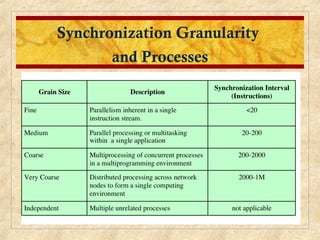
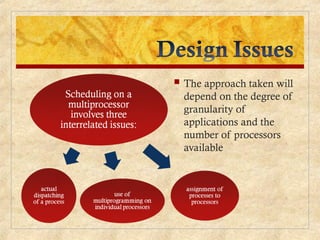
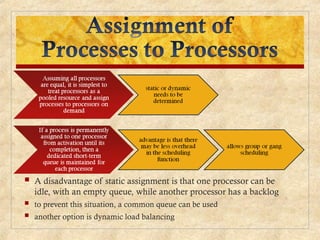
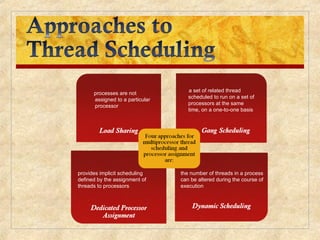
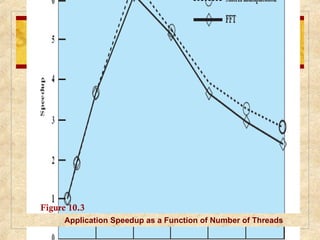
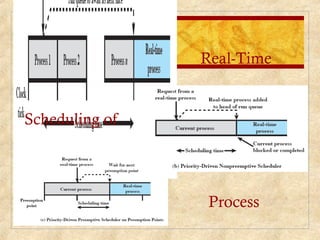
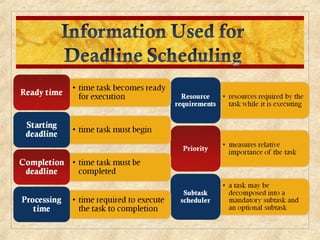
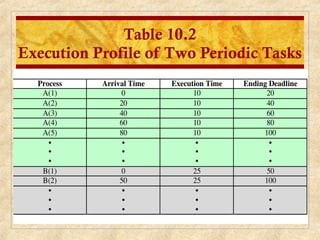
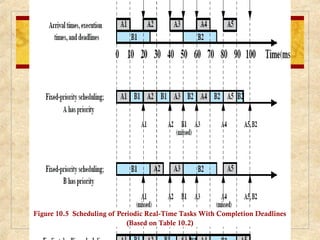
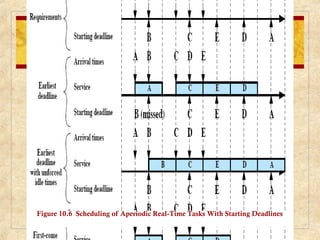
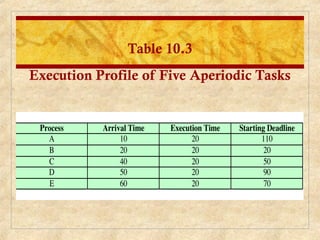
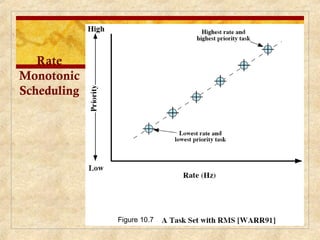
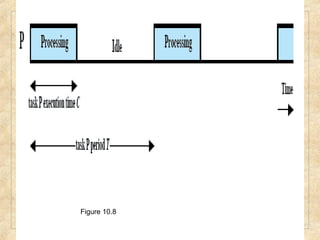
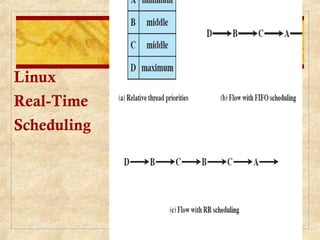
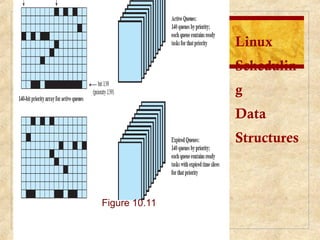
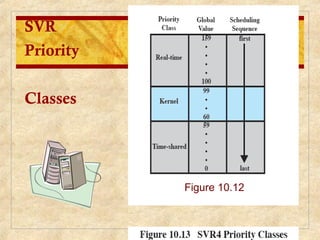
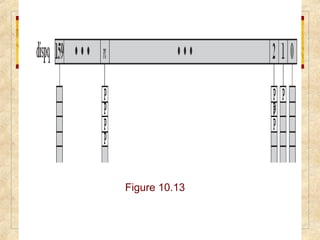
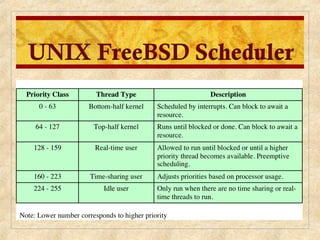
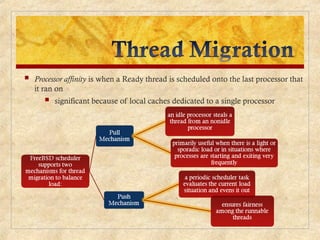
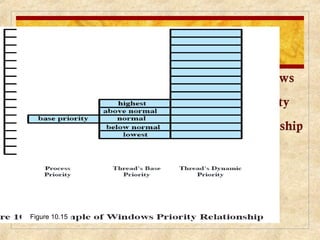
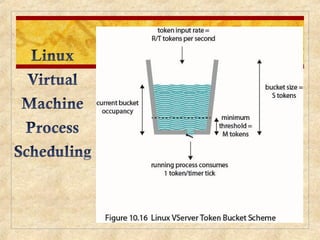
Chapter 10 discusses multiprocessor and real-time scheduling, highlighting the synchronization and scheduling of processes and threads in operating systems. It examines the advantages of using dynamic load balancing and various scheduling strategies, including real-time constraints and prioritization of tasks. The chapter also covers the evolution of scheduling algorithms in systems like Linux and Windows, emphasizing their impact on performance in multiprocessor environments.