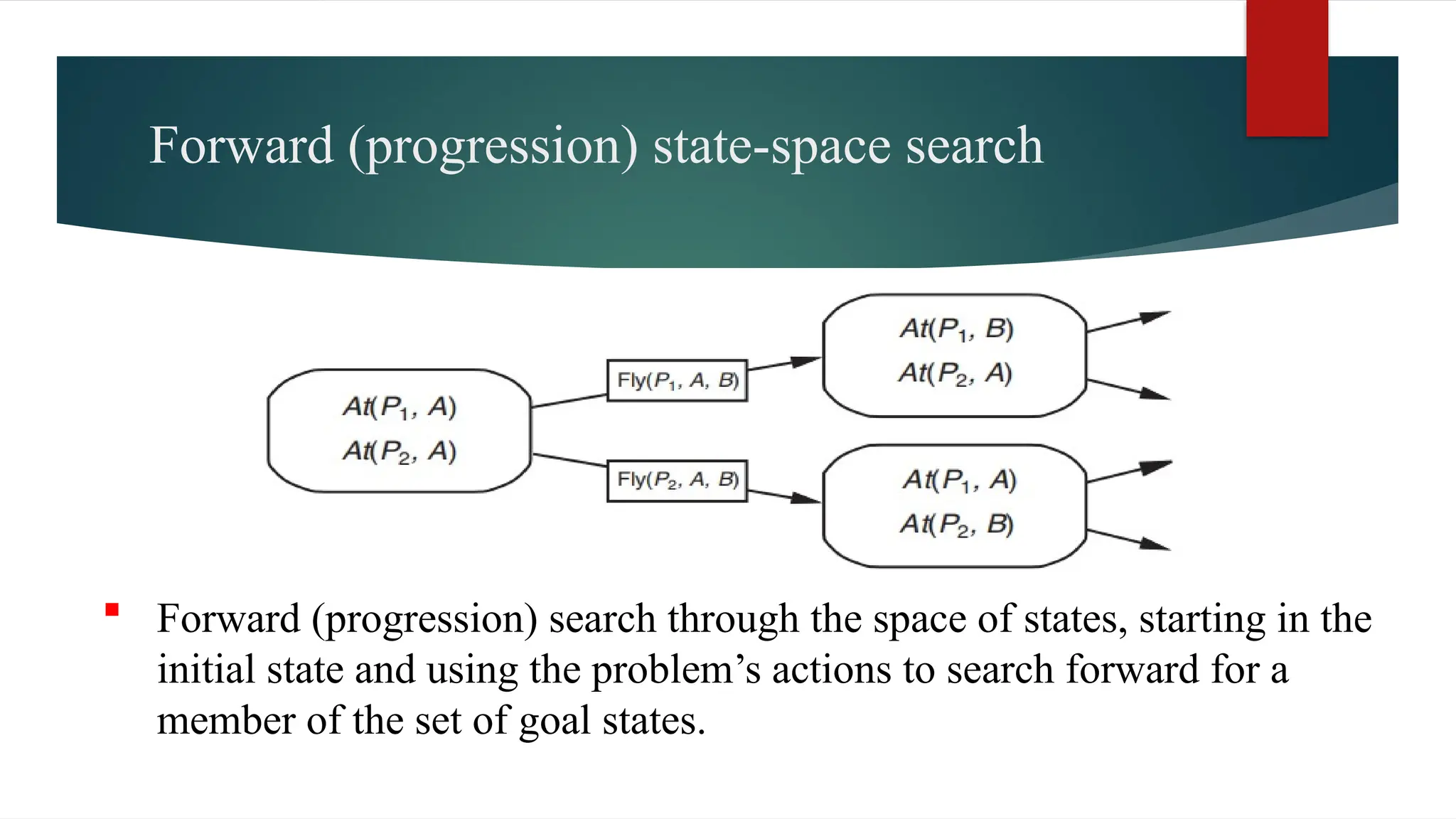
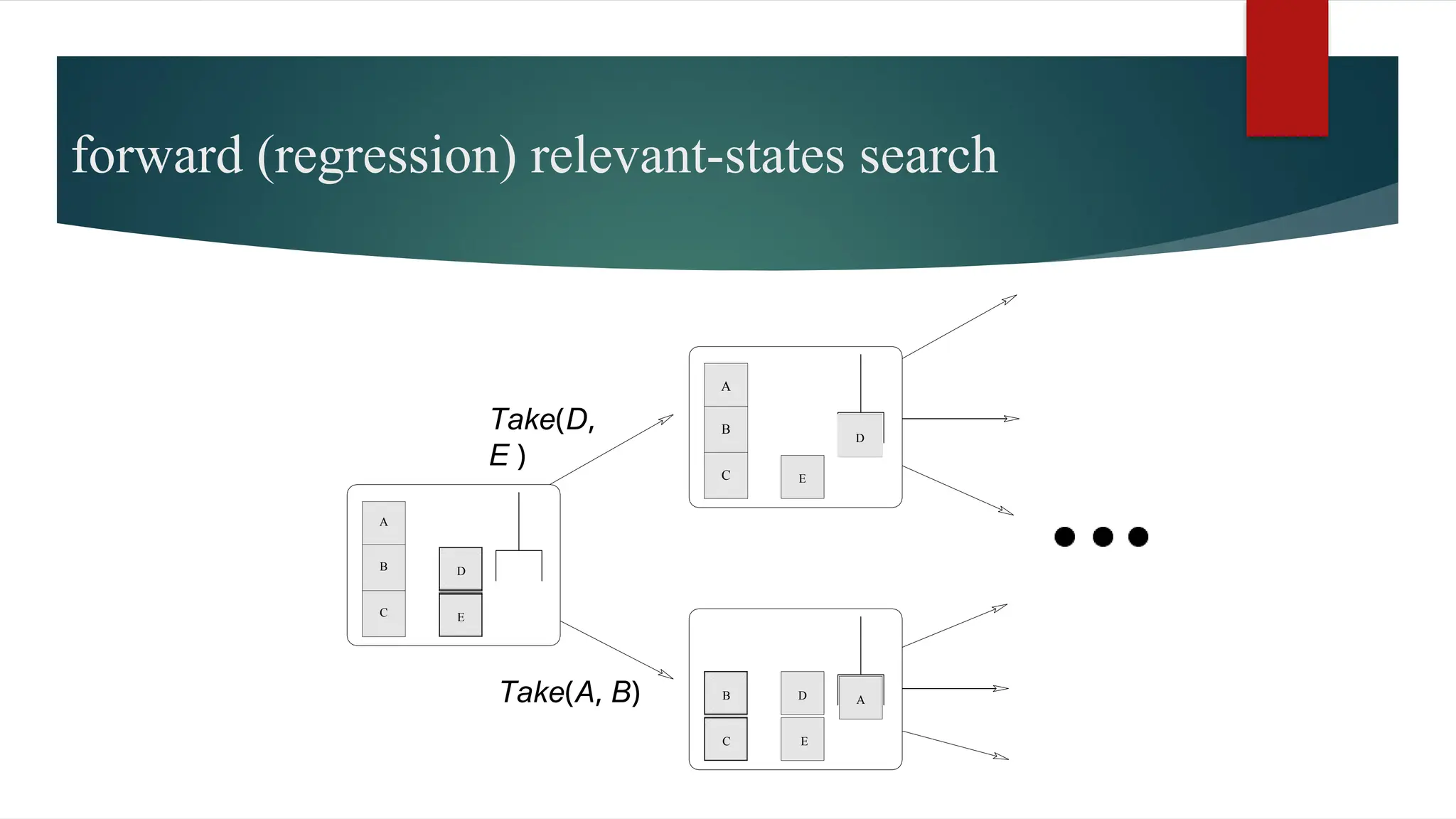
The document covers classical planning in artificial intelligence, emphasizing the importance of decision-making actions to achieve specific goals. It introduces various concepts, such as the blocks world problem and goal stack planning, as well as algorithms for planning that can be approached through state-space search methods. Additionally, it discusses heuristics for efficient planning, the use of planning graphs, and the Graphplan algorithm for determining goal reachability and mutual achievability.











































































![Depth first search [dfs]](https://cdn.slidesharecdn.com/ss_thumbnails/depthfirstsearchdfs-190926145304-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















