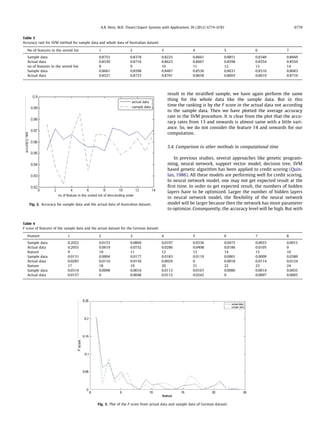
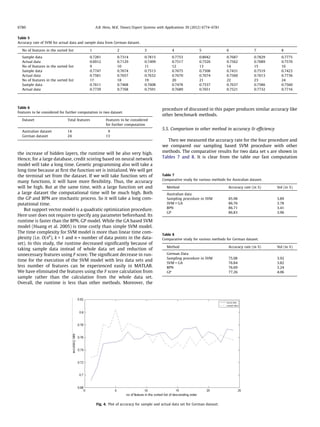
This document proposes a new approach to reduce computational time for credit scoring models based on support vector machines (SVM) and stratified sampling. The approach uses SVM incorporated with feature selection using F-scores and takes a sample of the dataset instead of the whole dataset to create the credit scoring model. The new method is shown to have competitive accuracy to other methods while significantly reducing computational time by optimizing features and reducing dataset size.