Downloaded 12 times






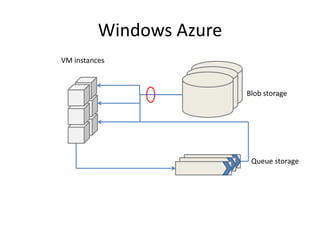

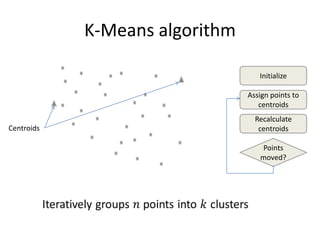
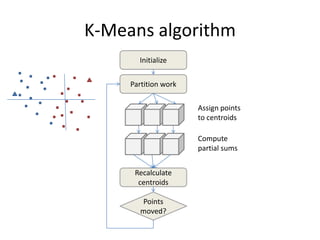

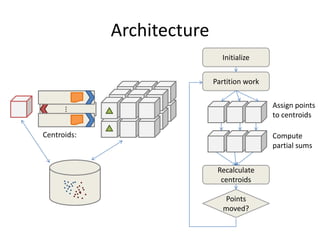

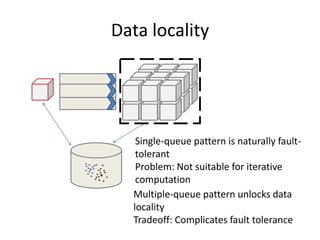

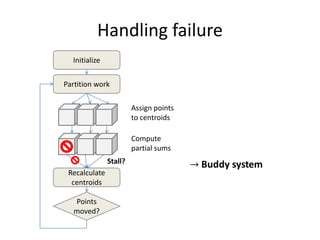
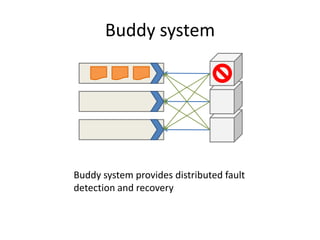
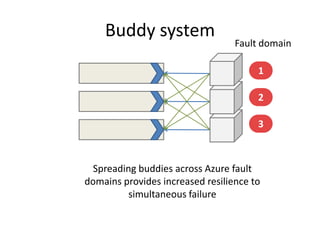
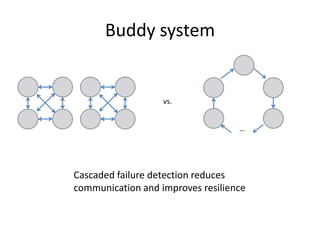

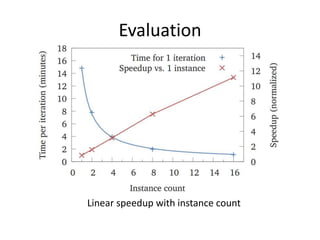
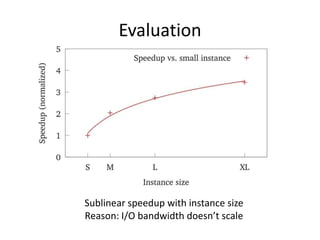




This document proposes CloudClustering, an iterative data processing pattern for the cloud. It uses K-means clustering as an example application. CloudClustering is designed to be efficient, fault tolerant, and leverage native cloud services. It uses multiple queues to improve data locality during iterative computation. A buddy system provides distributed fault detection and recovery to handle failures in a fault-tolerant manner. Evaluation shows linear speedup with increasing instances and sublinear speedup with increasing instance size due to I/O bandwidth constraints.















































