Cloud Plan 2014
•
1 like•251 views

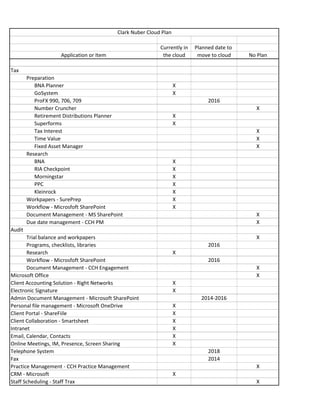
This document provides an overview of Clark Nuber's cloud plan, indicating which applications and items are currently in the cloud, planned to move to the cloud, or have no plan to move. It shows that many productivity, collaboration, research, and administrative applications and systems like Office 365, SharePoint, and CRM tools have already moved or will move to the cloud by 2016. Servers supporting functions like file storage, email, and databases are also scheduled to transition by 2016. The telephone system is planned for a 2018 cloud move, while core accounting and practice management systems currently have no cloud plans.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Cloud Plan 2014
Similar to Cloud Plan 2014 (20)
More from Peter Henley
More from Peter Henley (20)
Recently uploaded
Recently uploaded (20)
Cloud Plan 2014
- 1. Currently in Planned date to Application or Item the cloud move to cloud No Plan Tax Preparation BNA Planner X GoSystem X ProFX 990, 706, 709 2016 Number Cruncher X Retirement Distributions Planner X Superforms X Tax Interest X Time Value X Fixed Asset Manager X Research BNA X RIA Checkpoint X Morningstar X PPC X Kleinrock X Workpapers - SurePrep X Workflow - Microsfoft CRM X Document Management - MS SharePoint ? Due date management - CCH PM X Audit Trial balance and workpapers - CCH Engagement ? Programs, checklists, libraries 2016 Research X Workflow - Microsfoft SharePoint 2016 Microsoft Office X Client Accounting Solution - Right Networks X Electronic Signature X Admin Document Management - Microsoft SharePoint 2014-2016 Personal file management - Microsoft OneDrive X Client Portal - ShareFiile X Client Collaboration - Smartsheet X Intranet X Email, Calendar, Contacts X Online Meetings, IM, Presence, Screen Sharing X Telephone System 2018 Fax X Practice Management - CCH Practice Management X CRM - Microsoft X Staff Scheduling - Staff Trax X Human Resources - Microsoft SharePoint X General Ledger - Microsoft Greatplains Dynamics X Clark Nuber Cloud Plan
- 2. Currently in Planned date to Application or Item the cloud move to cloud No Plan Clark Nuber Cloud Plan Payroll - Ultipro X Learning Management - Checkpoint X Performance Evaluations - Halogen X Data Extraction and Analysis - CCH Active Data X Business Intelligence - Microsoft Power BI X Knowledge Management - None X Adobe Products - Acrobat, etc X Successor auditor access X Backup tools, Data X 2014-2016 X IT Management, updates, rollouts, antivirus X Servers X 2 domain controllers X ADFS 3.0 X SMTP relay for Office 365 and licensing (KMS) X Office 365 Directory Synchronization X VM Manager 2012 R2 X Varonis file access documentation X MIP Demo server X Amelio server X Engagement RAS X Test servers X W2 Mate X Speech X Commvault - replaced by Veeam 2016 ADFS 3.0 Server (Primary) 2018 Exchange 2010 for O365 Management 2016 2 Production Sarepoint Servers - replaced with Box X 2 Dev Sharepoint Servers 2016 SQL ? SQL Reporting Services ? File Server - administrative flat file data 2016 2 Domain Controllers X Shoretel X Fixed Asset Server 2016 KwikTag - accounts payable X Print Server 2016 Network Scanning/Misc 2016 Remote Desktop Gateway (published apps) X Library 7 (shared workstation) ?