Improving Availability & Lowering Costs with Auto Scaling & Amazon EC2 (CPN201) | AWS re:Invent 2013

Running your Amazon EC2 instances in Auto Scaling groups allows you to improve your application's availability right out of the box. Auto Scaling replaces impaired or unhealthy instances automatically to maintain your desired number of instances (even if that number is one). You can also use Auto Scaling to automate the provisioning of new instances and software configurations as well as to track of usage and costs by app, project, or cost center. Of course, you can also use Auto Scaling to adjust capacity as needed - on demand, on a schedule, or dynamically based on demand. In this session, we show you a few of the tools you can use to enable Auto Scaling for the applications you run on Amazon EC2. We also share tips and tricks we've picked up from customers such as Netflix, Adobe, Nokia, and Amazon.com about managing capacity, balancing performance against cost, and optimizing availability.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Improving Availability & Lowering Costs with Auto Scaling & Amazon EC2 (CPN201) | AWS re:Invent 2013
Similar to Improving Availability & Lowering Costs with Auto Scaling & Amazon EC2 (CPN201) | AWS re:Invent 2013 (20)
More from Amazon Web Services
More from Amazon Web Services (20)
Recently uploaded
Recently uploaded (20)
Improving Availability & Lowering Costs with Auto Scaling & Amazon EC2 (CPN201) | AWS re:Invent 2013
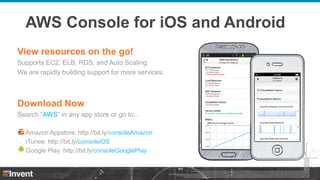
- 1. AWS Console for iOS and Android View resources on the go! Supports EC2, ELB, RDS, and Auto Scaling. We are rapidly building support for more services. Download Now Search “AWS” in any app store or go to... Amazon Appstore: http://bit.ly/consoleAmazon iTunes: http://bit.ly/consoleiOS Google Play: http://bit.ly/consoleGooglePlay
- 2. More Nines for Your Dimes: Improving Availability and Lowering Costs Using Auto Scaling and Amazon EC2 Derek Pai, AWS Cameron Stokes, The Weather Channel Keith Baker, Nokia Laurent Rouquette, Adobe Brandon Adams, Dreambox Learning November 15, 2013 © 2013 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
- 3. Some topics we’ll cover today • The Weather Channel – Maintaining application response times and fleet utilization rates – Handling cyclical demand and unexpected “weather events” • Nokia – Static Auto Scaling for non-critical applications – Auto Scaling for 99.9% Uptime • Adobe – Cost control and asymmetric scaling responses – AWS CloudFormation, custom scripts, and multiple inputs • Dreambox – Using performance testing to choose scaling strategies – Dealing with bouncy or steep curves
- 4. Cameron Stokes, The Weather Channel Keith Baker, Nokia Laurent Rouquette, Adobe Brandon Adams, Dreambox Learning © 2013 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
- 5. Who We Are
- 6. Who We Are
- 7. Who We Are • • • • Top 30 web property in the U.S. 2nd most viewed television channel in the U.S. 85% of U.S. airlines depend on our forecasts Major retailers base marketing spend and store displays based on our forecasts
- 8. Who We Are “The Weather Channel has an unduplicated audience of 163 million unique visitors monthly across The Weather Channel TV and weather.com platforms.” - Frank N. Magid Associates, Q3 2012
- 9. Why AWS?
- 10. Why AWS? It’s hurricane season in 2012. We’re capacity constrained. What can we do…
- 11. Why AWS? Identify “mobile” workload and move it to AWS... Radar images on wunderground.com.
- 12. Why AWS? Self-contained application Easy to replicate the datastore
- 17. Why Auto Scaling? Hurricane Sandy
- 18. Radar on AWS
- 19. Radar on AWS
- 20. Radar on AWS CPU Utilization
- 21. Radar on AWS Host Count
- 22. Radar on AWS
- 23. Radar on AWS
- 24. Radar on AWS
- 25. Challenges
- 31. Challenges Lots of knobs and switches to get right …or wrong
- 32. Cameron Stokes, The Weather Channel Keith Baker, Nokia Laurent Rouquette, Adobe Brandon Adams, Dreambox Learning © 2013 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
- 33. Maintaining non-critical applications with Static Autoscaling
- 34. Clickwork Annotation • • • • • • Internal annotation application ~100 users All hourly contractors Downtime is acceptable Port of existing single-server application Perfect first step into AWS
- 35. Architecture www.clickworksite.com S3 Repository Bucket S3 Backup Bucket Django Web App Postgresql DB EBS Volume 1 Manual Taggers Elastic Load Balancing (SSL Termination) EC2 Instance EBS Volume 2 Data Volume Auto Scaling Group Cloudwatch Availability Zone #1 Periodic Snapshots
- 36. Clickwork Details • Single AZ, Single Instance maintained by Autoscaling. Instance failures take ~15 min to recover. • Upgrades are done with planned downtime via a fully scripted re-deployment also ~15 min unless database schema is updated.
- 37. Clickwork Details • While uptime is flexible our data is precious – 2 EBS Volumes in Software RAID 1 – Periodic Postgres backups to S3 • Daily for first 18 months • Increased to hourly – Manual EBS snapshots today
- 38. Clickwork Details • Using Auto Scaling means the system cannot be configured by hand in any way and has to recover itself • Deployment uses Masterless Puppet – Puppet tree built into an RPM & pushed into S3 as Yum Repo – CloudInit • Set up S3 Yum Repositories • Install Puppet RPM • Run Puppet – Puppet • • • • Installs needed packages Mounts EBS volumes (id’s stored in launch config data) Configures / Mounts RAID 1 Starts Postgres & Apache
- 39. Clickwork Results • Successful deployment of Nokia’s first AWS application • Drastically Increased uptime over ‘server in a closet’ – Previously, outages exceeded 2 days each • A/C • Power • Network – Design goal was max 1 day outage – 2 outages over 1 hour • 2 hours (8.25.2013 EBS Event) • 9 hours (10.22.2012 EBS Event)
- 40. Autoscaling for 99.9% Uptime
- 41. Local Search • First customer facing application on AWS • Obvious need for Uptime
- 42. Local Search Architecture US-West-2 Frontend Group Zookeeper1 Zookeeper1 Frontend Group Zookeeper2 EU-West-1 Zookeeper2 AP-Southeast-1 Backend Groups Zookeeper3 Zookeeper3 US-East-1a US-East-1 Backend Groups US-East-1b
- 43. Local Search Single Instance Auto Scaling Groups • Instances in 1 node Auto Scaling groups automatically register themselves in DNS via Route53 based on their Auto Scaling group’s name. • Auto Scaling group names are formed as a pattern with cluster name and node type so a cluster1-frontend node knows to look for cluster1-zookeeper1, cluster1zookeeper2… • An alternative was querying the Auto Scaling group for instances. Using DNS allowed us to use more standard tools.
- 44. Local Search Zookeepers • • • • • • • • Three single instance Auto Scaling groups Zookeeper needs a set, consistent list of servers across all servers (zookeeper1, zookeeper2, zookeeper3) At launch, zookeeper didn’t re-resolve hostnames on the server side. We proxy Zookeeper through localhost inetd & netcat to cause a DNS lookup on each connection Client had been fixed at this point Requires a short DNS timeout but rather low usage (only on reconnects) Considered one zookeeper per AZ. One region we deploy in only has two AZs so we can’t lose either AZ and maintain quorum. So we run one cluster in each AZ. We have lost all three zookeepers in one AZ, which caused one AZ to go offline. This failure was handled by the ELB. Auto Scaling fixed this in ~15 min. Avoided EIPs
- 45. Local Search Logging • • • • • • Again a single instance Auto Scaling group Buffers logs for entire cluster Does compression, encryption, and uploads to S3 Forwards to central logging system for analysis Single point of investigation for entire cluster All instances also run scribe to buffer if logging node is lost
- 46. Local Search Updates • Moving to a job that monitors the available data vs. the present data • When new data is present the job takes a lock in zookeeper for cluster size changes. It then increases the node count and waits for the Auto Scaling message that capacity has changed. It unlocks the cluster size changes and monitors the loading of the new node. • Other nodes can then lock and modify the capacity to get their own replacement nodes • Once new nodes are loaded, the old nodes take a lock and decease the cluster size with a targeted kill to themselves • Care taken to track a failed replacement node
- 47. Local Search Success • All detected health problems have been successfully replaced by autoscaling with zero intervention. We’ve been paranoid so it still pages us, it’s beginning to feel silly • Zookeeper setup has performed flawlessly • Undetected problems are our biggest challenge – Disk failure – Intermittent connectivity failures
- 48. Cameron Stokes, The Weather Channel Keith Baker, Nokia Laurent Rouquette, Adobe Brandon Adams, Dreambox Learning © 2013 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
- 49. Intro – Cloud Ops
- 50. Goals • Meet demand • Control costs • Maintain capacity
- 51. Architecture
- 52. Scaling the web layer • Number of HTTP requests • Average CPU load • Network in/out
- 53. Scaling the worker layer • SQS queue length, specifically "approximate number of messages visible"
- 54. Scaling Down: who wants to volunteer? • Know your usage • Scale up fast, scale down slow
- 55. Cost Control • Scheduled scaling: we analyzed our traffic and picked numbers. – scale up in the morning, scale down in the evening • Policies for slow scale down • Stage environments: downscale everything to “min-size” daily (or more)
- 56. How – AWS CloudFormation "ScaleUpPolicy" : { "Type" : "AWS::AutoScaling::ScalingPolicy", "Properties" : { "AdjustmentType" : "ChangeInCapacity", "AutoScalingGroupName" : { "Ref" : "WorkerAutoScalingGroup" }, "Cooldown" : {"Ref": "cooldown"}, "ScalingAdjustment" : { "Ref" : "adjustup" } } }, "WorkerAlarmScaleUp": { "Type": "AWS::CloudWatch::Alarm", "Properties": { "EvaluationPeriods":{"Ref" : "evalperiod"}, "Statistic": "Sum", "Threshold": {"Ref" : "upthreshold"}, "AlarmDescription": "Scale up if the work load of transcode queue is high", "Period": {"Ref" : "period"}, "AlarmActions": [ { "Ref": "ScaleUpPolicy" }, { "Ref" : "scalingSNStopic" } ], "Namespace": "AWS/SQS", "Dimensions": [ { "Name": "QueueName", "Value": {"Ref" : "queuename" }}], "ComparisonOperator": "GreaterThanThreshold", "MetricName": "ApproximateNumberOfMessagesVisible" } },
- 57. How – custom scripts . . . [2013-10-08T00:00:14.31] INFO -- : Scaling Worker1 with CAPACITY 10 (schedule=BIZPM) [2013-10-08T00:00:24.70] INFO -- : PROD-A-Worker1-3276-ASG-1VUVI7JI1M19U has max size 0; most likely not active environment; no action taken PROD-B-Worker1-3484-ASG-H2QX6HC82SLQ is active; resetting capacity: current: 20; new: 10 Result: OK-Desired Capacity Set [2013-10-08T00:00:24.70] INFO -- : Scaling Worker2 with CAPACITY 7 (schedule=BIZPM) [2013-10-08T00:00:34.98] INFO -- : PROD-A-Worker2-3275-ASG-LY3NHN8C7A82 has max size 0; most likely not active environment; no action taken PROD-B-Worker2-3483-ASG-70MUBNNP3QV0 is active; resetting capacity: current: 15; new: 7 Result: OK-Desired Capacity Set . . .
- 58. How – Custom Metrics . . . Sat Oct 6 05:51:03 UTC 2012 Number of AZs: 4 Number of Web Servers: 16 Number of Healthy Web Servers: 16 ELB Request Count: 9523.0 Request Count Per Healthy Web Server: 595.1875 Network In Per Healthy Web Server: 51 MB Network Out Per Healthy Web Server: 1 MB CPU Per Healthy Web Server: 25.23875 Publishing Custom Metrics: InstanceRequestCount, HealthyWebServers, InstanceNetworkIn, InstanceNetworkOut, InstanceCPUUtilization to namespace WebServer in us-east-1 . . .
- 59. How – multi-input scaling • Scale up • +2 instances if more than 50 visible messages for more than 5 min • +50% instances if more than 1000 msg for more than 2 min • + fixed 100 instances if more than 10,000 msg for more than 1 min • Scale down • –10 instance if 0 msg for more than 10 min • – 25% if 0 msg for more than 30 min
- 60. Advice • • • • • Use CloudFormation! Know your system Watch your scaling history Scaling up is easy, scaling down not so much Mantra: scale up fast; scale down slow
- 61. Cameron Stokes, The Weather Channel Keith Baker, Nokia Laurent Rouquette, Adobe Brandon Adams, Dreambox Learning © 2013 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
- 62. Scaling strategies we use 1. Scaling with CloudWatch alarms 2. Scheduled scaling 3. Scaling with multiple CloudWatch alarm conditions
- 63. A little background on our application • Ruby on Rails • Unicorn • We teach kids math!
- 64. A workload well suited for auto scaling
- 65. Scaling with CloudWatch alarms
- 66. What’s an alarm? • Measures some metric in CloudWatch • Go above or beyond a threshold, alarm fires • Which can trigger an autoscaling action
- 67. Performance test to get a baseline • Discover the ideal number of worker processes per server – Too few and resources go unused – Too many and performance suffers under load • Obtain the maximum load sustainable per server – Our performance tests measures number of concurrent users • Find the chokepoint – For us, this was CPU utilization
- 69. Identify the breaking point Breaking point was at about 400 users per server
- 70. Our first method to find scale points • Provision a static amount of servers that we know can handle peak load • Adjust scale up and scale down alarms based on observed highs and lows • This worked, but was super inefficient, both in time and money spent
- 71. Let’s do some math – identify variables Independent • Concurrent users Dependent • CPU utilization • Memory utilization • Disk I/O • Network I/O
- 72. Let’s do some math – find the slope • Adding about 1600 users per hour • Which is about 27 per minute • We know that we can handle a max of about 400 users per server at 80% CPU usage • Which is about 0.2% CPU usage per user
- 73. Let’s do some math – when to scale? • We know (from other testing) that it takes us about 5 minutes for a new node to come online • We’re adding 27 users per minute • Which means we need to start spinning up new nodes when we’re about 135 users (27 x 5) per node short of max • Which is at about 53% utilization: (80% – (0.2% * 135))
- 74. Scaling point equations 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 𝑚𝑎𝑥𝑖𝑚𝑢𝑚 𝑢𝑠𝑒𝑟𝑠 𝑝𝑒𝑟 𝑛𝑜𝑑𝑒 − (𝑢𝑠𝑒𝑟𝑠 𝑎𝑑𝑑𝑒𝑑 𝑝𝑒𝑟 𝑚𝑖𝑛𝑢𝑡𝑒 ∗ 𝑠𝑝𝑖𝑛 𝑢𝑝 𝑡𝑖𝑚𝑒) 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 400 − (27 ∗ 5) 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 265 users per node 𝑢𝑠𝑒𝑟𝑠 𝑢𝑠𝑒𝑟𝑠 = − 𝑛𝑜𝑑𝑒 𝑛𝑜𝑑𝑒 𝑢𝑠𝑒𝑟𝑠 𝑚𝑖𝑛𝑢𝑡𝑒𝑠 ∗ 𝑚𝑖𝑛𝑢𝑡𝑒 𝑛𝑜𝑑𝑒 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 𝑢𝑠𝑒𝑟𝑠 𝑝𝑒𝑟 𝑛𝑜𝑑𝑒 ∗ 𝑐𝑝𝑢 𝑝𝑒𝑟 𝑢𝑠𝑒𝑟 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 265 ∗ .2 𝑠𝑐𝑎𝑙𝑖𝑛𝑔 𝑝𝑜𝑖𝑛𝑡 = 53% cpu per node 𝑐𝑝𝑢 𝑢𝑠𝑒𝑟𝑠 𝑐𝑝𝑢 = ∗ 𝑛𝑜𝑑𝑒 𝑛𝑜𝑑𝑒 𝑢𝑠𝑒𝑟
- 75. How much to scale up by? • The lowest we can scale up by is 1 node per AZ; otherwise, we would be unbalanced • For us, this is an extra 800 users of capacity in five minutes, plenty enough to keep up with our rate of adding 1600 users per hour • Adding 800 users of capacity every five minutes, we could support 9600 additional users per hour
- 76. Evaluate your predictions • In the real world, we’ve inched up from scaling at 53% • Our perf test is a little harsher than the real world • Numbers derived from the perf test are only as accurate as the simulation of traffic you specify in your perf test
- 78. Acceleration in load is not constant Request count for a 24 hour period
- 79. We can’t use one size fits all • Scale too aggressively – Overprovisioning: increases cost – Bounciness: we add more than we need and have to partially scale back shortly after scaling up, which increases cost • Scale too timidly – Poor performance – Outages due to lack of capacity
- 80. Bounciness and steepness • Add scheduled scaling points to eliminate bounciness • Scheduled scale for the steepest points of your demand curve • Let dynamic scaling take care of the less steep parts of the curve
- 83. Scaling with multiple CloudWatch alarm conditions
- 84. The need for multiple alarms • Sometimes we get an unexpected spike in load that can’t be handled by our normal scaling rules • We thought we could just add another level of alarm at a higher CPU utilization level • However…
- 85. Difficulty with multiple alarms • There is no mechanism to choose which alarm triggers an autoscaling action when multiple alarms are triggered • Once an autoscaling action is triggered by an alarm, we enter the cool down period, precluding other alarms from triggering autoscaling actions
- 86. The solution • Multiple alarms, multiple groups • We have a “high demand” group that normally has zero instances • If we reach a certain threshold, the high demand group scales up to cover the load that the regular group can’t handle
- 87. Putting it all together
- 88. Demand curve hugs the usage curve…
- 89. …and a (mostly) flat response curve
- 90. Please give us your feedback on this presentation CPN201 As a thank you, we will select prize winners daily for completed surveys!