陳昇瑋 / 人工智慧民主化在台灣
AlphaZero:One Algorithm, Three Games
16
Mastering Chess and Shogi by self play
with reinforcement learning
Master Chess and Shogi by self play with
reinforcement learning
(Slide Credit: Google)
陳昇瑋 / 人工智慧民主化在台灣
MachineLearning
22
A type of algorithms that gives computers the
ability to learn rules from experience, rather than
being hard coded.
Find the common patterns
from the left waveforms
It seems impossible to
write a program for
speech recognition
你好 你好
你好 你好
You quickly get lost in the
exceptions and special cases.
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 人工智慧民主化在台灣
Letthe machine learn by itself
你好
大家好
人帥真好
You said
“你好”
A large amount of
audio data
You only have to write the
learning algorithm ONCE
Derive rules
from datasets
(Slide Credit: Hung-Yi Lee)
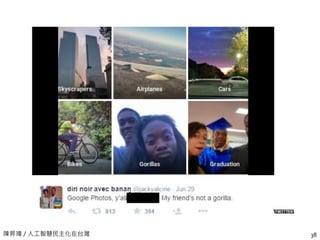
陳昇瑋 / 人工智慧民主化在台灣
AGaydar
29
Based on 35,000 facial images
Human judges: 61% for men, 54% for women
AI judges: 91% for men, 83% for women
A heat map of where the algorithm looks to detect signs of homosexuality (Kosinski and Wang)
https://osf.io/zn79k/
Example Application
Input Output
16x 16 = 256
1x
2x
256x
……
Ink → 1
No ink → 0
……
y1
y2
y10
Each dimension represents
the confidence of a digit.
is 1
is 2
is 0
……
0.1
0.7
0.2
The image
is “2”
(Slide Credit: Hung-Yi Lee)
40.
Example Application
• HandwritingDigit Recognition
Machine “2”
1x
2x
256x
……
……
y1
y2
y10
is 1
is 2
is 0
……
What is needed is a
function ……
Input:
256-dim vector
output:
10-dim vector
Neural
Network
(Slide Credit: Hung-Yi Lee)
Modularization
• Deep →Modularization
1x
2x ……
Nx
……
……
……
……
……
……
The most basic
classifiers
Use 1st layer as module
to build classifiers
Use 2nd layer as
module ……
The modularization is
automatically learned from data.
→ Less training data?
(Slide Credit: Hung-Yi Lee)
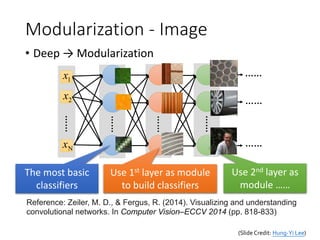
44.
Modularization - Image
•Deep → Modularization
1x
2x
……
Nx
……
……
……
……
……
……
The most basic
classifiers
Use 1st layer as module
to build classifiers
Use 2nd layer as
module ……
Reference: Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding
convolutional networks. In Computer Vision–ECCV 2014 (pp. 818-833)
(Slide Credit: Hung-Yi Lee)
45.
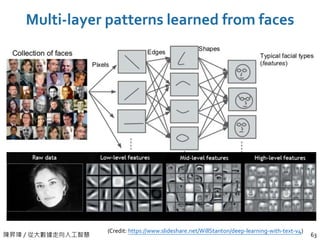
陳昇瑋 / 從大數據走向人工智慧
Multi-layerpatterns learned from faces
63
(Credit: https://www.slideshare.net/WillStanton/deep-learning-with-text-v4)
Fat + Shortv.s. Thin + Tall
1x 2x …… Nx
Deep
1x 2x …… Nx
……
Shallow
Which one is better?
The same number
of parameters
(Slide Credit: Hung-Yi Lee)
48.
Fat + Shortv.s. Thin + Tall
Seide, Frank, Gang Li, and Dong Yu. "Conversational Speech Transcription
Using Context-Dependent Deep Neural Networks." Interspeech. 2011.
Layer X Size
Word Error
Rate (%)
Layer X Size
Word Error
Rate (%)
1 X 2k 24.2
2 X 2k 20.4
3 X 2k 18.4
4 X 2k 17.8
5 X 2k 17.2 1 X 3772 22.5
7 X 2k 17.1 1 X 4634 22.6
1 X 16k 22.1
(Slide Credit: Hung-Yi Lee)
A Straightforward Answer
•Do Deep Nets Really Need To Be Deep? (by Rich Caruana)
• http://research.microsoft.com/apps/video/default.aspx?id=
232373&r=1
keynote of Rich Caruana at ASRU 2015
(Slide Credit: Hung-Yi Lee)
51.
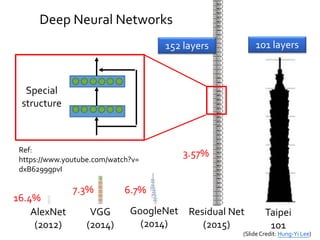
陳昇瑋 / 網路購書大數據
DeepNeural Networks
69
1. Deep = many layers
2. Deep = hierarchical of concepts
陳昇瑋 / 人工智慧民主化在台灣
1958:Perceptron (linear model)
1969: Perceptron has limitation
1980s: Multi-layer perceptron
Do not have significant difference from DNN today
1986: Backpropagation
Usually more than 3 hidden layers is not helpful
1989: 1 hidden layer is “good enough”, why deep?
2006: RBM initialization
2009: GPU
2011: Start to be popular in speech recognition
2012: win ILSVRC image competition
2015.2: Image recognition surpassing human-level performance
2016.3: Alpha GO beats Lee Sedol
2016.10: Speech recognition system as good as humans
Ups and downs of Deep Learning
(Slide Credit: Hung-Yi Lee)
55.
What was actuallywrong with backprop
in 1986?
We all drew the wrong conclusions about why it
failed. The real reasons were:
Our labeled datasets were thousands of times too
small.
Our computers were millions of times too slow.
We initialized the weights in a stupid way.
We used the wrong type of non-linearity.
73
(Credit: Geoff Hinton,What Was ActuallyWrongWith Backpropagation in 1986?)
陳昇瑋 / 從大數據走向人工智慧
Whatdo CNNs learn?
Neurons act like “custom-trained filters”;
react to very different visual cues, depending on data.
(Slide Credit: AlbertY. C. Chen)
61.
陳昇瑋 / 從大數據走向人工智慧
Whatdo CNNs learn?
Neurons act like “custom-trained filters”; react to
very different visual cues, depending on data.
(Slide Credit: AlbertY. C. Chen)
陳昇瑋 / 人工智慧民主化在台灣
ColorfulImage Colorization
114
Zhang, Richard, Phillip Isola, and Alexei A. Efros. "Colorful image colorization." European
Conference on Computer Vision. Springer International Publishing, 2016.
76.
陳昇瑋 / 人工智慧民主化在台灣
ColorfulImage Colorization
115
http://richzhang.github.io/colorization/
A 313-class classification problem
Input: 224x224x1 (L)
Model output: 64x64x313
Pixel values: annealed mean of 313
colors
陳昇瑋 / 人工智慧民主化在台灣
WhySupervised Learning is Not Enough
145
https://www.reddit.com/r/MachineLearning/comments/2lmo0l/ama_geoffrey_hinton/
The brain has about 1014 synapses and we only live for about
109 seconds. So we have a lot more parameters than data.
This motivates the idea that we must do a lot of
unsupervised learning since the perceptual input (including
proprioception) is the only place we can get 105 dimensions
of constraint per second.
-- Geoffrey Hinton
106.
陳昇瑋 / 人工智慧民主化在台灣
TypicalApplications of RL
Play games: Atari, poker, Go, ...
Explore worlds: 3D worlds, Labyrinth, ...
Control physical systems: manipulate, walk, swim, ...
Interact with users: recommend, optimize, personalize,
...
147
(Slide credit: David Silver)
陳昇瑋 / 人工智慧民主化在台灣
MoreRL Applications
Flying Helicopter
Driving
Google Cuts Its Giant Electricity Bill With DeepMind-
Powered AI
Parameter tuning in manufacturing lines
Text generation
Hongyu Guo, “Generating Text with Deep Reinforcement
Learning”, NIPS, 2015
Marc'AurelioRanzato,SumitChopra,Michael Auli,Wojciech
Zaremba, “Sequence Level Training with Recurrent Neural
Networks”, ICLR, 2016
151(Slide Credit: Hung-Yi Lee)
110.
陳昇瑋 / 人工智慧民主化在台灣
Bigdata vs. Machine learning vs. AI
Big data: records of experience
Machine learning: “A type of algorithms
that gives computers the ability to learn
from experience, rather than being explicitly
programmed."
Artificial intelligence
Turing test
153
陳昇瑋 / 人工智慧民主化在台灣
1/3of the GDP
Manufacturing GDP of $178B, almost 1/3 of total
GDP
30% of the employment are in the manufacturing
sector
Cheap labor cost of $9.42/hr with average labor
productivity of almost $60k in GDP/person
17% corporate tax rate
155
113.
陳昇瑋 / 人工智慧民主化在台灣
McKinsey’sFour Dimensions in
AI Value Chain
156
Smart R&D and
forecasting
Project
Optimized
production with
lower cost and
higher efficiency
Produce
Products and
services at the
right price, time,
and targets
Promote
Enriched and
tailored user
experience
Provide
114.
陳昇瑋 / 人工智慧民主化在台灣
TheFour-P Dimensions in Manufacturing
Improve product design
Automate supplier assessment and price negotiation
Anticipate parts requirements
Improve manufacturing processes
Automate assembly lines
limit product rework
Optimize pricing
Predict sales of maintenance services
Refine sales-leads prioritization
Optimize flight/fleet planning and route
Enhance maintenance engineering
Enhance pilot training
157
Provide
Project
Promote
Produce
Convolution Neural Networks+ Transfer Learning
Pre-trained using 14-million image dataset
ResNet with > 8-million parameters
Input
images
Model training /
inference
OK
OK
以深度學習進行自動瑕疵檢測
台灣人工智慧學校首屆開學典禮
Especially important forequipment with high failure cost (such as
motors in machine tools)
Also important for expensive consumables (such as blades used in
precision cutting machines)
176
產業共通挑戰 #3-預測性維護





























































































































































































![[DL輪読会]Continuous Adaptation via Meta-Learning in Nonstationary and Competiti...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20171127shioya1-171127104425-thumbnail.jpg?width=640&height=640&fit=bounds)





![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)








![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)

![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)






![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)




![[台灣人工智慧學校] 台北總校第三期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/opening1-180929011045-thumbnail.jpg?width=640&height=640&fit=bounds)




![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)

![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] Practical experience in mining and evaluating information...](https://cdn.slidesharecdn.com/ss_thumbnails/1615-1655chenaia-info-sys-exp-181130083557-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] AI 及數據驅動的金融新應用 / 楊立偉](https://cdn.slidesharecdn.com/ss_thumbnails/1450-1530yang-181130083530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] Textual Data Analytics in Finance / 王釧茹](https://cdn.slidesharecdn.com/ss_thumbnails/1530-1610wangtextualdataanalyticsinfinance-181130083529-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 人工智慧與醫療應用 / 王淳恆](https://cdn.slidesharecdn.com/ss_thumbnails/1150-1230wangartificialintelligenceinmedicine-181130083431-thumbnail.jpg?width=640&height=640&fit=bounds)