Downloaded 484 times











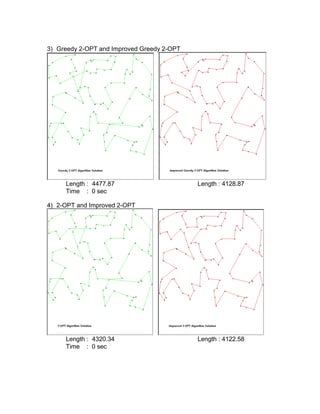
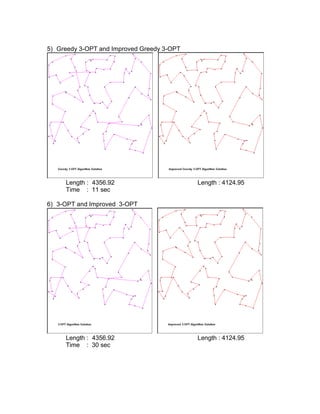

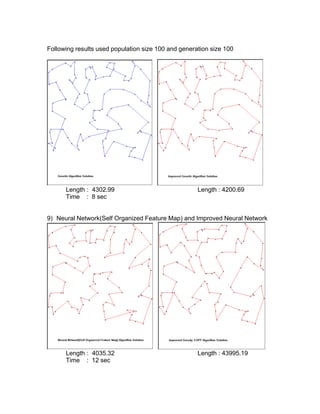


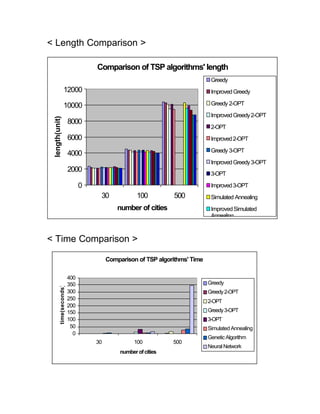


The document compares different heuristic algorithms for solving the traveling salesman problem (TSP), including greedy, 2-opt, 3-opt, genetic algorithm, simulated annealing, and neural networks. It implemented these algorithms and evaluated their computational efficiency on TSP problems of varying sizes (2-10,000 nodes). For small TSP problems (n<=50 nodes), the greedy 2-opt algorithm performed well with a high solution quality and short computation time. The neural network approach showed the best efficiency across all problem sizes. The algorithms were also improved using non-crossing methods, which always resulted in better solutions.
































































