




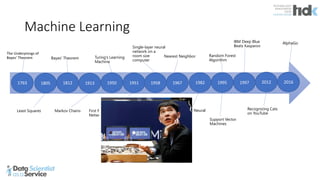








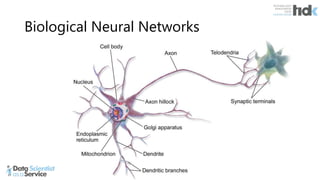

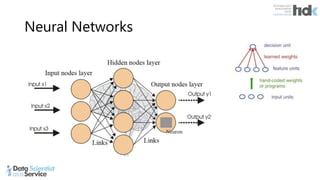
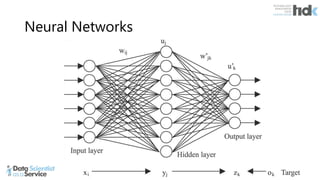
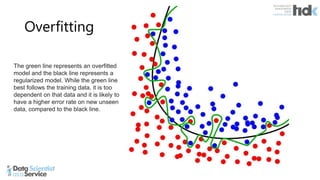


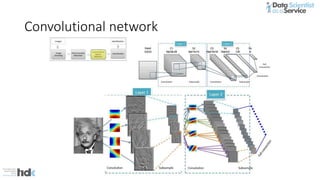

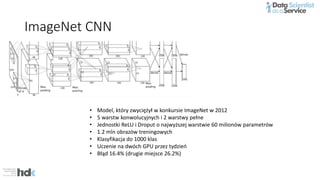

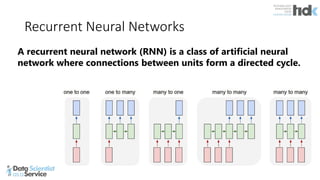
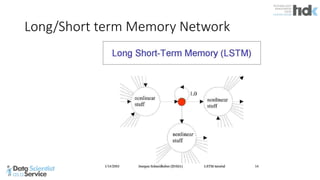
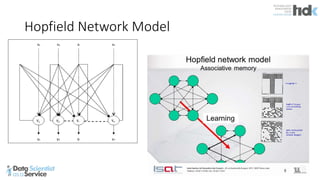
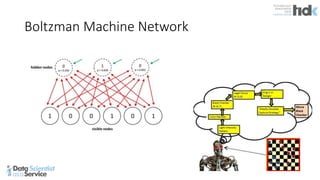
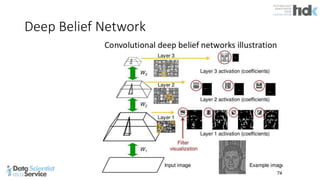
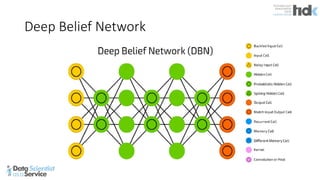
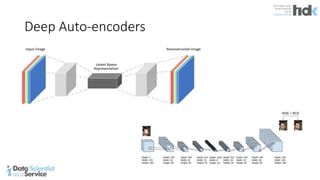
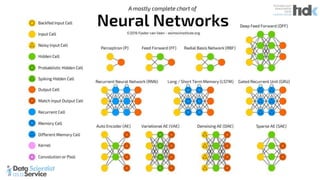
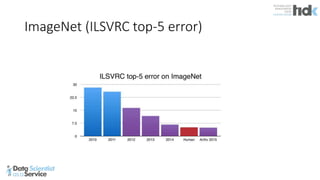


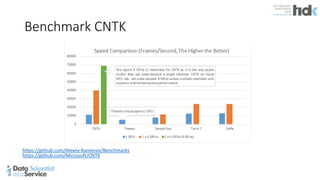
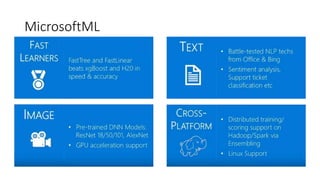




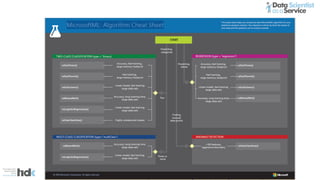



















The document provides an overview of Microsoft's Cognitive Toolkit, a deep learning framework designed for machine learning applications. It covers various machine learning concepts, artificial neural networks, and framework capabilities, including support for deep learning, reinforcement learning, and big data processing. Additionally, it highlights specific machine learning use cases and methodologies for model evaluation and training.























































































