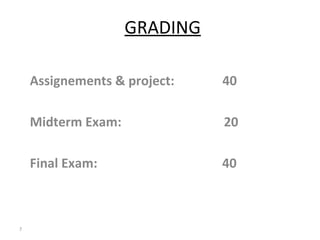
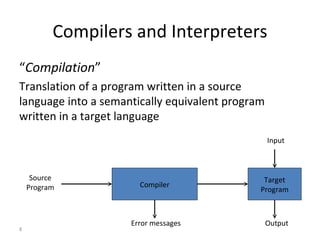
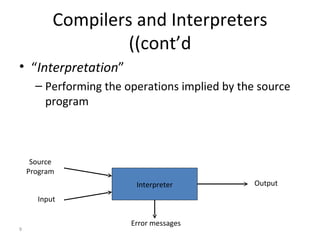
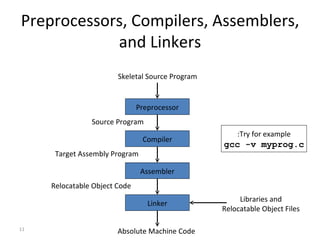
- The document outlines the goals, outcomes, prerequisites, topics covered, and grading for a compiler design course.
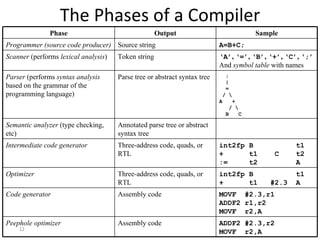
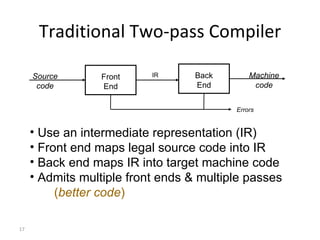
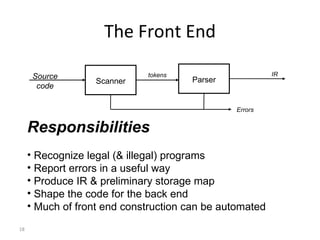
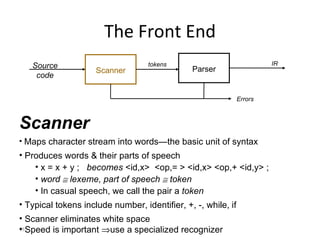
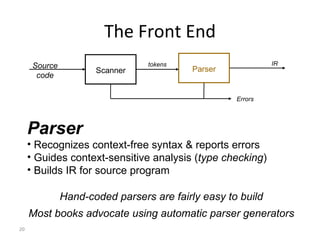
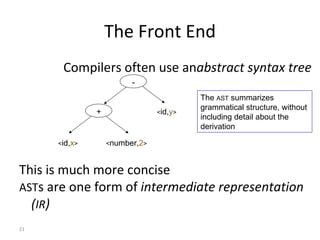
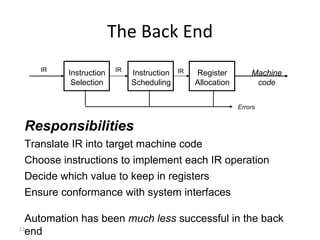
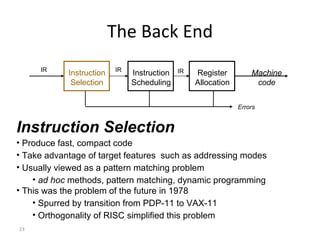
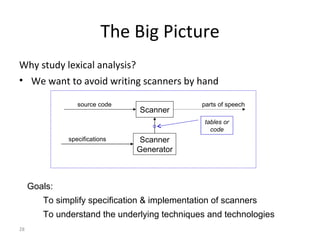
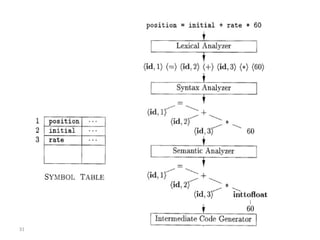
- The major goals are to provide an understanding of compiler phases like scanning, parsing, semantic analysis and code generation, and have students implement parts of a compiler for a small language.
- By the end of the course students will be familiar with compiler phases and be able to define the semantic rules of a programming language.
- Prerequisites include knowledge of programming languages, algorithms, and grammar theories.
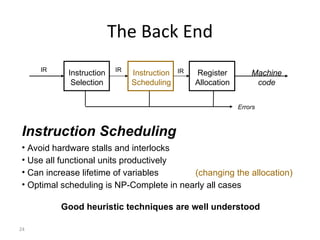
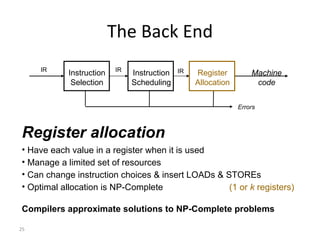
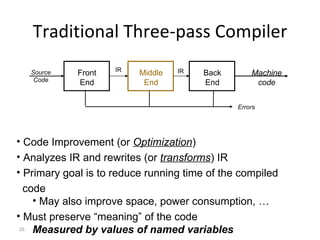
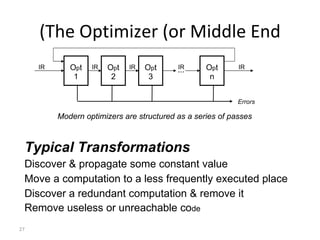
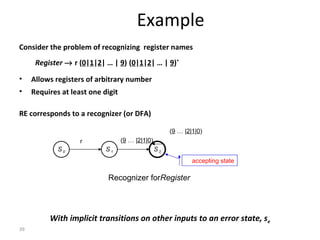
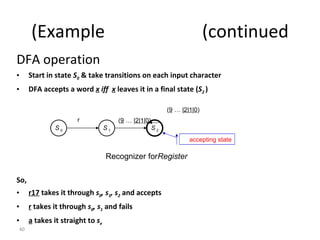
- The course covers topics like scanning, parsing, semantic analysis, code generation and optimization.