Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
KazuhiroSato8
PDF, PPTX
117 views
Casual learning machine learning with_excel_no2
エクテックカジュアル勉強会 『Excelで機械学習入門(第2回)』 の投影資料となります。
Education
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 88
2
/ 88
3
/ 88
4
/ 88
5
/ 88
6
/ 88
7
/ 88
8
/ 88
9
/ 88
10
/ 88
11
/ 88
12
/ 88
13
/ 88
14
/ 88
15
/ 88
16
/ 88
17
/ 88
18
/ 88
19
/ 88
20
/ 88
21
/ 88
22
/ 88
23
/ 88
24
/ 88
25
/ 88
26
/ 88
27
/ 88
28
/ 88
29
/ 88
30
/ 88
31
/ 88
32
/ 88
33
/ 88
34
/ 88
35
/ 88
36
/ 88
37
/ 88
38
/ 88
39
/ 88
40
/ 88
41
/ 88
42
/ 88
43
/ 88
44
/ 88
45
/ 88
46
/ 88
47
/ 88
48
/ 88
49
/ 88
50
/ 88
51
/ 88
52
/ 88
53
/ 88
54
/ 88
55
/ 88
56
/ 88
57
/ 88
58
/ 88
59
/ 88
60
/ 88
61
/ 88
62
/ 88
63
/ 88
64
/ 88
65
/ 88
66
/ 88
67
/ 88
68
/ 88
69
/ 88
70
/ 88
71
/ 88
72
/ 88
73
/ 88
74
/ 88
75
/ 88
76
/ 88
77
/ 88
78
/ 88
79
/ 88
80
/ 88
81
/ 88
82
/ 88
83
/ 88
84
/ 88
85
/ 88
86
/ 88
87
/ 88
88
/ 88
More Related Content
PDF
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
PDF
Casual learning machine_learning_with_excel_no7
by
KazuhiroSato8
PDF
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
PDF
Casual learning-machinelearningwithexcelno8
by
KazuhiroSato8
PDF
130604 fpgax kibayos
by
Mikio Yoshida
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
Casual learning machine_learning_with_excel_no7
by
KazuhiroSato8
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
Casual learning-machinelearningwithexcelno8
by
KazuhiroSato8
130604 fpgax kibayos
by
Mikio Yoshida
はじめてのパターン認識輪読会 10章後半
by
koba cky
What's hot
PDF
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PDF
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
Oshasta em
by
Naotaka Yamada
PDF
20170408cvsaisentan6 2 4.3-4.5
by
Takuya Minagawa
PDF
Clustering _ishii_2014__ch10
by
Kota Mori
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
PDF
動的計画法
by
京大 マイコンクラブ
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
第2回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PPTX
Introduction to Persistence Theory
by
Tatsuki SHIMIZU
PDF
Fisher Vectorによる画像認識
by
Takao Yamanaka
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PDF
Objectnessとその周辺技術
by
Takao Yamanaka
PDF
第5章 拡張モデル(前半)
by
Akito Nakano
PDF
線形識別モデル
by
貴之 八木
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
20170422 数学カフェ Part1
by
Kenta Oono
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
Oshasta em
by
Naotaka Yamada
20170408cvsaisentan6 2 4.3-4.5
by
Takuya Minagawa
Clustering _ishii_2014__ch10
by
Kota Mori
Rで学ぶロバスト推定
by
Shintaro Fukushima
動的計画法
by
京大 マイコンクラブ
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
第2回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
グラフニューラルネットワーク入門
by
ryosuke-kojima
Introduction to Persistence Theory
by
Tatsuki SHIMIZU
Fisher Vectorによる画像認識
by
Takao Yamanaka
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
Objectnessとその周辺技術
by
Takao Yamanaka
第5章 拡張モデル(前半)
by
Akito Nakano
線形識別モデル
by
貴之 八木
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
Similar to Casual learning machine learning with_excel_no2
PDF
わかりやすいパターン認識_3章
by
weda654
PPT
Introduction to Algorithms#24 Shortest-Paths Problem
by
Naoya Ito
PDF
双対性
by
Yoichi Iwata
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
PDF
社内機械学習勉強会 #5
by
shingo suzuki
PDF
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
強化学習その2
by
nishio
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
オンライン学習 : Online learning
by
Daiki Tanaka
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PPTX
これならわかる最適化数学8章_動的計画法
by
kenyanonaka
PPTX
SVM
by
Yuki Nakayama
PDF
LPマスターへの道
by
KoseiTeramoto
PDF
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
PDF
大規模凸最適化問題に対する勾配法
by
京都大学大学院情報学研究科数理工学専攻
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
ラグランジュ未定乗数法
by
弘毅 露崎
PDF
これから始めるディープラーニング
by
Okamoto Laboratory, The University of Electro-Communications
わかりやすいパターン認識_3章
by
weda654
Introduction to Algorithms#24 Shortest-Paths Problem
by
Naoya Ito
双対性
by
Yoichi Iwata
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
社内機械学習勉強会 #5
by
shingo suzuki
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
W8PRML5.1-5.3
by
Masahito Ohue
強化学習その2
by
nishio
PRML Chapter 5
by
Masahito Ohue
オンライン学習 : Online learning
by
Daiki Tanaka
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
これならわかる最適化数学8章_動的計画法
by
kenyanonaka
SVM
by
Yuki Nakayama
LPマスターへの道
by
KoseiTeramoto
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
大規模凸最適化問題に対する勾配法
by
京都大学大学院情報学研究科数理工学専攻
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
ラグランジュ未定乗数法
by
弘毅 露崎
これから始めるディープラーニング
by
Okamoto Laboratory, The University of Electro-Communications
More from KazuhiroSato8
PDF
Casual learning anomaly_detection_with_machine_learning_no1
by
KazuhiroSato8
PDF
Casual data analysis_with_python_vol2
by
KazuhiroSato8
PDF
Casual datascience vol5
by
KazuhiroSato8
PDF
Basic deep learning_framework
by
KazuhiroSato8
PDF
Casual learning machine_learning_with_excel_no1
by
KazuhiroSato8
PDF
エクテック カジュアル勉強会 データサイエンスを学ぶ第2回
by
KazuhiroSato8
PDF
エクテック カジュアル勉強会 データサイエンスを学ぶ第1回
by
KazuhiroSato8
PDF
Casual data analysis_with_python_vol1
by
KazuhiroSato8
PDF
Casual datascience vol4
by
KazuhiroSato8
PDF
Casual datascience vol3
by
KazuhiroSato8
PDF
Casual datascience vol2
by
KazuhiroSato8
PDF
Casual datascience vol1
by
KazuhiroSato8
Casual learning anomaly_detection_with_machine_learning_no1
by
KazuhiroSato8
Casual data analysis_with_python_vol2
by
KazuhiroSato8
Casual datascience vol5
by
KazuhiroSato8
Basic deep learning_framework
by
KazuhiroSato8
Casual learning machine_learning_with_excel_no1
by
KazuhiroSato8
エクテック カジュアル勉強会 データサイエンスを学ぶ第2回
by
KazuhiroSato8
エクテック カジュアル勉強会 データサイエンスを学ぶ第1回
by
KazuhiroSato8
Casual data analysis_with_python_vol1
by
KazuhiroSato8
Casual datascience vol4
by
KazuhiroSato8
Casual datascience vol3
by
KazuhiroSato8
Casual datascience vol2
by
KazuhiroSato8
Casual datascience vol1
by
KazuhiroSato8
Casual learning machine learning with_excel_no2
1.
カジュアル勉強会 @仙台 Excelで機械学習入門 第2回 株式会社
エクテック 取締役 兼データサイエンティスト
2.
第10回までの流れ 1回~3回 4回~10回 AI周辺の 基本知識 最適化の基本 推論の基本 重回帰分析 機械学習 サポートベクタマシン ナイーブベイズ ニューラルネットワーク RNN/BPTT 強化学習/Q学習
3.
前段
4.
勉強会に参加する以上...
5.
『なにか』を 持って帰って欲しい
6.
『すべて』は難しいけれど 気になった、興味をもった キーワードでも良いので ⼿元に持って帰って いただけると幸いです
7.
環境について (Surroundings)
8.
Excel 2013, 2016 Google
Spreadsheets
9.
本日のアジェンダ 1. 最適化計算の基本となる勾配降下法 2. ラグランジュの緩和法と双対問題 3.
モンテカルロ法の基本
10.
最適化計算の基本となる勾配降下法
11.
前回の話で...
12.
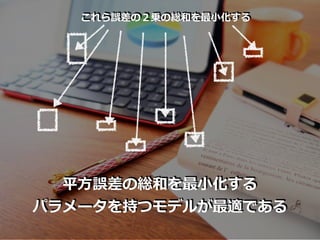
これら誤差の2乗の総和を最⼩化する 平⽅誤差の総和を最⼩化する パラメータを持つモデルが最適である
13.
『最⼩化するパラメータを持つ モデルが最適である』
14.
少し、脱線します
15.
そもそも、 パラメータを最適化する⽬的
17.
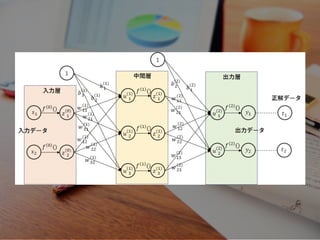
ニューラルネットワーク
18.
『シナプスの結合によりネットワークを形成した ⼈⼯ニューロン(ノード)が、学習によって シナプスの結合強度を変化させ、 問題解決能⼒を持つようなモデル全般を指す。 狭義には誤差逆伝播法を⽤いた多層パーセプトロンを 指す場合もある。⼀般的なニューラルネットワークでの ⼈⼯ニューロンは⽣体のニューロンの動作を極めて 簡易化したものを利⽤する。』 (Wikipediaより)
19.
⼈の脳を模した、 数理学に基づいた機械的な処理
20.
『⼈の脳を模し』た
22.
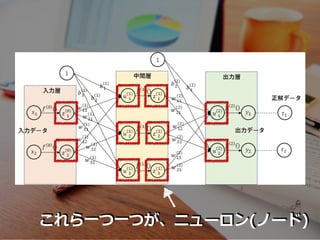
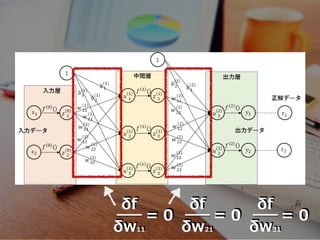
これら⼀つ⼀つが、ニューロン(ノード)
23.
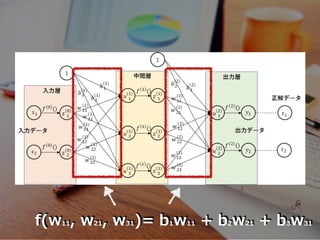
f(w11, w21, w31)=
b1w11 + b2w21 + b3w31
24.
δf δw11 = 0 δf δw21 = 0 δf δw31 =
0
25.
簡略化して描いてますが
26.
こういった層が多層化され、 ニューロンは数万、数⼗万単位で 膨⼤な⽅程式を解く必要がある
27.
『最⼩化するパラメータを持つ モデルが最適である』
28.
最⼩化するパラメータを探すのに 有名な⼿法の⼀つに
29.
勾配降下法 (最急降下法)
30.
勾配 = 微分
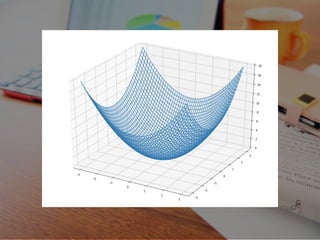
31.
δf(x,y) δx = 0, δf(x,y) δy = 0 2変数以上
= 偏微分
32.
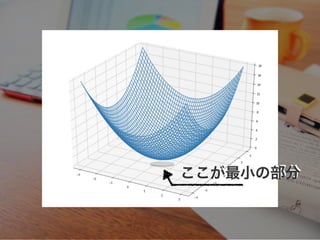
2変数について
34.
ここが最小の部分
35.
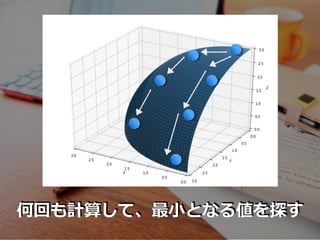
⼀般に、偏微分⽅程式は 容易には解けません (厳密解を求めることが難しい)
36.
何回も計算して、最⼩となる値を探す
37.
いずれ最⼩のところに⾏き着く
38.
これらを公式化してみます
39.
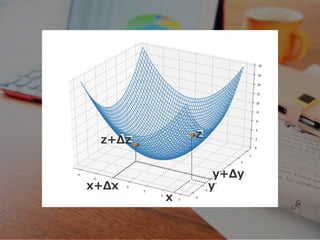
x+Δx y+Δy x y zz+Δz
40.
Δz = f(x+Δx,
y+Δy) - f(x, y) 変化 Δzは
41.
Δz = f(x+Δx,
y+Δy) - f(x, y) 変化 Δzは f(x+Δx, y+Δy) = f(x, y) + δf(x,y) δy Δy δf(x,y) δx Δx + ※近似の公式 Δz = δf(x,y) δx Δx + δf(x,y) δy Δy
42.
これを内積の形で表現すると
43.
δf(x,y) δx , δf(x,y) δy Δx Δy Δz =
44.
関数f(x,y)の点(x,y)における 勾配(gradient) といいます (勾配ベクトル) δf(x,y) δx , δf(x,y) δy Δx Δy Δz =
45.
勾配降下法の基本式
46.
η (イータ, eta)は ステップサイズ,
ステップ幅と呼ばれます δf(x,y) δx , δf(x,y) δy (Δx, Δy) = - η (ただし, ηは正の定数)
47.
マイナスη これが意味するのは
48.
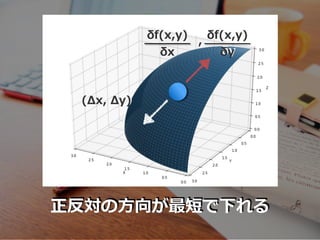
正反対の⽅向が最短で下れる δf(x,y) δx , δf(x,y) δy (Δx, Δy)
49.
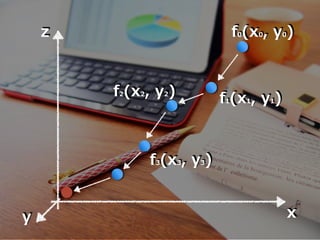
x z f0(x0, y0) y f1(x1,
y1)f2(x2, y2) f3(x3, y3)
50.
x z f0(x0, y0) y f1(x1,
y1)f2(x2, y2) f3(x3, y3) 繰り返し計算していく
51.
3変数以上について
52.
δf δx1 , δf δxn (Δx1, Δx2, …,
Δxn) = - η ( δf δx2 , … , )
53.
δf δx1 , δf δxn (Δx1, Δx2, …,
Δxn) = - η ( δf δx2 , … , ) 関数fの点(x1, x2, … , xn)における 勾配
54.
ηと勾配降下法の注意点
55.
ηが⼤きすぎると
56.
ηが⼩さすぎると
57.
明確な、確実な⽅法はない
58.
地道に 試⾏錯誤で⾒つけ出す
59.
ラグランジュの緩和法と双対問題
60.
かなり簡素化して書きますが 本来は、奥深い単元です (時間の都合上、掘り下げません)
61.
基本は、勾配降下法と同じ ただし、条件式が追加されます
62.
不等式の条件が付けられたとき 最⼤値と最⼩値を求める問題
63.
代表的な⼿法の⼀つに ラグランジュ緩和法
64.
x, yは次の不等式を満たすとき - x
- y + 2 ≦ 0, x - y + 2 ≦ 0 下記の関数を最⼩化する x, y を考える 1 2 (x + y ) 2 2
65.
1 2 (x + y
) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2 0以上の任意の定数 λ, μを⽤意すれば と置くことができる
66.
λ, μを最⼩化することで 先ほどの不等式を含むややこしい問題を 『緩和』することができる
67.
ここからさらに
68.
最⼩となる m(λ, μ)
を⽤意
69.
1 2 (x + y
) + λ(-x-y+2) + μ(x-y+2) 2 2 m(λ, μ) ≦
70.
なおかつ m(λ, μ)が 『最⼤』となる値
m0 を⽤意すると
71.
m(λ, μ) ≦
m0 ≦ 1 2 (x + y ) + λ(-x-y+2) + μ(x-y+2) 2 2 ≦ 1 2 (x + y ) 2 2
72.
この λ, μ
が得られれば 『x + y を最⼩化するx, yの値』 が得られる 2 2
73.
最⼩値を求める問題から 最⼤値を求める問題へ
74.
ラグランジュ双体
75.
ここから実際に解いてみます チョット計算を頑張りましょう
76.
ラグランジュ緩和法の左辺 = 1 2 {x -
(λ - μ)} + 2 1 2 {y - (λ + μ)} 2 1 2 {(λ - μ) + (λ +μ) } + 2(λ + μ)- 2 2 = 1 2 {x - (λ - μ)} + 2 1 2 {y - (λ + μ)} 2 + 2(λ + μ) - (λ + μ ) 2 2
77.
よって、x,y が x =
λ - μ, y = λ + μ のとき 最⼩値となる
78.
よって、x,y が x =
λ - μ, y = λ + μ のとき 最⼩値となり、元々の不等式 - x - y + 2 ≦ 0, x - y + 2 ≦ 0 に代⼊して整理すると λ ≧ 1, μ ≧ 1
79.
⼀⽅、最⼩値 m(λ, μ)は m(λ,
μ) = 2(λ + μ) - (λ + μ ) = 2 - (λ - 1) + (μ - 1) 2 2 2 2
80.
λ ≧ 1,
μ ≧ 1 と合わせて 最⼤値m0 は m0 = 2 (λ = 1, μ = 1)
81.
このとき、x, y は
x=0, y=2 そして、x + y の最⼩値は 2 2 2
82.
モンテカルロ法の基本
83.
広く⼀般に、乱数を⽤いて 数値計算を⾏う⽅法
84.
機械学習のほとんどの分野で 初期値としての乱数を、 モンテカルロ法で与えている
85.
Excelで実践 Google Spreadsheetで実践
86.
第2回は、 以上となります
87.
ご不明点・ご質問・ご相談は Slackで無償でお答えいたします
88.
EoF
Download


























































































![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)














































