Downloaded 70 times



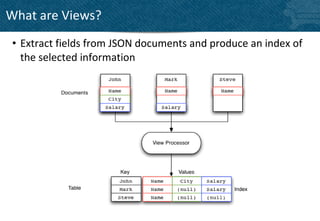
![JSON Documents
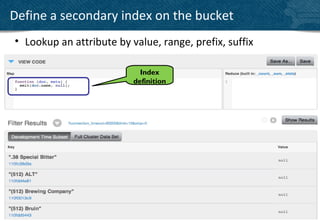
• Map more closely to objects or entities
• CRUD Operations, lightweight schema
{
“fields” : [“with basic types”, 3.14159, true],
“like” : “your favorite language”
}
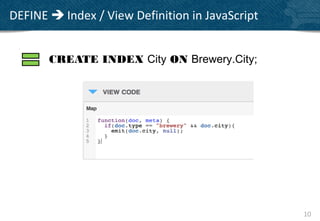
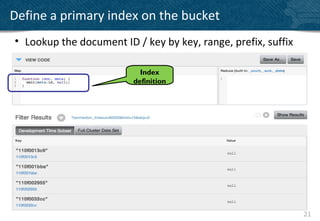
• Stored under an identifier key
client.set(“mydocumentid”, myDocument);
mySavedDocument = client.get(“mydocumentid”);
3](https://image.slidesharecdn.com/couchbase-20-indexingquerying-deep-dive-12012012-121202192412-phpapp01/85/Couchbase-Server-2-0-Indexing-and-Querying-Deep-dive-3-320.jpg)


![QUERY Dynamic Queries with Optional Aggregation
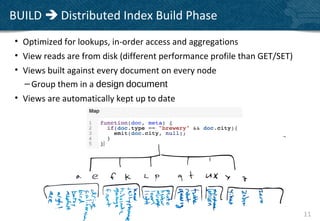
• Eventually consistent with respect to document updates
• Efficiently fetch a document or group of similar documents
• Queries will use cached values from B-tree inner nodes when possible
• Take advantage of in-order tree traversal with group_level queries
Query ?startkey=“J”&endkey=“K”
{“rows”:[{“key”:“Juneau”,“value”:null}]}
12](https://image.slidesharecdn.com/couchbase-20-indexingquerying-deep-dive-12012012-121202192412-phpapp01/85/Couchbase-Server-2-0-Indexing-and-Querying-Deep-dive-12-320.jpg)








![View writing guidance
• Do not include the document in the view value
– Instead either use the GET / SET API or the API that includes documents filtered by
the query [example: willIncludeDocs()]
– Emit either null or the ID instead (meta.id) in your key or value data
emit(doc.name, null)
emit(doc.name, null)
• Don’t emit too much data into a view value
– Use views to filter documents
– Then use the data path to access the matched documents
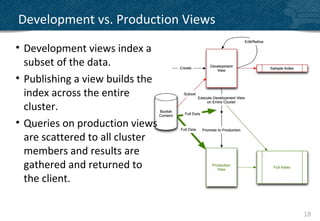
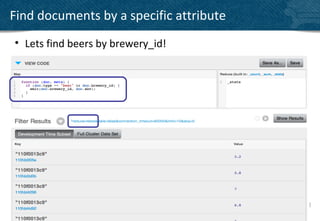
• Use Document Types to make views more selective
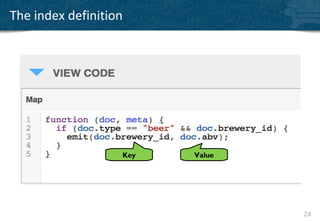
function(doc, meta)
function(doc, meta)
{
{
if(doc.type == “player”)
if(doc.type == “player”)
emit(doc.experience, null);
emit(doc.experience, null);
}
}
28](https://image.slidesharecdn.com/couchbase-20-indexingquerying-deep-dive-12012012-121202192412-phpapp01/85/Couchbase-Server-2-0-Indexing-and-Querying-Deep-dive-28-320.jpg)





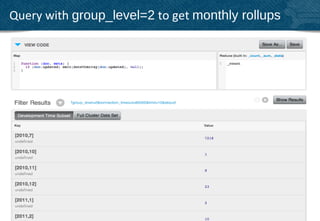
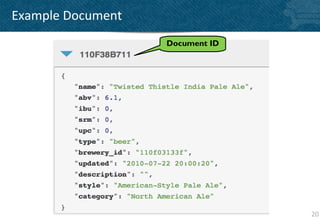
![dateToArray() is your friend
()
rr ay
oA
eT
dat
• String or Integer based timestamps
• Output optimized for group_level queries
• array of JSON numbers:
[2012,9,21,11,30,44] 38](https://image.slidesharecdn.com/couchbase-20-indexingquerying-deep-dive-12012012-121202192412-phpapp01/85/Couchbase-Server-2-0-Indexing-and-Querying-Deep-dive-38-320.jpg)
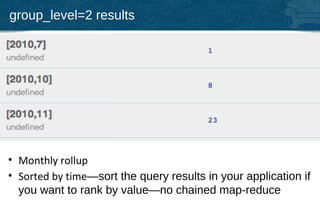
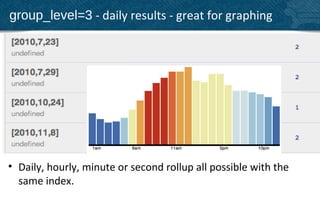

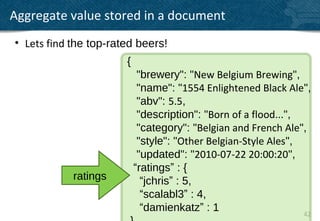
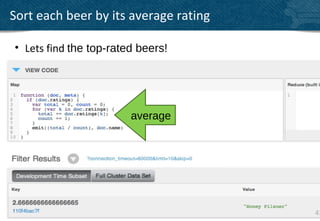



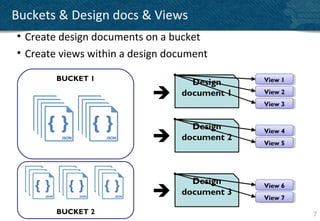
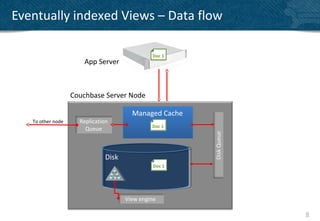
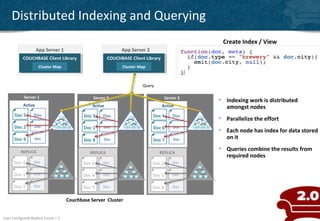
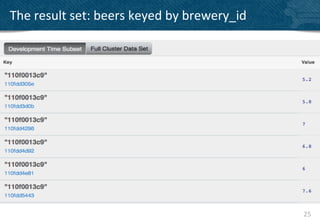
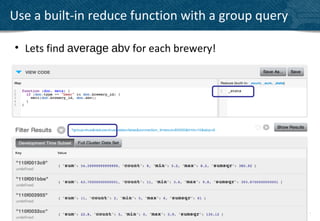
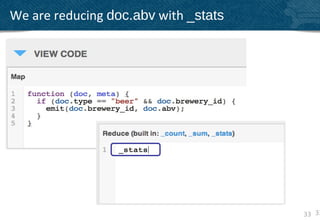
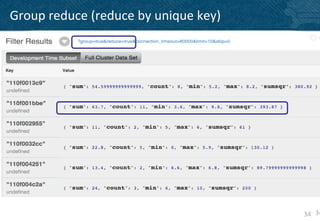
The document provides an overview of indexing and querying in Couchbase Server 2.0. It discusses view basics like index definition, building, and querying phases. It covers topics like replica indexes, failover, primary and secondary indexes, and best practices. Examples are provided for simple indexing, aggregations, time-based rollups, and leaderboards using views.































![[@IndeedEng] From 1 To 1 Billion: Evolution of Indeed's Document Serving System](https://cdn.slidesharecdn.com/ss_thumbnails/from1to1billion-documentservingindeedeng-130305160434-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















