Download to read offline





![2 days later…
1 libqt4_plugin.dll:0xxxxxxxxx mov ecx,[edx+0x30]
1 msvcrt.dll:0xxxxxxxxx rep stosd
1 ntdll.dll:0xxxxxxxxx mov ecx,[ecx+0x4]
2 libqt4_plugin.dll:0xxxxxxxxx arpl [ecx+0x63],sp
2 libqt4_plugin.dll:0xxxxxxxxx mov eax,[eax+0x18]
2 libqt4_plugin.dll:0xxxxxxxxx or byte [eax+0x10],0x1
3 libqt4_plugin.dll:0xxxxxxxxx mov [eax+0x8],ebx
4 libpacketizer_dirac_plugin.dll:0xxxxxxxxx mov dword [eax+0x20],0x0
4 libpacketizer_dirac_plugin.dll:0xxxxxxxxx mov eax,[edx+0x4]
5 libqt4_plugin.dll:0xxxxxxxxx mov dword [eax],0x1
10 libqt4_plugin.dll:0xxxxxxxxx mov [ebx+0x8],eax
13 libpacketizer_dirac_plugin.dll:0xxxxxxxxx mov edx,[eax+0x8]](https://image.slidesharecdn.com/fuzzingpart1-180820045647/85/Fuzzing-Part-1-6-320.jpg)
![2 days later… cont
1 [INVALID]:00000001
1 [INVALID]:00000040
1 [INVALID]:00350000
1 [INVALID]:0057001b
1 [INVALID]:008dac24
1 [INVALID]:0135f5d0
1 [INVALID]:0172d090
1 [INVALID]:01bffba8
1 [INVALID]:01c2fcc8
1 [INVALID]:01c9fc7c
1 [INVALID]:01cc5198
1 [INVALID]:0239f068
1 [INVALID]:0310d678
1 [INVALID]:06040002
1 [INVALID]:2f04002b
1 [INVALID]:338dac24
1 [INVALID]:7351eb81
1 [INVALID]:ff2677c4
2 [INVALID]:40000060
5 [INVALID]:76630000
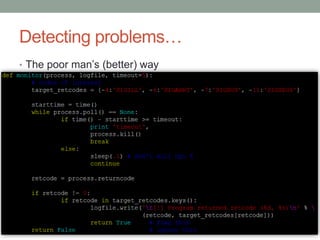
• 32 unique crashes ?
• The ones labeled INVALID, where EIP was
invalid look particularly interesting
• 0x00000001 and 0x00000040 especially ](https://image.slidesharecdn.com/fuzzingpart1-180820045647/85/Fuzzing-Part-1-7-320.jpg)









![Preloading…
• Creating a substitute for getenv
#define BUFFSIZE 20000
char *getenv(char *variable)
{
char buff[BUFFSIZE];
memset(buff,’A’,BUFFSIZE);
buff[BUFFSIZE-1] = 0x0;
return buff;
}
• Compiling and running
$ gcc -shared -fPIC -o my_getenv.so my_getenv.c
• Create the shared library, my_getenv.so
$ LD_PRELOAD=./my_getenv.so /usr/bin/target
• Set the LD_PRELOAD environment varaible and run the application](https://image.slidesharecdn.com/fuzzingpart1-180820045647/85/Fuzzing-Part-1-17-320.jpg)




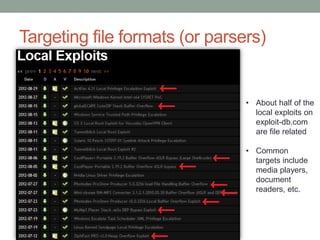
![Targeting file formats (or parsers)
• What exactly are we trying to exploit with file fuzzing?
• Format assumptions
• Length field ABC is supposed to be in the range 0-100, surely no one
would put 999999…
• Surely no one would put a negative value…
• etc.
• Signed bugs
• Length field XYZ is 4 bytes, and represents the length of the following
field
• ie : [….|4 byte size| data of 4 byte size|….]
int n = (int)read(…); // convert the next 4 bytes into an int
If( n > MAX_SIZE) // make sure the value is < MAX_SIZE
error() // error if it’s not
strncpy(dest, source, n) // we’re safe to copy](https://image.slidesharecdn.com/fuzzingpart1-180820045647/85/Fuzzing-Part-1-24-320.jpg)



The document discusses fuzzing, a software testing technique that involves inputting random or unexpected data into applications to identify vulnerabilities such as crashes and memory leaks. It covers types of fuzzing methods, data types to be used (including integers, strings, and delimiters), and approaches for targeting specific applications and file formats. Additionally, it provides insights on creating custom fuzzers and utilizing existing tools for effective fuzz testing.



















![Eloi Sanfelix - Hardware security: Side Channel Attacks [RootedCON 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/esanfelix-sidechannelattacks-110307125844-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Ruxcon 2011] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/ruxcon-111127233040-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Kiwicon 2011] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/kiwiconbrossard-111127232850-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[HITB Malaysia 2011] Exploit Automation](https://cdn.slidesharecdn.com/ss_thumbnails/brossardhitb2011-111127232630-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CCC-28c3] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/28c3-120107122834-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































