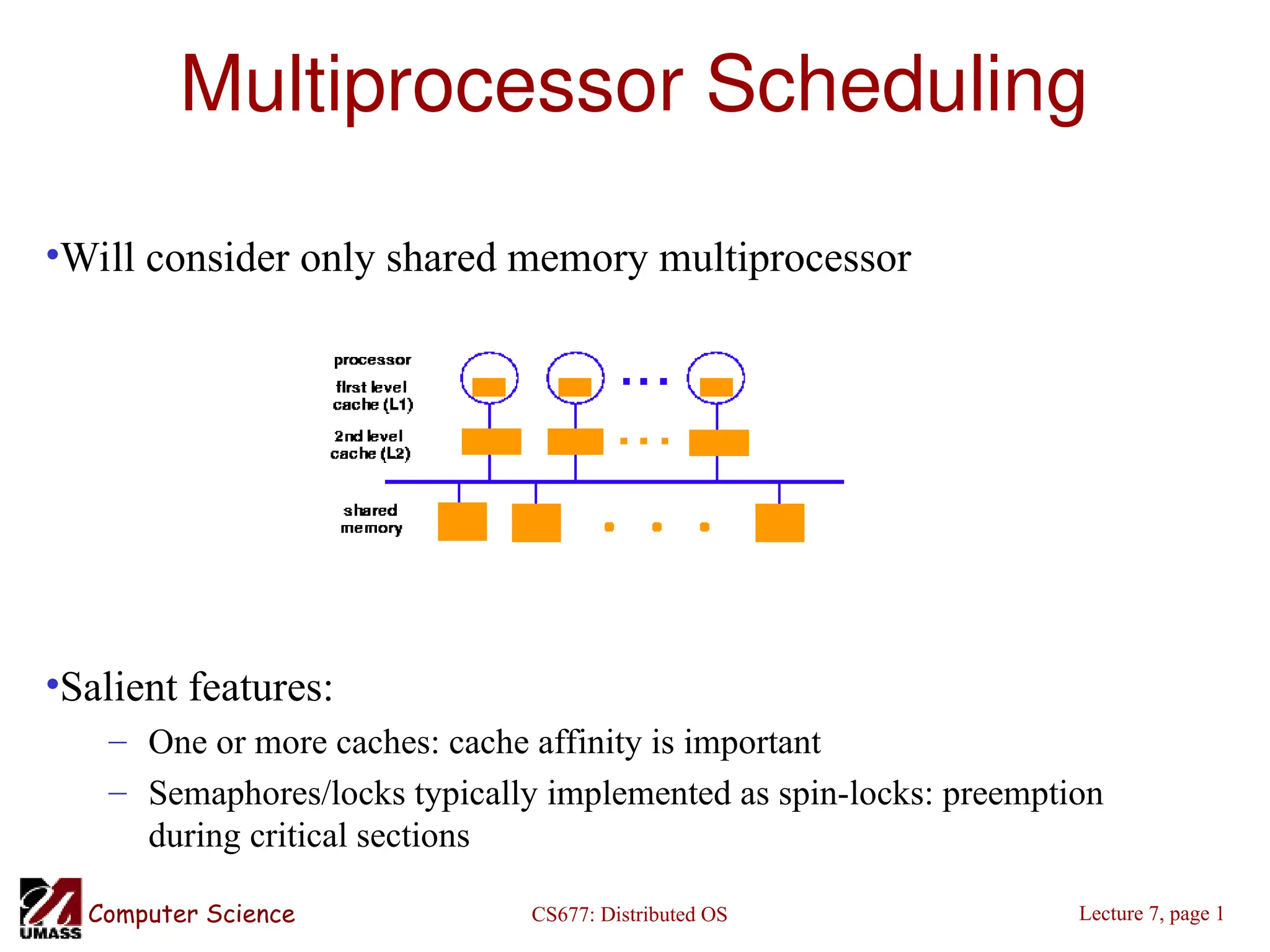
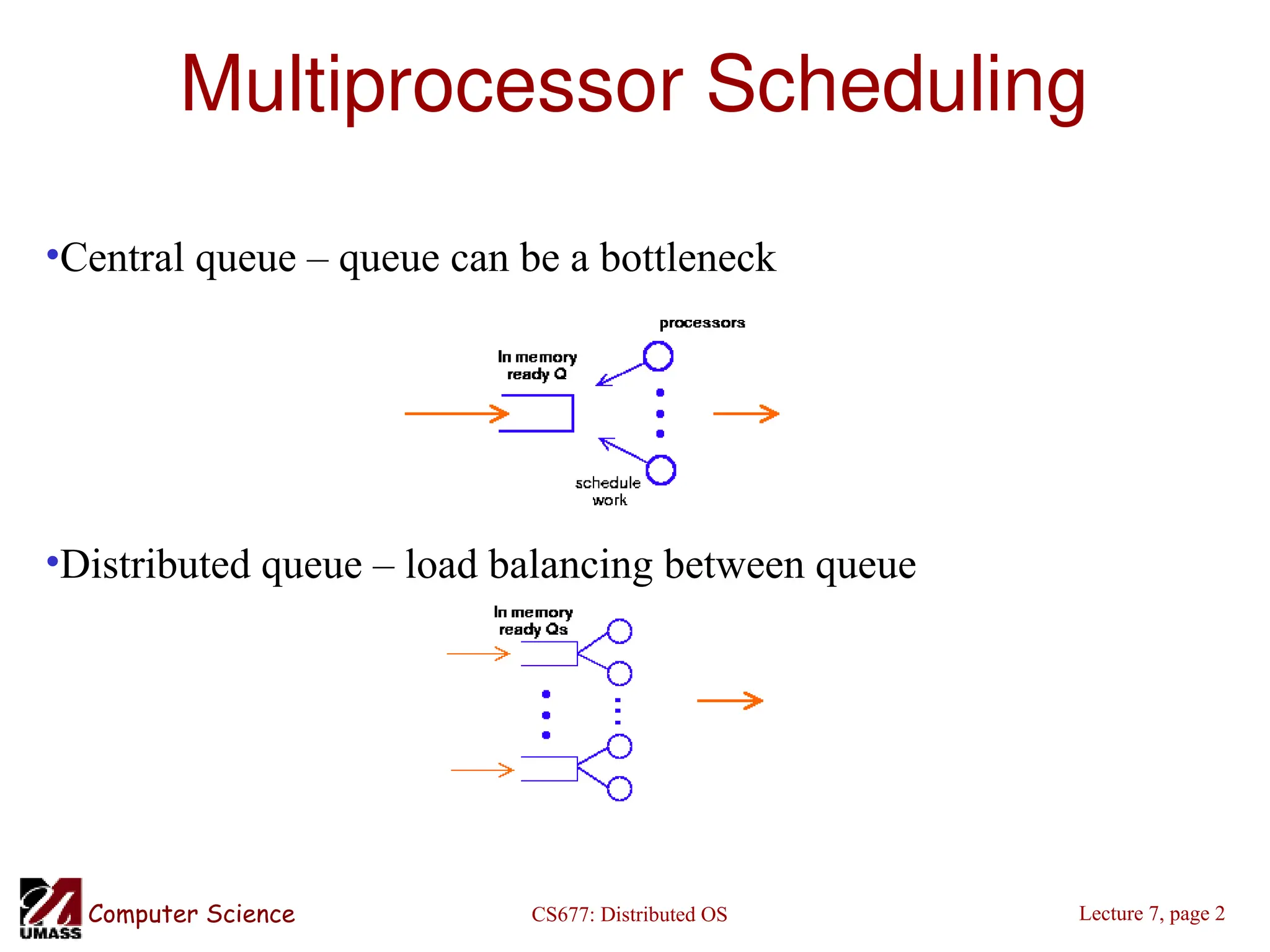
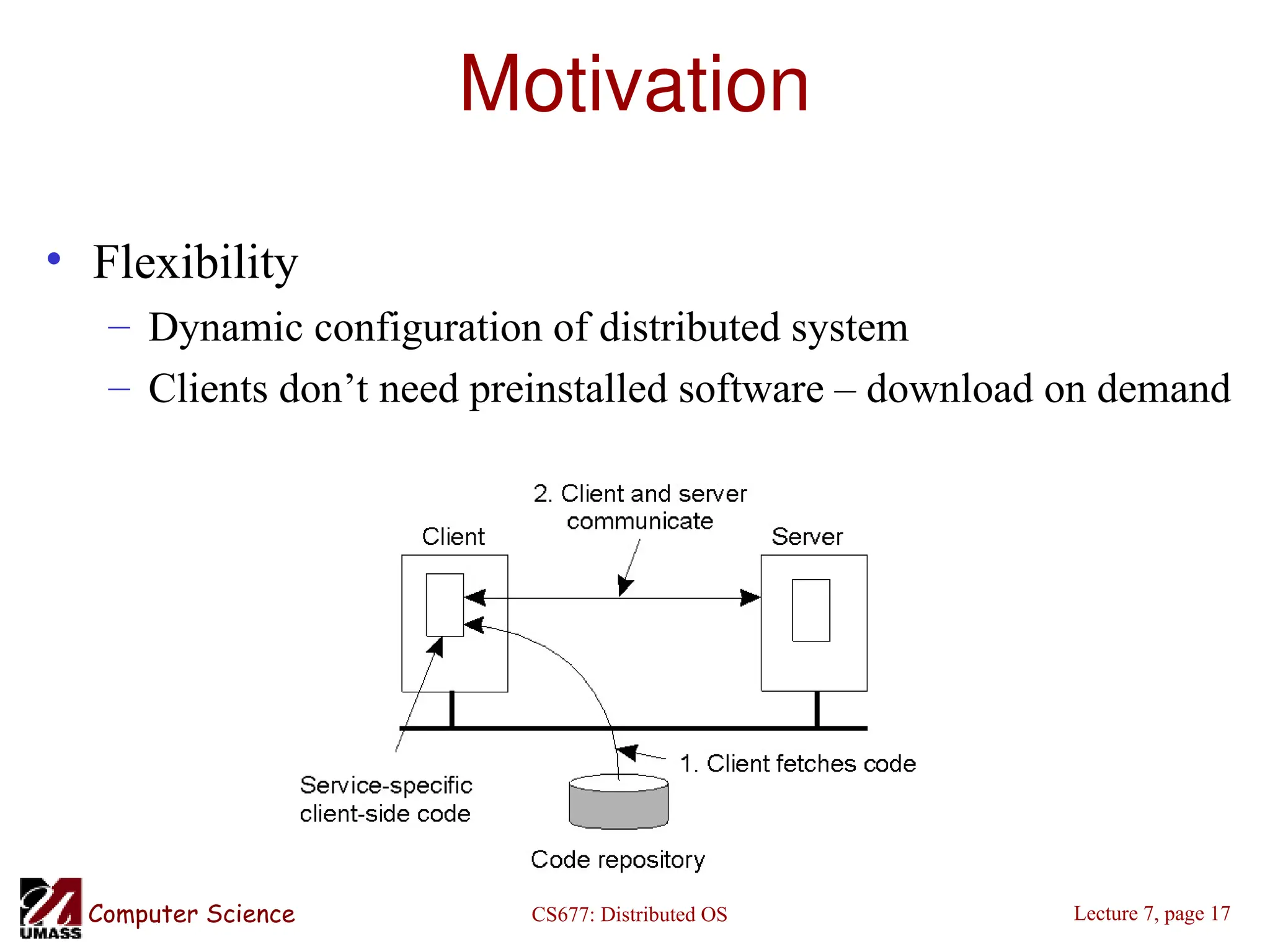
The document discusses multiprocessor scheduling in distributed operating systems, focusing on shared memory multiprocessors and the importance of cache affinity, along with various queue management strategies. It explores load balancing through distributed scheduling, detailing the design issues and migration policies for processes and resources, including sender-initiated and receiver-initiated policies. Additionally, it covers the motivations for process and code migration, along with models for executing migrated code and resources in heterogeneous systems.





![CS677: Distributed OS
Computer Science Lecture 7, page 8
Components
• Transfer policy: when to transfer a process?
– Threshold-based policies are common and easy
• Selection policy: which process to transfer?
– Prefer new processes
– Transfer cost should be small compared to execution cost
• Select processes with long execution times
• Location policy: where to transfer the process?
– Polling, random, nearest neighbor
• Information policy: when and from where?
– Demand driven [only if sender/receiver], time-driven
[periodic], state-change-driven [send update if load changes]](https://image.slidesharecdn.com/lec07-241115161108-0d33ba58/75/Lec07-multiprocessor-schaduling-chap-ppt-8-2048.jpg)









![CS677: Distributed OS
Computer Science Lecture 7, page 19
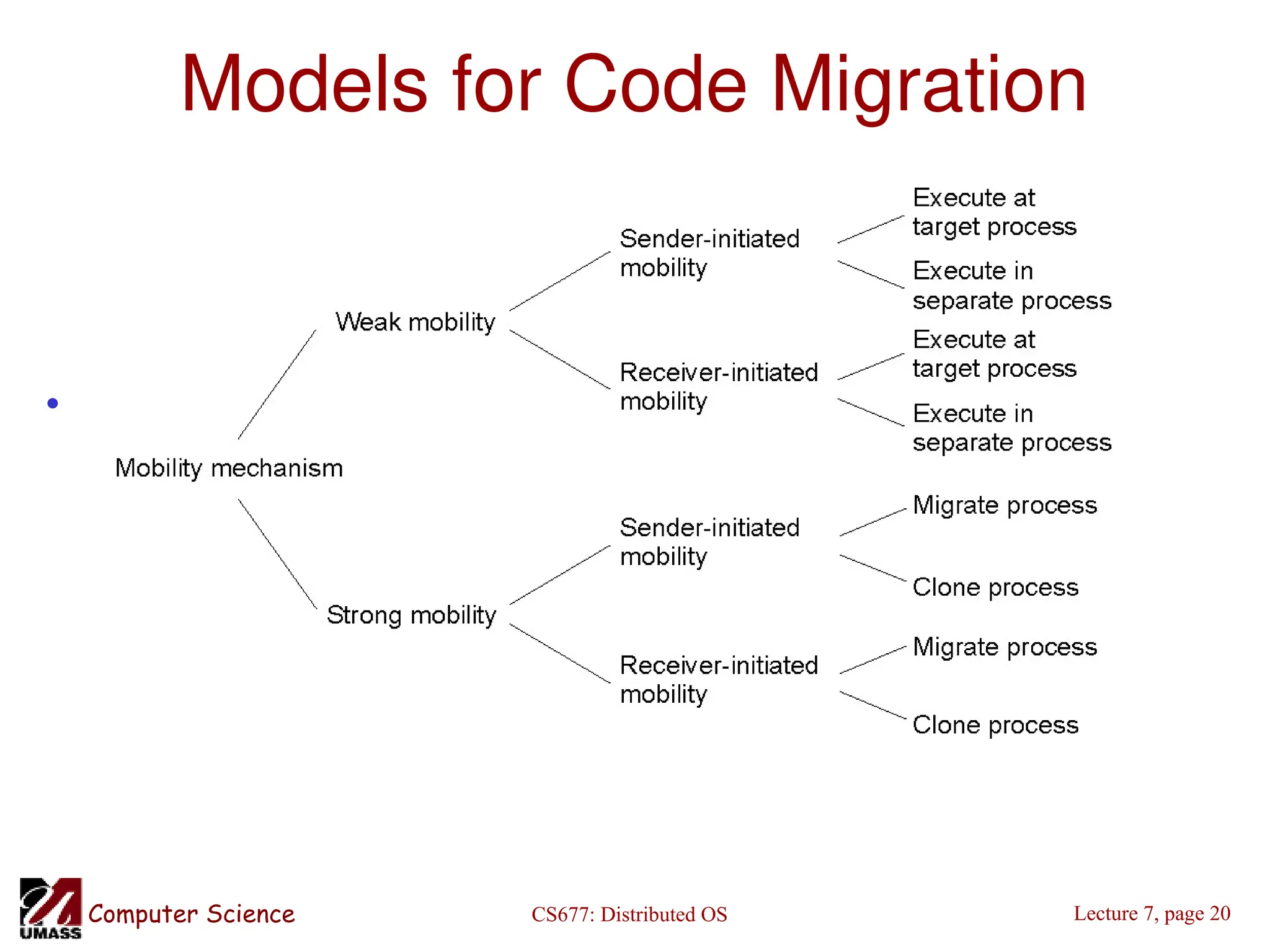
Who executes migrated entity?
• Code migration:
– Execute in a separate process
– [Applets] Execute in target process
• Process migration
– Remote cloning
– Migrate the process](https://image.slidesharecdn.com/lec07-241115161108-0d33ba58/75/Lec07-multiprocessor-schaduling-chap-ppt-19-2048.jpg)


![CS677: Distributed OS
Computer Science Lecture 7, page 23
Migration in Heterogeneous Systems
• Systems can be heterogeneous (different architecture, OS)
– Support only weak mobility: recompile code, no run time information
– Strong mobility: recompile code segment, transfer execution segment
[migration stack]
– Virtual machines - interpret source (scripts) or intermediate code [Java]](https://image.slidesharecdn.com/lec07-241115161108-0d33ba58/75/Lec07-multiprocessor-schaduling-chap-ppt-23-2048.jpg)



































































