Download to read offline



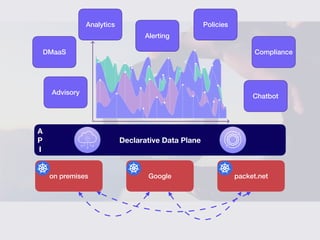

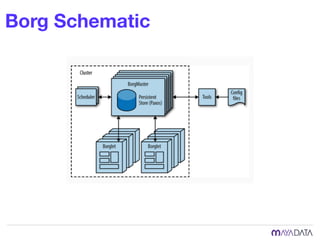






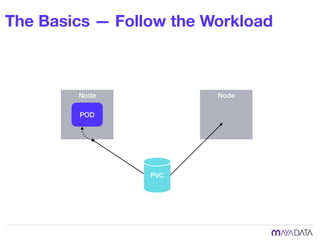






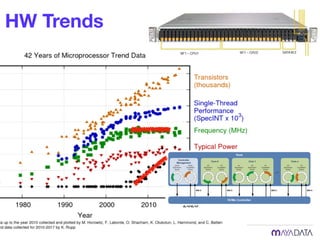

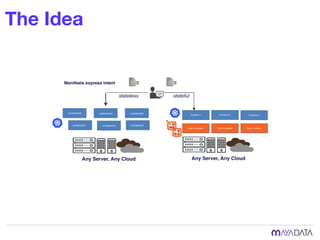



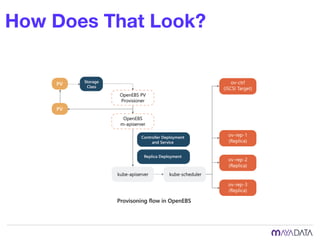

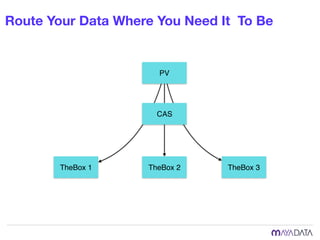
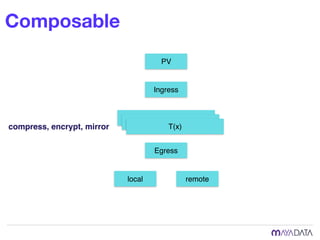

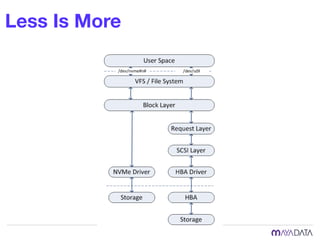

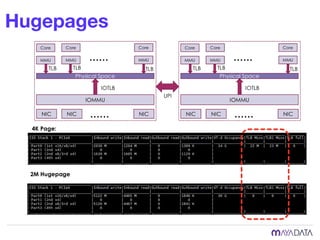


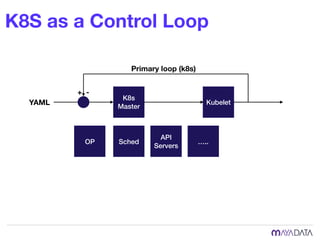
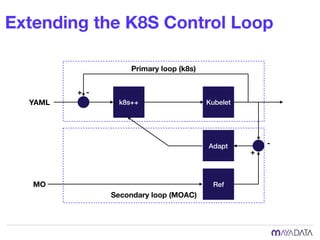
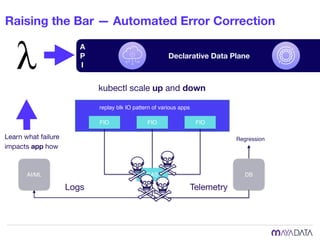



The document discusses container attached storage in Kubernetes (k8s) and highlights the challenges of managing persistent storage for stateful applications. It elaborates on the need for abstraction in storage solutions to minimize vendor lock-in and enhance agility within cloud-native environments. Additionally, it addresses various strategies and frameworks, such as Persistent Volume Claims (PVCs) and the Container Storage Interface (CSI), to improve storage management in containerized applications.








![Microcontainers, Microservices, Microservers? Less [Linux] is more!](https://cdn.slidesharecdn.com/ss_thumbnails/belfast-devops-presentation-150916011027-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















