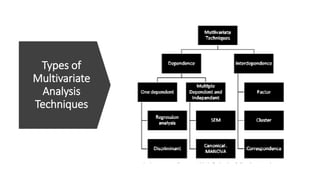
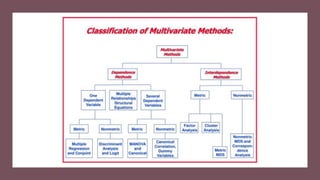
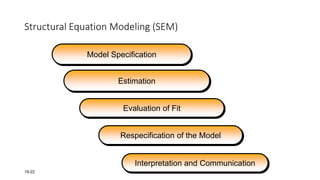
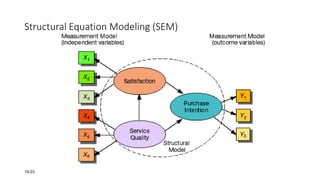
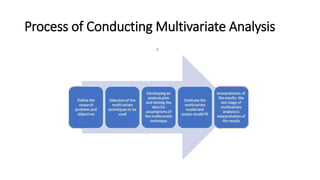
This document provides an overview of multivariate analysis techniques. It defines multivariate analysis as techniques that allow for the analysis of more than two variables at once. The document then classifies multivariate techniques into two categories: interdependence techniques, which analyze how variables influence each other; and dependence techniques, which analyze the relationship between independent and dependent variables. Several specific multivariate techniques are defined, including principal component analysis, multiple regression analysis, discriminant analysis, logistic regression, canonical correlation analysis, MANOVA, conjoint analysis, and cluster analysis. Real-world examples are provided to illustrate how and when researchers might apply certain multivariate techniques.