability to capture emerging fraud patterns.
The results demonstrated a solid framework for improving transaction security,
highlighting the importance of combining different modeling approaches for robust
fraud detection.
17.
Write your topichere
Write your topic here
Reference
Pradeep B. (n.d.). Anomaly Detection. [online] Kaggle. Available at:
https://www.kaggle.com/code/pradeepb/anomaly-detection/notebook [Accessed 1
Oct. 2024]
Liu, F.T., Ting, K.M. and Zhou, Z.-H. (2008). 'Isolation Forest'. 2008 Eighth IEEE
International Conference on Data Mining, pp. 413-422. [online] Available at:
https://ieeexplore.ieee.org/document/4781136 [Accessed 1 Oct. 2024].
Scikit-learn contributors (n.d.). Isolation Forest. [online] Scikit-learn. Available at:
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationFores
t.html
[Accessed 1 Oct. 2024].









![Write your topic here
Write your topic here
Reference
Pradeep B. (n.d.). Anomaly Detection. [online] Kaggle. Available at:
https://www.kaggle.com/code/pradeepb/anomaly-detection/notebook [Accessed 1
Oct. 2024]
Liu, F.T., Ting, K.M. and Zhou, Z.-H. (2008). 'Isolation Forest'. 2008 Eighth IEEE
International Conference on Data Mining, pp. 413-422. [online] Available at:
https://ieeexplore.ieee.org/document/4781136 [Accessed 1 Oct. 2024].
Scikit-learn contributors (n.d.). Isolation Forest. [online] Scikit-learn. Available at:
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationFores
t.html
[Accessed 1 Oct. 2024].](https://image.slidesharecdn.com/creditcardfrauddetection-250720081455-5deecfd9/75/Credit-Card-Fraud-Detection-Presentation-17-2048.jpg)





























![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)