Download as PDF, PPTX







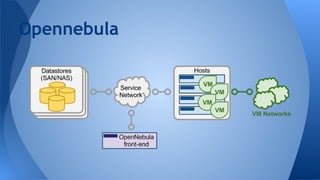


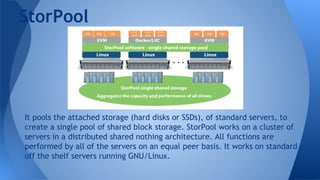




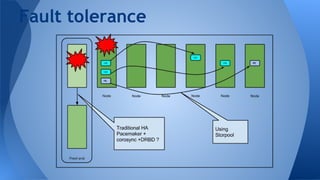











Hyperconvergence integrates compute, storage, networking and virtualization resources from scratch in a commodity hardware box supported by a single vendor. It offers scalability, performance, centralized management, reliability and is software-focused. StorPool is a storage software that can be installed on servers to pool and aggregate the capacity and performance of drives. It provides standard block devices and replicates data across drives and servers for redundancy. StorPool integrates fully with Opennebula to provide a robust hyperconverged infrastructure on commodity hardware using distributed storage.










































































































