Download as PDF, PPTX




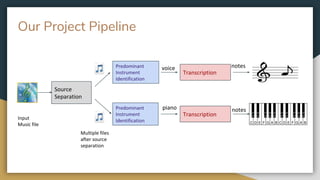


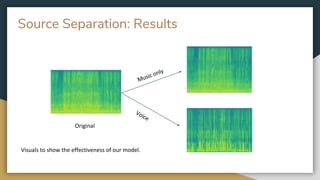

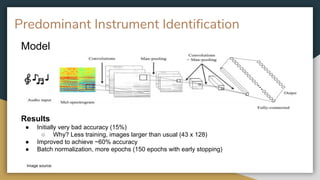







The project aims to develop a deep learning system for automatic music transcription of polyphonic music, specifically focusing on separating and identifying predominant instruments before transcription. Initial challenges included the complexity of polyphonic music, leading to a CNN model that improves accuracy of instrument identification and transcription over time. Future plans involve enhancing source separation methods and making transcription models more flexible for multiple instruments.



































































