Contents
🠶 Automated Planning,Classical Planning
🠶 Algorithms for Classical Planning
🠶 Heuristics for Planning
🠶 Hierarchical Planning
🠶 Planning and Acting in Nondeterministic Domain
🠶 Time, Schedules, and Resources,
🠶 Analysis of Planning Approaches
🠶 Limits of AI, Ethics of AI, Future of AI, AI Components, AI
Architectures
3.
🠶 Planning inartificial intelligence is about decision-making actions
performed by robots or computer programs to achieve a specific goal.
🠶 Planning in AI is the process of coming up with a series of actions or
procedures to accomplish a particular task/goal.
🠶 This includes defining the scope and purpose of AI projects
🠶 choosing suitable algorithms, data sources,
🠶 Choosing suitable performance measures, developing and testing models,
and monitoring and adapting AI systems over time.
What is Planning
4.
Example:
🠶 In robotnavigation, a robot must plan its path from one location to
another while avoiding obstacles.
🠶 The plan would include the robot’s movement decisions, such as
turning left, moving forward, and stopping at certain points.
🠶 Similarly, in route optimization, AI systems create plans to minimize
travel time and cost while ensuring that all destinations are covered.
6.
Importance of Planning:
🠶Problem Solving:
AI systems rely on planning to break down complex
problems into manageable steps, allowing them to find
solutions that meet specified goals.
🠶 Decision Making:
Planning helps AI systems evaluate multiple potential
actions and select the best course based on predicted
outcomes.
🠶 Without planning, AI systems would struggle to operate autonomously
in real-world environments, where they must navigate uncertainty and
complexity.
7.
Key Components ofPlanning in AI:
🠶 Initial State
🠶 The starting point of the problem or environment.
🠶 Describes the conditions or configuration of the world before any actions are
taken.
🠶 Goal State
🠶 The desired outcome or condition that the system aims to achieve.
🠶 Planning is essentially about finding a path from the initial state to this goal.
🠶 Actions (Operators)
🠶 Possible operations the agent can perform.
🠶 Each action has:
🠶Preconditions: Conditions that must be true for the action to be executed.
🠶Effects: Changes that occur in the state after the action is executed.
8.
🠶 State Space
🠶The set of all possible states that can be reached by performing actions from
the initial state.
🠶 Can be represented as a graph where nodes are states and edges are actions.
🠶 Plan
🠶 A sequence of actions that transitions the system from the initial state to the
goal state.
🠶 May include conditional branches and loops in more complex planning
systems.
🠶 Planning Algorithm (Planner)
🠶 The method or strategy used to generate a plan.
🠶 Examples: Forward chaining, backward chaining, heuristic search, STRIPS,
GraphPlan, Partial Order Planning.
9.
🠶 Heuristics (optional)
🠶Domain-specific knowledge used to make the planning process more
efficient.
🠶 Helps in evaluating and selecting the most promising states or actions.
🠶 Constraints
🠶 Limitations or rules that must be respected while planning (e.g., time limits,
resource availability, safety conditions).
🠶 Execution Monitoring
🠶 Ensures that the plan is followed correctly.
🠶 May involve checking actual outcomes against expected results and re-
planning if needed.
10.
Example: A RobotDelivery in a Warehouse
🔸 Problem Statement
A robot in a warehouse needs to deliver a package from Location A (start point)
to Location D (goal), navigating through several intermediate points and avoiding
obstacles.
1. Initial State
Robot is at Location A
Package is on the robot
Map of the warehouse is known
2. Goal State
Robot is at Location D
Package is successfully delivered
11.
3. Actions (Operators)
•Move(North),Move(South), Move(East), Move(West)
•Precondition: No obstacle in the direction
•Effect: Robot changes position
•DropPackage()
•Precondition: At destination location (D)
•Effect: Package is delivered
4. State Space
All possible positions of the robot in the warehouse (A, B, C, D, etc.)
States also include whether the robot has the package or not
5. Plan
Example sequence: Move(East) → Move(South) → Move(East) → DropPackage()
12.
6. Planning Algorithm
Coulduse a graph search algorithm like A* or Dijkstra's algorithm to
find the shortest or safest path from A to D.
7. Heuristics
In A* search, a heuristic like Manhattan Distance can estimate the
distance from the current position to the goal
8. Constraints
Obstacles must be avoided
Battery life (if limited) may be another constraint
9. Execution Monitoring
Robot uses sensors to detect if an obstacle has appeared unexpectedly
If blocked, it re-plans a new route using updated state info
13.
Planning Agent, State,Goal, and Action Representation
🠶 A planning agent is an intelligent system capable of generating a
sequence of actions to achieve a specific goal from a given initial state.
🠶 It perceives the environment, formulates plans based on available
knowledge, and executes them effectively.
🠶 Unlike reactive agents, planning agents reason about the future,
consider consequences of actions, and often re-plan if the
environment changes.
14.
🠶 A staterepresents a snapshot of the world at a given time.
🠶 It includes all the relevant information about the environment,
such as the position of objects, conditions, and the agent's location.
🠶 In AI planning, states are typically represented using predicates,
logic-based formulas, or feature vectors
🠶 At(Robot, Room1), Holding(Box)
15.
🠶 Goal Representation
🠶A goal defines the desired outcome or condition that the planning
agent wants to achieve.
🠶 Like states, goals are also represented using logical statements or
sets of desired conditions.
🠶 A goal may be simple or complex depending on the task.
🠶 At(Robot, Room3) Delivered(Box)
∧
16.
🠶 Action Representation
🠶Actions (also called operators) describe the possible transitions
between states. Each action consists of:
🠶 Preconditions: Conditions that must be true to perform the action
🠶 Effects: The result or change in the state after the action
🠶 Action: Move(Room1, Room2)
🠶 Preconditions: At(Robot, Room1)
🠶 Effects: ¬At(Robot, Room1), At(Robot, Room2)
Write a short note on planning agent, state goal and action representation [6]
Explain different components of planning system [6]
Types of Planning
1.Classical Planning:
🠶 Classical Planning is a foundational approach in AI where the
environment is:
🠶 Fully observable (the agent has complete knowledge of the world)
🠶 Deterministic (actions always lead to predictable outcomes)
🠶 Static (the world doesn't change while planning is happening)
🠶 Sequential (actions happen one after another in a defined order)
🠶 It involves finding a sequence of actions that transforms an initial
state into a goal state using predefined operators (actions).
19.
How It Works:
🠶Initial State: Where the agent starts
🠶 Goal State: What the agent wants to achieve
🠶 Actions: Defined by Preconditions and Effects
🠶 Planner: Finds the best sequence of actions (the plan)
20.
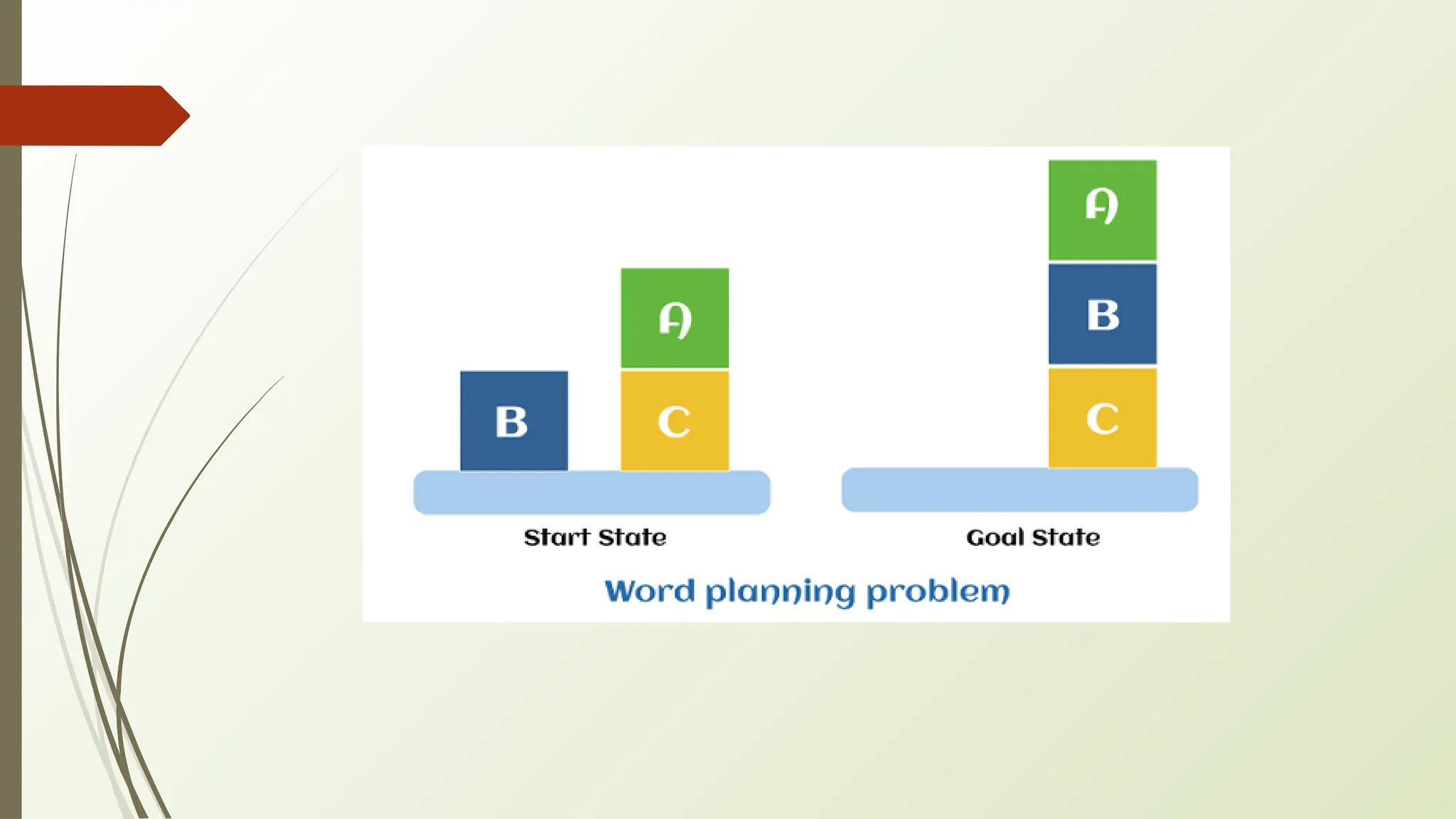
Example: Blocks World
Youhave 3 blocks: A, B, and C on a table. You want to stack them such that:
Goal: A on B, B on C
🠶 Initial State:
🠶 All blocks are on the table
🠶 Robot arm is free
🠶 Actions:
🠶 PickUp(X) – Preconditions: X is clear and on the table
🠶 PutOn(X, Y) – Preconditions: Robot is holding X and Y is clear
🠶 Plan:
🠶 PickUp(A)
🠶 PickUp(B), PutOn(A, B)
🠶 PickUp(C), PutOn(B, C)
🠶 The result is a stack: A on B on C.
21.
Advantages of ClassicalPlanning:
🠶 Simplicity
🠶 Clear assumptions make it easier to model and solve problems.
🠶 Efficiency in Structured Environments
🠶 Works well in environments with well-defined rules (e.g., games, puzzles).
🠶 Deterministic Outcomes
🠶 Predictable action results make plan verification straightforward.
🠶 Foundation for Advanced Techniques
🠶 Serves as a base for learning more complex planning approaches.
🠶 Reusability
🠶 Once created, the plan can often be reused in similar situations
22.
2. Probabilistic Planning
🠶Probabilistic Planning is a type of AI planning used in environments
where:
🠶 Outcomes of actions are uncertain or stochastic
🠶 The agent may not have complete control or full knowledge of the
environment
🠶 Planning must include risk management and decision-making
under uncertainty
🠶 It generates plans or policies that consider the likelihood of various
outcomes to maximize the expected success.
23.
1. States (S)
Allthe possible situations the agent can be in.
2. Actions (A)
Available choices the agent can make. Each action may lead to multiple
outcomes.
3. Transition Model (T)
Specifies the probability of reaching a new state s' when taking action a in
state s.
Formally: T(s, a, s') = P(s' | s, a)
4. Reward Function (R) (optional)
Specifies the reward the agent receives for being in a state or taking an
action — used in decision-theoretic planning.
5. Policy ( )
π
A mapping from states to actions that tells the agent what to do in each
situation to maximize success or reward.
24.
Example: Robot onSlippery Floor
Problem:
A robot needs to move from Room A to Room B. But the floor is slippery, and every
move has an 80% chance of success and 20% chance of failure (slipping and staying
in the same place).
Actions:
MoveForward()
Success (80%): Robot moves to next position
Fail (20%): Robot slips and stays in place
Planning Approach:
The planner considers the probabilities and may choose:
To attempt the move multiple times
To take a longer but safer route if available
Result:
The robot’s policy might say:
“If failed once, try again up to 3 times before choosing an alternate path.”
25.
Advantages of ProbabilisticPlanning:
🠶 Handles Uncertainty
🠶 Plans can tolerate unpredictable results or noisy environments.
🠶 Realistic Modeling
🠶 Matches how real-world systems (like robots or self-driving cars) actually operate.
🠶 Robust Decision-Making
🠶 Produces plans that are better prepared for failure or unexpected events.
🠶 Optimized for Expected Outcome
🠶 Chooses actions that maximize success over time, even if short-term steps may fail.
🠶 Suitable for Complex Domains
🠶 Useful in medical diagnosis, finance, robotics, and autonomous navigation.
26.
🠶 Real-World Applications:
Robotics– Navigating uncertain terrains
Autonomous Vehicles – Driving under uncertain road conditions
Healthcare – Planning treatments with uncertain outcomes
Finance – Decision making under market uncertainty
Game AI – Planning in dynamic game environments
27.
3. Hierarchical Planning
🠶Hierarchical Planning, also called HTN (Hierarchical Task
Network) Planning, is a method where complex tasks are broken
down into smaller, more manageable subtasks in a top-down fashion.
🠶 Instead of planning actions directly from the start to goal, the planner
decomposes a high-level goal into a hierarchy of smaller tasks,
until reaching basic, executable actions.
28.
Key Concepts:
Task
A goalor activity to be achieved (can be high-level or primitive)
Primitive Task
A basic action that can be directly executed (like Move, Pick, Place)
Compound Task
A high-level task that must be decomposed into smaller tasks
Method
A rule for how to break down a compound task into subtasks
29.
Advantages of HierarchicalPlanning:
More Human-Like
Mimics how humans plan — from general goals to detailed steps.
Scalable
Handles large and complex problems by breaking them down.
Reusable Methods
Methods for task decomposition can be reused in different scenarios.
Efficient Planning
Narrows down the search space by focusing only on relevant subtasks.
Flexible
Easy to modify a part of the plan without changing the whole.
30.
Example: Making Tea
🠶Decomposition (Compound Tasks):
🠶 Method for MakeTea():
BoilWater()
AddTeaBagToCup()
PourHotWater()
Serve()
Algorithms Used ForClassical Planning
🠶 Classical planning assumes a deterministic, fully observable, static
environment — and uses search-based algorithms to find a sequence
of actions from an initial state to a goal state.
1. Forward State-Space Search (Progression Planning)
2. Backward State-Space Search (Regression Planning)
3. Plan-Space Planning (Partial-Order Planning)
4. GraphPlan Algorithm
5. Heuristic Search Algorithms
6. SAT-based Planning
7. STRIPS Algorithm
33.
Applications of AIPlanning
🠶 Robotics: To enable autonomous robots to properly navigate their
surroundings, carry out activities, and achieve goals, planning is crucial.
🠶 Gaming: AI planning is essential to the gaming industry because it
enables game characters to make thoughtful choices and design difficult
and interesting gameplay scenarios.
🠶 Logistics: To optimize routes, timetables, and resource allocation and
achieve effective supply chain management, AI planning is widely utilized
in logistics.
🠶 Healthcare: AI planning is used in the industry to better the quality and
effectiveness of healthcare services by scheduling patients, allocating
resources, and planning treatments.
34.
Challenges in AIPlanning
🠶 Complexity: Due to the wide state space, multiple possible actions, and
interdependencies between them, planning in complicated domains can be
difficult.
🠶 Uncertainty: One of the biggest challenges in AI planning is overcoming
uncertainty. Actions' results might not always be anticipated, thus the
planning system needs to be able to deal with such ambiguous situations.
🠶 Scalability: Scalability becomes a significant barrier as the complexity and
scale of planning problems rise. Large-scale issues must be effectively
handled via planning systems.
35.
🠶 Explain. i)Algorithm for classical planning [8] May 2023
ii) Importance of planning
🠶 Explain Planning in non deterministic domain. [5]
🠶 Explain with example, how planning is different from problem solving
[5] MAY 2023, Nov 2023
🠶 Explain different components of planning system [6] Nov 2022
🠶 What are the types of planning? Explain in detail. [6] Nov 2022
🠶 Explain Classical Planning and its advantages with example. [6] Nov 2022
🠶 Analyze various planning approaches in detail [9] May 2022
36.
Explain Planning innon deterministic domain.
🠶 In Artificial Intelligence (AI), planning in a non-deterministic domain refers to the
process of creating a sequence of actions to achieve a goal when the outcomes of
actions are not guaranteed — i.e., the same action can lead to different results
depending on the situation or randomness in the environment.
🠶 What is a Non-Deterministic Domain?
🠶 A non-deterministic domain is an environment where:
🠶 Actions may have multiple possible outcomes.
🠶 The agent cannot predict with certainty what the result of an action will be.
🠶 There may be external factors or unknown variables affecting the outcome.
🠶 Example:
🠶 A robot moves forward in a slippery area. Sometimes it moves correctly, sometimes it slips
and ends up in a different location.
So, the action "move forward" doesn't always lead to the same result.
37.
🠶 Why isPlanning Challenging Here?
🠶 In deterministic domains, planning is relatively straightforward:
If the agent knows the state and action, the result is predictable.
🠶 But in non-deterministic planning:
🠶 The agent must consider all possible outcomes of actions.
🠶 The plan must handle uncertainties, possibly by creating contingent plans (if-then
plans).
🠶 The goal is not just finding a fixed sequence of actions, but a policy or strategy that can
adapt to different situations.
🠶 Types of Plans in Non-Deterministic Domains
🠶 Contingent Plans:
Include conditional branches, e.g.,
“If the door opens, go inside; if not, try the window.”
🠶 Probabilistic Plans:
Take into account the probability of outcomes, trying to maximize the expected success.
🠶 Replanning or Reactive Plans:
The agent re-evaluates and adjusts the plan dynamically as new information is available.
38.
🠶 Applications
🠶 Robotics(unpredictable terrain or sensor noise)
🠶 Autonomous vehicles (dynamic road conditions)
🠶 Game AI (opponent strategies vary)
🠶 Medical diagnosis systems (uncertain patient symptoms or reactions)
39.
Explain with example,how planning is different from
problem solving
🠶 Problem solving involves:
🠶 Finding a sequence of actions (a solution) to move from the initial state to the goal state.
🠶 Usually assumes a simple, deterministic environment.
🠶 Focuses on searching through a state space.
🠶 It answers “What steps do I need to take to reach the goal from the current situation?”
🠶 Planning is more structured and powerful. It:
🠶 Considers a set of actions with preconditions and effects.
🠶 Handles complex, dynamic, and sometimes non-deterministic environments.
🠶 Often works with partial information and builds a plan (or policy) to handle different
situations.
🠶 It answers “What should I do at each step, considering possible future events and goals?”
40.
🠶 Example: RobotDelivery Task
🠶 A robot must deliver a package from Room A to Room C, passing through Room
B.
🠶 Problem Solving Approach:
🠶 Assumes the map is fixed and doors are always open.
🠶 Uses a search algorithm like A* or BFS.
1. Move from Room A to Room B
2. Move from Room B to Room C
🠶 Simple and straightforward.
41.
🠶 Planning Approach:
🠶Now assume:
🠶 The door between Room A and Room B might be locked.
🠶 The robot has an action "Check Door" and "Unlock Door".
🠶 There may be battery constraints, or multiple packages to deliver.
1. Check if Door AB is open
- If yes → Move to Room B
- If no → Unlock Door, then Move to Room B
2. Move to Room C
3. Recharge battery if low before next delivery
🠶 This plan:
🠶 Is condition-based (handles uncertainty)
🠶 Uses preconditions and effects
🠶 Is more like a strategy than just a path
42.
Planning as StateSpace Search
🠶 State space search is a problem-solving technique used in Artificial
Intelligence (AI) to find the solution path from the initial state to the goal state
by exploring the various states.
🠶 The state space search approach searches through all possible states of a
problem to find a solution.
🠶 It is an essential part of Artificial Intelligence and is used in various
applications, from game-playing algorithms to natural language processing.
🠶 A state space is a way to mathematically represent a problem by defining all
the possible states in which the problem can be.
🠶 This is used in search algorithms to represent the initial state, goal state, and
current state of the problem.
43.
Planning as StateSpace Search
🠶 Each state in the state space is represented using a set of variables.
🠶 The efficiency of the search algorithm greatly depends on the size of the state
space, and it is important to choose an appropriate representation and search
strategy to search the state space efficiently.
🠶 One of the most well-known state space search algorithms is
the A algorithm.
🠶 Other commonly used state space search algorithms include breadth-first
search (BFS), depth-first search (DFS), hill climbing, simulated
annealing, and genetic algorithms.
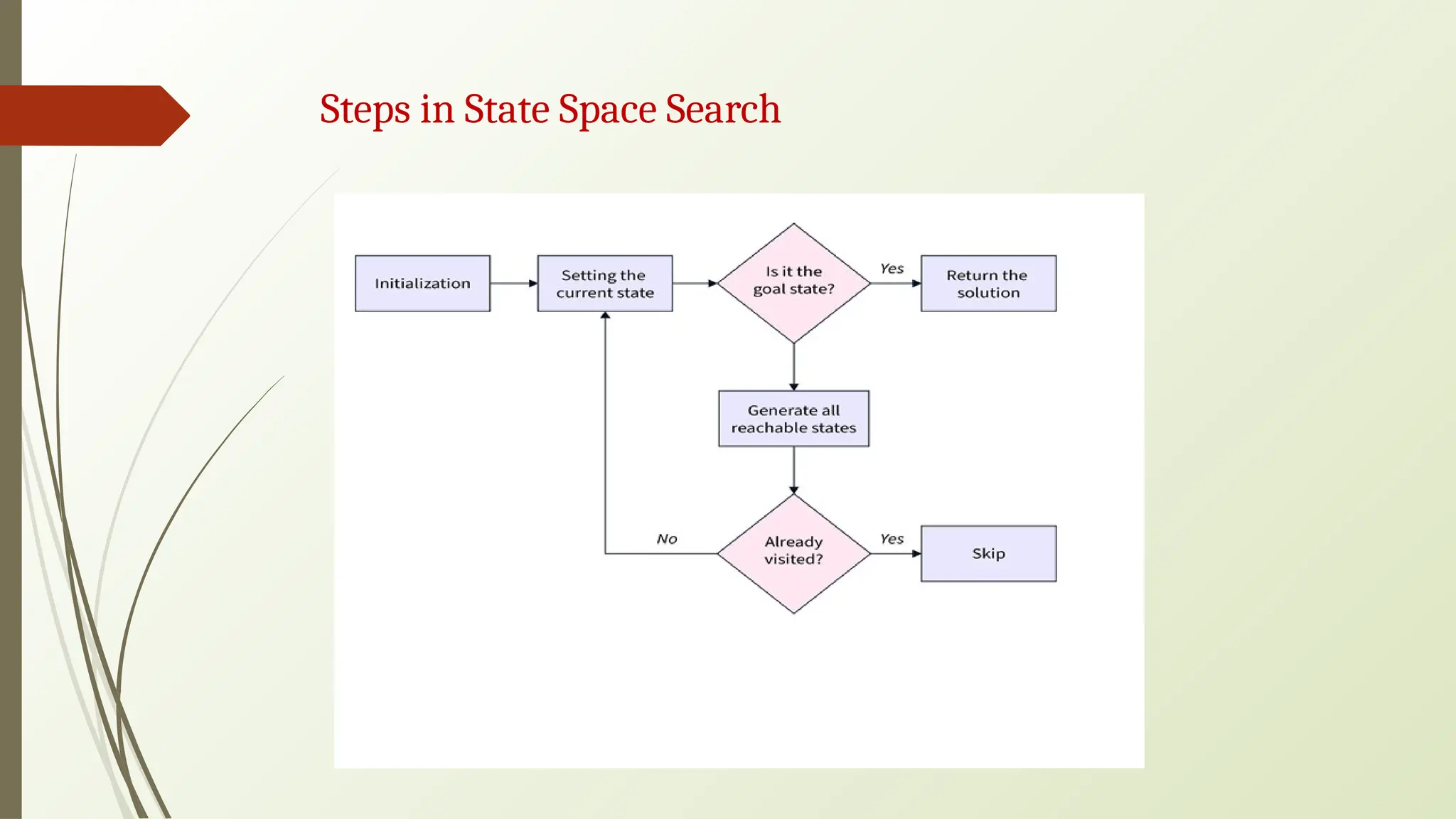
🠶 To beginthe search process, we set the current state to the initial state.
🠶 We then check if the current state is the goal state. If it is, we terminate the
algorithm and return the result.
🠶 If the current state is not the goal state, we generate the set of possible successor
states that can be reached from the current state.
🠶 For each successor state, we check if it has already been visited. If it has, we skip it,
else we add it to the queue of states to be visited.
🠶 Next, we set the next state in the queue as the current state and check if it's the
goal state. If it is, we return the result. If not, we repeat the previous step until we
find the goal state or explore all the states.
🠶 If all possible states have been explored and the goal state still needs to be found,
we return with no solution.
46.
Example of StateSpace Search
🠶 The 8-puzzle problem is a commonly used example of a state space
search.
🠶 It is a sliding puzzle game consisting of 8 numbered tiles arranged in
a 3x3 grid and one blank space.
🠶 The game aims to rearrange the tiles from their initial state to a final
goal state by sliding them into the blank space.
🠶 The initial state of the puzzle represents the starting configuration of
the tiles, while the goal state represents the desired configuration.
🠶 Search algorithms utilize the state space to find a sequence of moves
that will transform the initial state into the goal state.
48.
Advantages of StateSpace Search in AI
🠶 Problem Representation: It allows for the representation of complex problems in a structured
manner, with states representing configurations and transitions depicting possible actions or
moves.
🠶 Versatility: State space search can be applied to a wide range of problems across different domains,
from robotics and game-playing to natural language processing and scheduling.
🠶 Adaptability: It can adapt to various problem types, including deterministic, stochastic, and
adversarial scenarios, making it applicable to a diverse set of challenges.
🠶 Informed Decision-Making: Through the use of heuristic functions, state space search can
incorporate domain-specific knowledge, guiding the search process towards more efficient and
effective solutions.
🠶 Optimality and Completeness: Depending on the algorithm employed, state space search can
guarantee either optimal solutions (finding the best possible outcome) or completeness (ensuring
a solution will be found if it exists).
🠶 Memory Efficiency: Many state space search algorithms are designed to be memory-efficient,
allowing them to handle large state spaces without overwhelming computational resources.
49.
Disadvantages of StateSpace Search in AI
🠶 Memory Intensive: Storing and managing a large state space can require significant
memory resources, which can be a limitation for systems with limited memory.
🠶 Time-Consuming: In complex problems, the search process can be time-consuming,
especially if the state space is large or if the algorithm does not employ efficient
heuristics.
🠶 Limited to Deterministic Environments: State space search assumes deterministic
environments where the outcome of an action is always predictable. In stochastic or
partially observable environments, it may not perform optimally.
🠶 Difficulty with Large Branching Factors: Problems with a large number of possible
actions from each state can lead to a high branching factor, making the search process
more challenging.
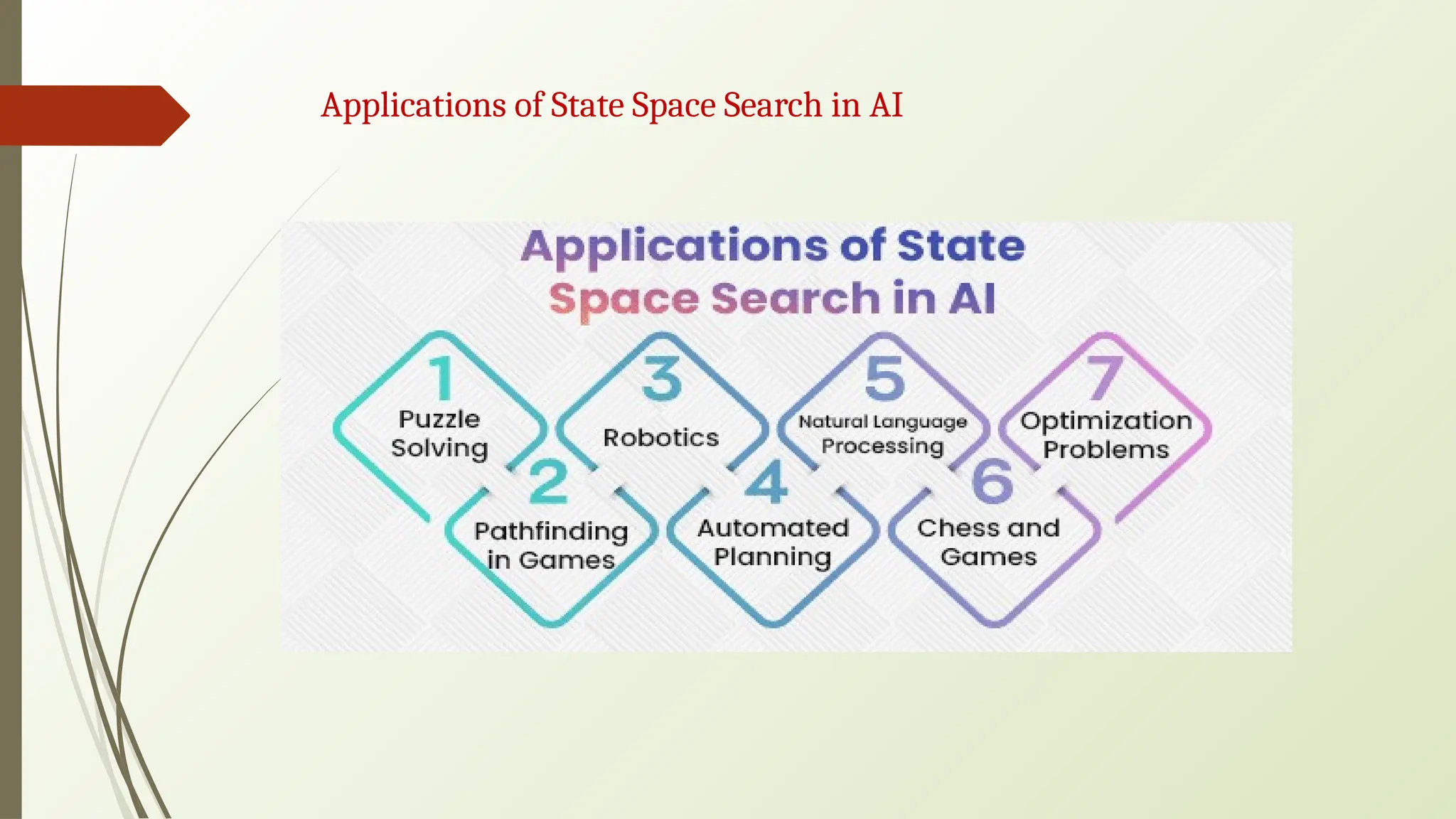
🠶 Puzzle Solving:Solving puzzles like the 8-puzzle, Rubik’s Cube, and Sudoku using
state space search algorithms
🠶 Pathfinding in Games: Finding the shortest path for characters or agents in video
games is a common use case for algorithms like A*
🠶 Robotics: Planning the movement of robots in a physical environment to perform
tasks or reach specific locations
🠶 Automated Planning: In areas like logistics, transportation, and manufacturing, state
space search helps in planning and scheduling tasks
🠶 Natural Language Processing: In tasks like machine translation, state space search
can be used to generate optimal translations
🠶 Chess and Games: Determining optimal moves in games with well-defined rules and
states, like chess, checkers, and Go
🠶 Optimization Problems: Solving optimization problems in areas like resource
allocation, scheduling, and financial modeling
52.
What Is theWater Jug Problem in Artificial Intelligence?
🠶 The Classic Setup:
🠶 You have two jugs: One can hold x liters, and the other can
hold y liters.
🠶 Your task is to measure exactly z liters of water using the two
jugs.
🠶 Allowed Operations:
🠶 Fill one jug completely.
🠶 Empty a jug entirely.
🠶 Pour water from one jug into the other until one jug is full or the
other is empty.
53.
State Space Search:How It Helps Solve the Water Jug Problem
🠶 State space search refers to exploring all possible states of a system (in this case, the water
levels in the two jugs) to find the best solution.
🠶 To solve the Water Jug Problem, AI systems explore all possible ways the water in the jugs can
be manipulated to achieve the target amount of water.
🠶 Here’s a breakdown of how it works:
🠶 Initial State: Both jugs are empty (0 liters in each).
🠶 Actions: You can fill a jug, empty a jug, or pour water from one jug into the other.
🠶 State Transitions: Each action results in a new state (a different combination of water
amounts in the jugs).
🠶 Goal State: The goal is to reach a state where one of the jugs contains exactly z liters.
54.
How to Solvethe Water Jug Problem with Search Algorithms
🠶 Breadth-First Search (BFS)
🠶 BFS is ideal for finding the shortest path or the minimum number of steps needed to reach the goal.
It explores all possible moves from the current state before moving on to the next level. BFS ensures
that the first solution found is the shortest path to the goal.
🠶 Here’s a brief example of how BFS would work with a 3-liter jug and a 5-liter jug to measure 4 liters:
🠶 Start: Both jugs are empty: (0, 0)
🠶 Action 1: Fill the 3-liter jug: (3, 0)
🠶 Action 2: Pour the 3 liters from the 3-liter jug into the 5-liter jug: (0, 3)
🠶 Action 3: Fill the 3-liter jug again: (3, 3)
🠶 Action 4: Pour the 3 liters from the 3-liter jug into the 5-liter jug until the 5-liter jug is full: (1, 5)
🠶 Action 5: Empty the 5-liter jug: (1, 0)
🠶 Action 6: Pour the remaining water from the 3-liter jug into the 5-liter jug: (0, 1)
🠶 Action 7: Fill the 3-liter jug again: (3, 1)
🠶 Action 8: Pour from the 3-liter jug into the 5-liter jug until it’s full: (0, 4)
🠶 The BFS algorithm ensures that you’ve found the solution using the fewest steps possible.
55.
🠶 Depth-First Search(DFS)
🠶 DFS explores one branch of the state space as deeply as possible before
backtracking to explore other branches.
🠶 It’s a simpler approach compared to BFS but might not always guarantee the
shortest solution.
🠶 How it works: Start from the initial state, and keep exploring one possible
path until you reach a dead end.
🠶 If you encounter a dead end, backtrack and explore another path.
🠶 While DFS is often used for its simplicity, it may take longer to reach the
optimal solution, especially in larger search spaces.
56.
Defining the StateSpace
We represent each state as a pair (x, y) where:
x is the amount of water in the 3-liter jug.
y is the amount of water in the 5-liter jug.
The initial state is (0, 0) because both jugs start empty, and the goal is to reach any state where
either jug contains exactly 4 liters of water.
Operations in State Space
The following operations define the possible transitions from one state to another:
1.Fill the 3-liter jug: Move to (3, y).
2.Fill the 5-liter jug: Move to (x, 5).
3.Empty the 3-liter jug: Move to (0, y).
4.Empty the 5-liter jug: Move to (x, 0).
5.Pour water from the 3-liter jug into the 5-liter jug: Move to (max(0, x - (5 - y)), min(5, x + y)).
6.Pour water from the 5-liter jug into the 3-liter jug: Move to (min(3, x + y), max(0, y - (3 - x))).
57.
🠶 Explain withan example State Space Planning
[5] May 2023, Nov 2022
🠶 Explain with an example Goal Stack Planning (STRIPS algorithm).
[5] May 2024, May 2023
58.
🠶 Explain AIcomponents and AI architecture [8]
🠶 What is AI explain scope of AI in all walks of Life also explain future opportunities with AI. [8]
🠶 Explain Limits of AI and Future opportunities with AI [5]
🠶 What is AI Explain. Scope of AI in all walks of Life also explain Future opportunities with AI [5]
🠶 Discuss AI and its ethical concerns. Explain limitations of AI [8]
🠶 Write a detailed note on AI Architecture. [5]
59.
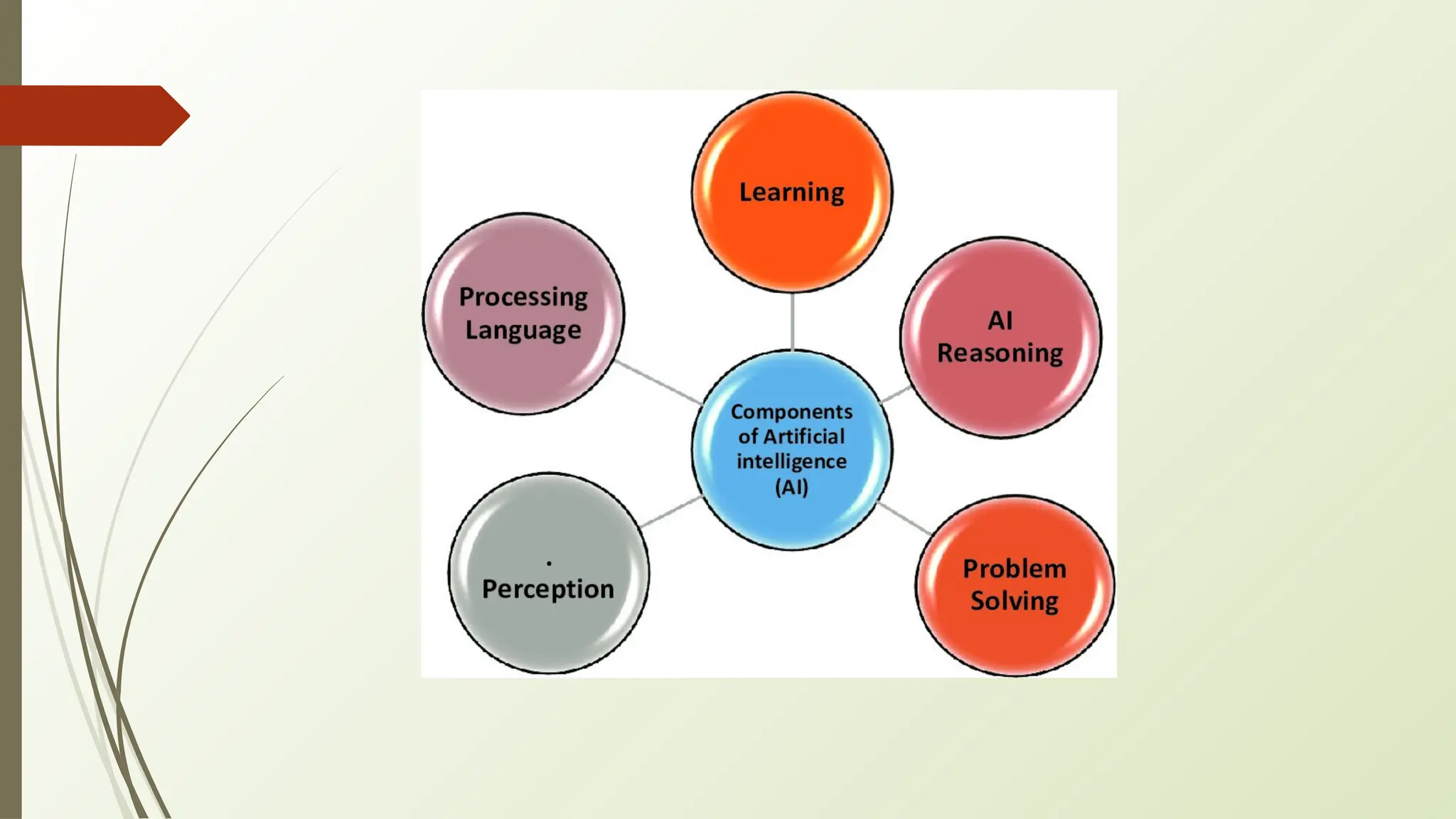
AI components andAI architecture
These are the functional building blocks of any AI system:
1. Perception
🠶 Purpose: To sense and interpret input from the environment.
🠶 Input: Images, audio, sensor data, etc.
🠶 Techniques Used: Computer Vision, Speech Recognition, Sensor Fusion.
🠶 Example: A robot uses a camera to detect obstacles.
🠶 2. Knowledge Representation
🠶 Purpose: To store facts and relationships about the world.
🠶 Types:
🠶 Semantic networks,
🠶 Frames,
🠶 Ontologies,
🠶 Logic rules.
🠶 Example: Storing "Birds can fly" and "Penguins are birds but cannot fly".
60.
3. Reasoning andInference
🠶 Purpose: To derive new information or make decisions using known facts.
🠶 Types:
🠶 Deductive reasoning,
🠶 Inductive reasoning,
🠶 Rule-based inference.
🠶 Example: If "It is raining" and "If it rains, carry an umbrella", then infer "Carry an
umbrella".
4. Learning
🠶 Purpose: To improve performance or knowledge from experience.
🠶 Types:
🠶 Supervised Learning,
🠶 Unsupervised Learning,
🠶 Reinforcement Learning.
🠶 Example: A spam filter that learns to identify spam from email examples.
61.
5. Planning
🠶 Purpose:To determine a sequence of actions to reach a goal.
🠶 Involves: Goal setting, decision making, and optimization.
🠶 Example: A delivery drone plans a path to drop a package.
6. Natural Language Processing (NLP)
🠶 Purpose: To interact with humans using language.
🠶 Tasks:
🠶 Language understanding,
🠶 Language generation,
🠶 Translation.
🠶 Example: Voice assistants like Alexa or Siri.
7. Actuation (Action Execution)
🠶 Purpose: To perform physical or system-level actions based on decisions.
🠶 Example: A robotic arm moves to pick up an object.
62.
AI Architecture
1. SimpleLayered Architecture
Human Interface Layer ← Input/Output via text, speech, GUI
Perception Layer ← Sensors, vision, speech input
Cognitive Layer ← Reasoning, Planning, Learning
Knowledge Layer ← Ontologies, Rules, Facts
Actuation Layer ← Motor actions, system outputs
63.
2. Types ofAI Architectures
Architecture Type Description
Reactive Architecture
No memory; acts only on current input
(fast but limited).
Deliberative Architecture
Uses a world model; plans actions ahead
of time.
Hybrid Architecture
Combines reactive and deliberative;
common in robots.
Cognitive Architecture
Models human-like thinking (e.g., SOAR,
ACT-R).
64.
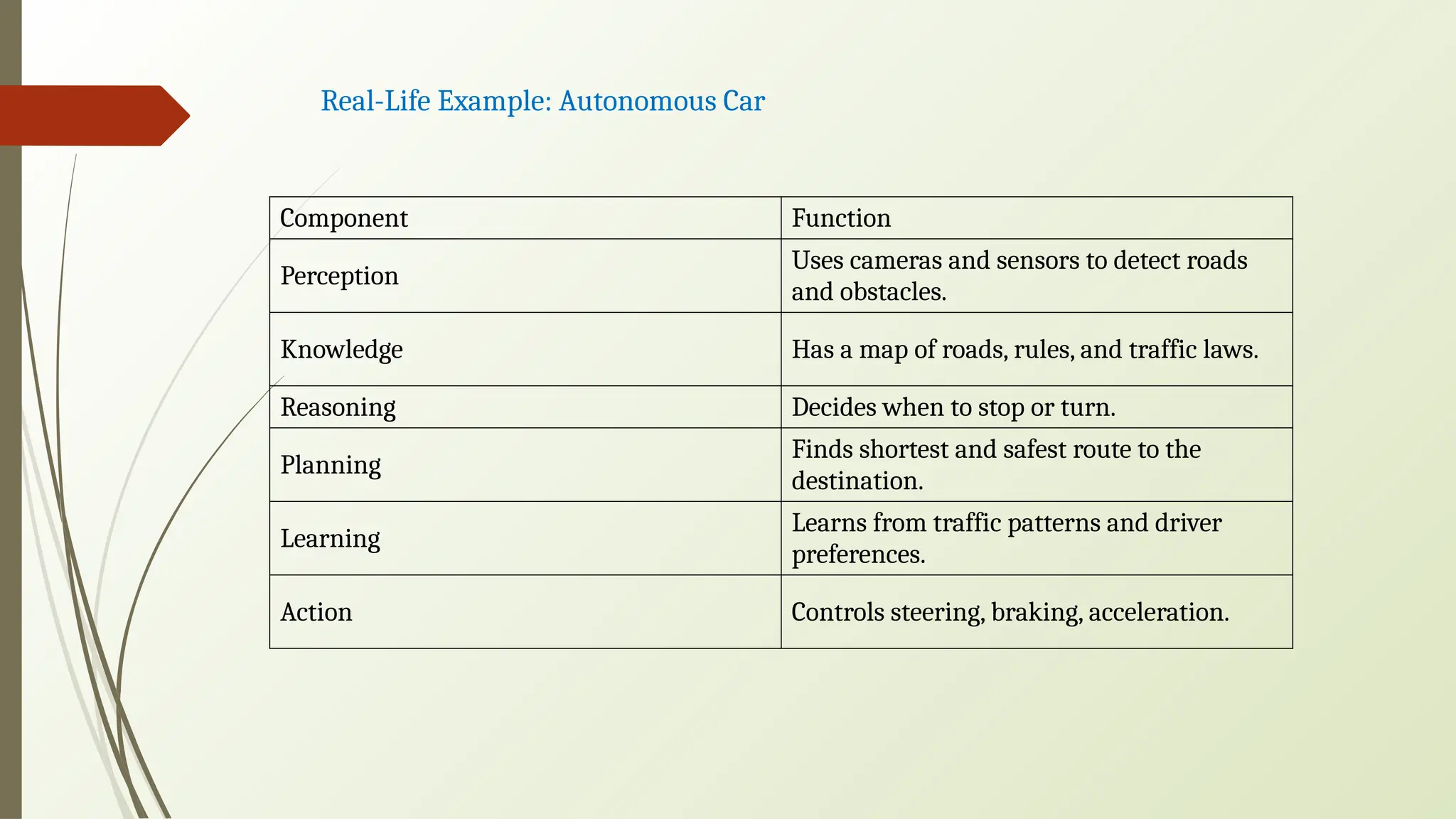
Real-Life Example: AutonomousCar
Component Function
Perception
Uses cameras and sensors to detect roads
and obstacles.
Knowledge Has a map of roads, rules, and traffic laws.
Reasoning Decides when to stop or turn.
Planning
Finds shortest and safest route to the
destination.
Learning
Learns from traffic patterns and driver
preferences.
Action Controls steering, braking, acceleration.
66.
Goal Stack Planningusing STRIPS Algorithm
What is STRIPS?
🠶 STRIPS stands for Stanford Research Institute Problem Solver.
🠶 It is an early planning system in AI that uses:
🠶 States: Described by sets of facts (predicates)
🠶 Goals: Described by a desired state
🠶 Operators (Actions): Each has:
🠶 Preconditions (what must be true to apply the action),
🠶 Add list (facts added after action),
🠶 Delete list (facts removed after action).
67.
What is GoalStack Planning?
🠶 Goal Stack Planning is a backward planning method:
🠶 The planner starts from the goal and works backward toward the initial state.
🠶 It uses a stack to keep track of:
🠶 Sub-goals to be achieved
🠶 Operators to be applied
🠶 Preconditions to be satisfied
68.
🠶 Example: BlocksWorld - We want to arrange 3 blocks (A, B, C) on a table like this:
A
B
C
🠶 Which means:
🠶 Block A is on Block B,
🠶 Block B is on Block C,
🠶 Block C is on the table.
🠶 Initial State:
🠶 ONTABLE(A), ONTABLE(B), ONTABLE(C)
🠶 CLEAR(A), CLEAR(B), CLEAR(C)
🠶 Goal State:
🠶 ON(A, B)
🠶 ON(B, C)
🠶 ONTABLE(C)
69.
🠶 Actions (Operators)
🠶MOVE(x, y, z): Move block x from block y to block z
Preconditions: ON(x, y), CLEAR(x), CLEAR(z)
Add List: ON(x, z), CLEAR(y)
Delete List: ON(x, y), CLEAR(z)
🠶 MOVE_TO_TABLE(x, y): Move block x from block y to the table
Preconditions: ON(x, y), CLEAR(x)
Add List: ONTABLE(x), CLEAR(y)
Delete List: ON(x, y)
🠶 Final Plan (in forward order):
🠶 MOVE(B, ONTABLE, C)
🠶 MOVE(A, ONTABLE, B)
70.
Concept Description
STRIPS
A formallanguage for defining planning
problems (states, goals, operators)
Goal Stack Planning
A backward planning technique that
works from goals using a stack
Approach
Push goals → push actions → push
preconditions → resolve them from
initial state














![🠶 Action Representation
🠶 Actions (also called operators) describe the possible transitions
between states. Each action consists of:
🠶 Preconditions: Conditions that must be true to perform the action
🠶 Effects: The result or change in the state after the action
🠶 Action: Move(Room1, Room2)
🠶 Preconditions: At(Robot, Room1)
🠶 Effects: ¬At(Robot, Room1), At(Robot, Room2)
Write a short note on planning agent, state goal and action representation [6]
Explain different components of planning system [6]](https://image.slidesharecdn.com/te-ai-unitvi-250731084456-c847045b/75/TE-AI-Unit-VI-notes-using-planning-model-16-2048.jpg)


















![🠶 Explain. i) Algorithm for classical planning [8] May 2023
ii) Importance of planning
🠶 Explain Planning in non deterministic domain. [5]
🠶 Explain with example, how planning is different from problem solving
[5] MAY 2023, Nov 2023
🠶 Explain different components of planning system [6] Nov 2022
🠶 What are the types of planning? Explain in detail. [6] Nov 2022
🠶 Explain Classical Planning and its advantages with example. [6] Nov 2022
🠶 Analyze various planning approaches in detail [9] May 2022](https://image.slidesharecdn.com/te-ai-unitvi-250731084456-c847045b/75/TE-AI-Unit-VI-notes-using-planning-model-35-2048.jpg)



















![🠶 Explain with an example State Space Planning
[5] May 2023, Nov 2022
🠶 Explain with an example Goal Stack Planning (STRIPS algorithm).
[5] May 2024, May 2023](https://image.slidesharecdn.com/te-ai-unitvi-250731084456-c847045b/75/TE-AI-Unit-VI-notes-using-planning-model-57-2048.jpg)
![🠶 Explain AI components and AI architecture [8]
🠶 What is AI explain scope of AI in all walks of Life also explain future opportunities with AI. [8]
🠶 Explain Limits of AI and Future opportunities with AI [5]
🠶 What is AI Explain. Scope of AI in all walks of Life also explain Future opportunities with AI [5]
🠶 Discuss AI and its ethical concerns. Explain limitations of AI [8]
🠶 Write a detailed note on AI Architecture. [5]](https://image.slidesharecdn.com/te-ai-unitvi-250731084456-c847045b/75/TE-AI-Unit-VI-notes-using-planning-model-58-2048.jpg)