Downloaded 281 times


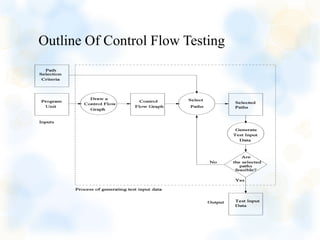









Control flow testing is a white box testing technique that uses the program's control flow graph to design test cases that execute different paths through the code. It involves creating a control flow graph from the source code, defining a coverage target like branches or paths, generating test cases to cover the target, and executing the test cases to analyze results. It is useful for finding bugs in program logic but does not test for missing or extra requirements.






























































































