Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
DataWorks Summit/Hadoop Summit
PPTX, PDF
3,900 views
Case Study: OLAP usability on Spark and Hadoop
Case Study: OLAP usability on Spark and Hadoop
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 23 times
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
PDF
Case study of DevOps for Hadoop in Recruit.
by
DataWorks Summit/Hadoop Summit
PDF
20130313 OSCA Hadoopセミナー
by
Ichiro Fukuda
PPTX
The truth about SQL and Data Warehousing on Hadoop
by
DataWorks Summit/Hadoop Summit
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
Data Science on Hadoop
by
Yifeng Jiang
PPTX
Struggle against crossdomain data complexity in Recruit Group
by
DataWorks Summit/Hadoop Summit
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
Case study of DevOps for Hadoop in Recruit.
by
DataWorks Summit/Hadoop Summit
20130313 OSCA Hadoopセミナー
by
Ichiro Fukuda
The truth about SQL and Data Warehousing on Hadoop
by
DataWorks Summit/Hadoop Summit
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
Data Science on Hadoop
by
Yifeng Jiang
Struggle against crossdomain data complexity in Recruit Group
by
DataWorks Summit/Hadoop Summit
What's hot
PDF
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
PDF
NTT Communications' Initiatives to Utilize Infrastructure Data
by
DataWorks Summit
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PDF
Big Data Visual Analytics Realized By Hadoop and Tableau
by
DataWorks Summit
PDF
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
PDF
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
PPTX
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
PDF
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
MapR Streams & MapR コンバージド・データ・プラットフォーム
by
MapR Technologies Japan
PDF
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
PDF
The real world use of Big Data to change business
by
DataWorks Summit/Hadoop Summit
PDF
最新事例から学ぶビッグデータの活用法 #ocif16 #hortonworks
by
Kimihiko Kitase
PDF
Deep Learning On Apache Spark
by
Yuta Imai
PPTX
データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
by
Yoshikazu Suganuma
PDF
(LT)Spark and Cassandra
by
datastaxjp
PDF
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PPTX
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
NTT Communications' Initiatives to Utilize Infrastructure Data
by
DataWorks Summit
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
Big Data Visual Analytics Realized By Hadoop and Tableau
by
DataWorks Summit
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
MapR Streams & MapR コンバージド・データ・プラットフォーム
by
MapR Technologies Japan
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
The real world use of Big Data to change business
by
DataWorks Summit/Hadoop Summit
最新事例から学ぶビッグデータの活用法 #ocif16 #hortonworks
by
Kimihiko Kitase
Deep Learning On Apache Spark
by
Yuta Imai
データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
by
Yoshikazu Suganuma
(LT)Spark and Cassandra
by
datastaxjp
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
Yifeng spark-final-public
by
Yifeng Jiang
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
Viewers also liked
PDF
データ分析グループの組織編制とその課題 マーケティングにおけるKPI設計の失敗例 ABテストの活用と、機械学習の導入 #CWT2016
by
Tokoroten Nakayama
PDF
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
PPTX
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
PPTX
SEGA : Growth hacking by Spark ML for Mobile games
by
DataWorks Summit/Hadoop Summit
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
Business Innovation cases driven by AI and BigData technologies
by
DataWorks Summit/Hadoop Summit
PDF
Hadoop’s Impact on Recruit Company
by
Recruit Technologies
PDF
Sparkを活用したレコメンドエンジンのパフォーマンスチューニング&自動化
by
Nagato Kasaki
PDF
Top 5 mistakes when writing Spark applications
by
hadooparchbook
データ分析グループの組織編制とその課題 マーケティングにおけるKPI設計の失敗例 ABテストの活用と、機械学習の導入 #CWT2016
by
Tokoroten Nakayama
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
SEGA : Growth hacking by Spark ML for Mobile games
by
DataWorks Summit/Hadoop Summit
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
Business Innovation cases driven by AI and BigData technologies
by
DataWorks Summit/Hadoop Summit
Hadoop’s Impact on Recruit Company
by
Recruit Technologies
Sparkを活用したレコメンドエンジンのパフォーマンスチューニング&自動化
by
Nagato Kasaki
Top 5 mistakes when writing Spark applications
by
hadooparchbook
Similar to Case Study: OLAP usability on Spark and Hadoop
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
PDF
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PPTX
車両運行管理システムのためのデータ整備と機械学習の活用
by
Eiji Sekiya
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PDF
ここまで来た!公共交通オープンデータ最新事情
by
Masaki Ito
PDF
オープンデータで実現する公共交通の進化
by
Masaki Ito
PDF
オープンデータ流通基盤 LinkData.org による 行政と市民の協業促進
by
Sayoko Shimoyama
PPTX
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
PDF
全国に広がる公共交通データ整備とその効果 −小規模事業者でも(だからこそ!)出来る最新データ活用−
by
Masaki Ito
PDF
公共交通オープンデータ整備で地域の移動をアップデートしよう
by
Masaki Ito
PDF
Ptod2022
by
Motomune Kataoka
PDF
標準的なバス情報フォーマットによるオープンデータを始めよう −データで地域交通をより便利に−
by
Masaki Ito
PDF
地域発オープンイノベーションで進化する公共交通の最前線
by
Masaki Ito
PDF
行政サービスにデータ資産を活かす: 公共交通データから考える行政の現場でのデータ活用のありかた
by
Masaki Ito
PDF
公共交通オープンデータの背景事情〜いろいろ降ってくる中で主体的に仕事をするために〜
by
Masaki Ito
PDF
公共交通オープンデータの背景事情〜いろいろ降ってくる中で主体的に仕事をするために〜
by
Masaki Ito
PDF
オープンデータと交通イノベーション
by
Masaki Ito
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
車両運行管理システムのためのデータ整備と機械学習の活用
by
Eiji Sekiya
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
ビッグデータ&データマネジメント展
by
Recruit Technologies
ここまで来た!公共交通オープンデータ最新事情
by
Masaki Ito
オープンデータで実現する公共交通の進化
by
Masaki Ito
オープンデータ流通基盤 LinkData.org による 行政と市民の協業促進
by
Sayoko Shimoyama
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
全国に広がる公共交通データ整備とその効果 −小規模事業者でも(だからこそ!)出来る最新データ活用−
by
Masaki Ito
公共交通オープンデータ整備で地域の移動をアップデートしよう
by
Masaki Ito
Ptod2022
by
Motomune Kataoka
標準的なバス情報フォーマットによるオープンデータを始めよう −データで地域交通をより便利に−
by
Masaki Ito
地域発オープンイノベーションで進化する公共交通の最前線
by
Masaki Ito
行政サービスにデータ資産を活かす: 公共交通データから考える行政の現場でのデータ活用のありかた
by
Masaki Ito
公共交通オープンデータの背景事情〜いろいろ降ってくる中で主体的に仕事をするために〜
by
Masaki Ito
公共交通オープンデータの背景事情〜いろいろ降ってくる中で主体的に仕事をするために〜
by
Masaki Ito
オープンデータと交通イノベーション
by
Masaki Ito
More from DataWorks Summit/Hadoop Summit
PDF
Hadoop Crash Course
by
DataWorks Summit/Hadoop Summit
PDF
Dataflow with Apache NiFi
by
DataWorks Summit/Hadoop Summit
PPT
State of Security: Apache Spark & Apache Zeppelin
by
DataWorks Summit/Hadoop Summit
PPTX
Building a Large-Scale, Adaptive Recommendation Engine with Apache Flink and ...
by
DataWorks Summit/Hadoop Summit
PDF
Apache Spark Crash Course
by
DataWorks Summit/Hadoop Summit
PDF
Real-Time Anomaly Detection using LSTM Auto-Encoders with Deep Learning4J on ...
by
DataWorks Summit/Hadoop Summit
PPTX
How Hadoop Makes the Natixis Pack More Efficient
by
DataWorks Summit/Hadoop Summit
PPTX
HBase in Practice
by
DataWorks Summit/Hadoop Summit
PPTX
Schema Registry - Set you Data Free
by
DataWorks Summit/Hadoop Summit
PPTX
Backup and Disaster Recovery in Hadoop
by
DataWorks Summit/Hadoop Summit
PPT
Running Apache Spark & Apache Zeppelin in Production
by
DataWorks Summit/Hadoop Summit
PPTX
From Regulatory Process Verification to Predictive Maintenance and Beyond wit...
by
DataWorks Summit/Hadoop Summit
PPTX
Mool - Automated Log Analysis using Data Science and ML
by
DataWorks Summit/Hadoop Summit
PDF
Unleashing the Power of Apache Atlas with Apache Ranger
by
DataWorks Summit/Hadoop Summit
PDF
Enabling Digital Diagnostics with a Data Science Platform
by
DataWorks Summit/Hadoop Summit
PPTX
The Challenge of Driving Business Value from the Analytics of Things (AOT)
by
DataWorks Summit/Hadoop Summit
PDF
Double Your Hadoop Performance with Hortonworks SmartSense
by
DataWorks Summit/Hadoop Summit
PDF
Revolutionize Text Mining with Spark and Zeppelin
by
DataWorks Summit/Hadoop Summit
PDF
Breaking the 1 Million OPS/SEC Barrier in HOPS Hadoop
by
DataWorks Summit/Hadoop Summit
PDF
Data Science Crash Course
by
DataWorks Summit/Hadoop Summit
Hadoop Crash Course
by
DataWorks Summit/Hadoop Summit
Dataflow with Apache NiFi
by
DataWorks Summit/Hadoop Summit
State of Security: Apache Spark & Apache Zeppelin
by
DataWorks Summit/Hadoop Summit
Building a Large-Scale, Adaptive Recommendation Engine with Apache Flink and ...
by
DataWorks Summit/Hadoop Summit
Apache Spark Crash Course
by
DataWorks Summit/Hadoop Summit
Real-Time Anomaly Detection using LSTM Auto-Encoders with Deep Learning4J on ...
by
DataWorks Summit/Hadoop Summit
How Hadoop Makes the Natixis Pack More Efficient
by
DataWorks Summit/Hadoop Summit
HBase in Practice
by
DataWorks Summit/Hadoop Summit
Schema Registry - Set you Data Free
by
DataWorks Summit/Hadoop Summit
Backup and Disaster Recovery in Hadoop
by
DataWorks Summit/Hadoop Summit
Running Apache Spark & Apache Zeppelin in Production
by
DataWorks Summit/Hadoop Summit
From Regulatory Process Verification to Predictive Maintenance and Beyond wit...
by
DataWorks Summit/Hadoop Summit
Mool - Automated Log Analysis using Data Science and ML
by
DataWorks Summit/Hadoop Summit
Unleashing the Power of Apache Atlas with Apache Ranger
by
DataWorks Summit/Hadoop Summit
Enabling Digital Diagnostics with a Data Science Platform
by
DataWorks Summit/Hadoop Summit
The Challenge of Driving Business Value from the Analytics of Things (AOT)
by
DataWorks Summit/Hadoop Summit
Double Your Hadoop Performance with Hortonworks SmartSense
by
DataWorks Summit/Hadoop Summit
Revolutionize Text Mining with Spark and Zeppelin
by
DataWorks Summit/Hadoop Summit
Breaking the 1 Million OPS/SEC Barrier in HOPS Hadoop
by
DataWorks Summit/Hadoop Summit
Data Science Crash Course
by
DataWorks Summit/Hadoop Summit
Recently uploaded
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
Case Study: OLAP usability on Spark and Hadoop
1.
Hadoop/SparkとOLAPの連携の使用感 (オープンデータを使って) 2016年10月27日 日本電気株式会社 新郷 美紀
2.
2 © NEC
Corporation 2016 自己紹介 氏名 新郷 美紀 ビッグデータ歴 3年。 当社のラックタイプで1台に700サーバ搭載可能な大規模のサーバ製品で Hadoop/Sparkを活用。 以降、ビッグデータ・ソリューション・アークテクトとして活動。 2015年9月よりODPi(Open Data Platform Initiative)のNECの窓口。 分散処理、分析処理基盤のアーキテクチャ検討・実装がメイン業務。
3.
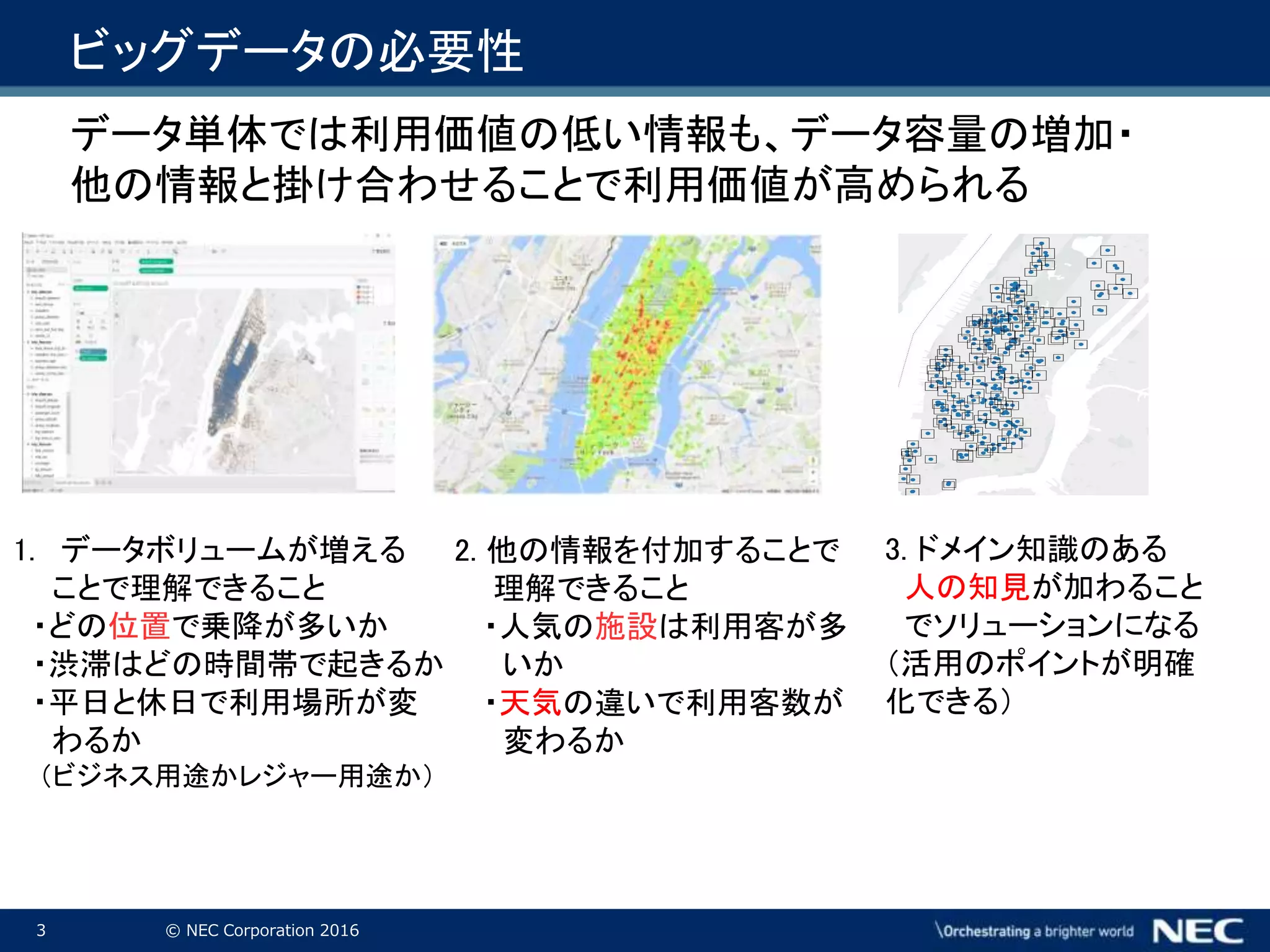
3 © NEC
Corporation 2016 ビッグデータの必要性 データ単体では利用価値の低い情報も、データ容量の増加・ 他の情報と掛け合わせることで利用価値が高められる 2. 他の情報を付加することで 理解できること ・人気の施設は利用客が多 いか ・天気の違いで利用客数が 変わるか 1. データボリュームが増える ことで理解できること ・どの位置で乗降が多いか ・渋滞はどの時間帯で起きるか ・平日と休日で利用場所が変 わるか (ビジネス用途かレジャー用途か) 3. ドメイン知識のある 人の知見が加わること でソリューションになる (活用のポイントが明確 化できる)
4.
4 © NEC
Corporation 2016 1. データ量・新たなデータタイプの増加 ・企業で扱えるデータも増えた ・さらにオープンデータも活用できるようになってきた (といっても海外の方が進んでるけど。。。。) → オープンデータだけを使ってみよう! 2. ビッグデータ処理基盤も整備されてきた ・Hadoop/Spark関連技術の進化 ・データ分析エコシステムの進歩 機械学習、ディープラーニングなどいろんなものが使えるようになってきた ・データアクセス高速化技術の進歩 OLAPツール等で使えるものが増えてきた → OLAPツールで既存のBIとの連携がどれだけ早いか試してみよう! ビッグデータを取り巻く環境
5.
5 © NEC
Corporation 2016 本日のテーマ 1. Hadoop/SparkからOLAPツールにデータを渡すための準備 2. MLlibで準備できたデータの傾向・特性を把握 3. OLAPツールを用いたBI接続の使用感 本セッションの目的 マスタデータ・ 統合データの 生成 OLAP設計・ BIツール接続 価値創造 ビジネス ユースに 資する サービスへ機械学習による データ特性把握 データ準備 データ特性 把握 データ分析・ レポート Hadoop/Sparkエコシステム とOLAP連携で実現可能 データ オープン・ データ (無料で入手 可能)
6.
6 © NEC
Corporation 2016 本日のテーマ 1. Hadoop/SparkからOLAPツールにデータを渡すための準備 2. MLlibで準備できたデータの傾向・特性を把握 3. OLAPツールを用いたBI接続の使用感 本セッションの目的 マスタデータ・ 統合データの 生成 OLAP設計・ BIツール接続 価値創造 ビジネス ユースに 資する サービスへ機械学習による データ特性把握 データ準備 データ特性 把握 データ分析・ レポート Hadoop/Sparkエコシステム とOLAP連携で実現可能 データ オープン・ データ (無料で入手 可能) データは貯めたけど 使えてない
7.
7 © NEC
Corporation 2016 本日のテーマ 1. Hadoop/SparkからOLAPツールにデータを渡すための準備 2. MLlibで準備できたデータの傾向・特性を把握 3. OLAPツールを用いたBI接続の使用感 本セッションの目的 マスタデータ・ 統合データの 生成 OLAP設計・ BIツール接続 価値創造 ビジネス ユースに 資する サービスへ機械学習による データ特性把握 データ準備 データ特性 把握 データ分析・ レポート Hadoop/Sparkエコシステム とOLAP連携で実現可能 データ オープン・ データ (無料で入手 可能) 高度分析って何に 使えるの
8.
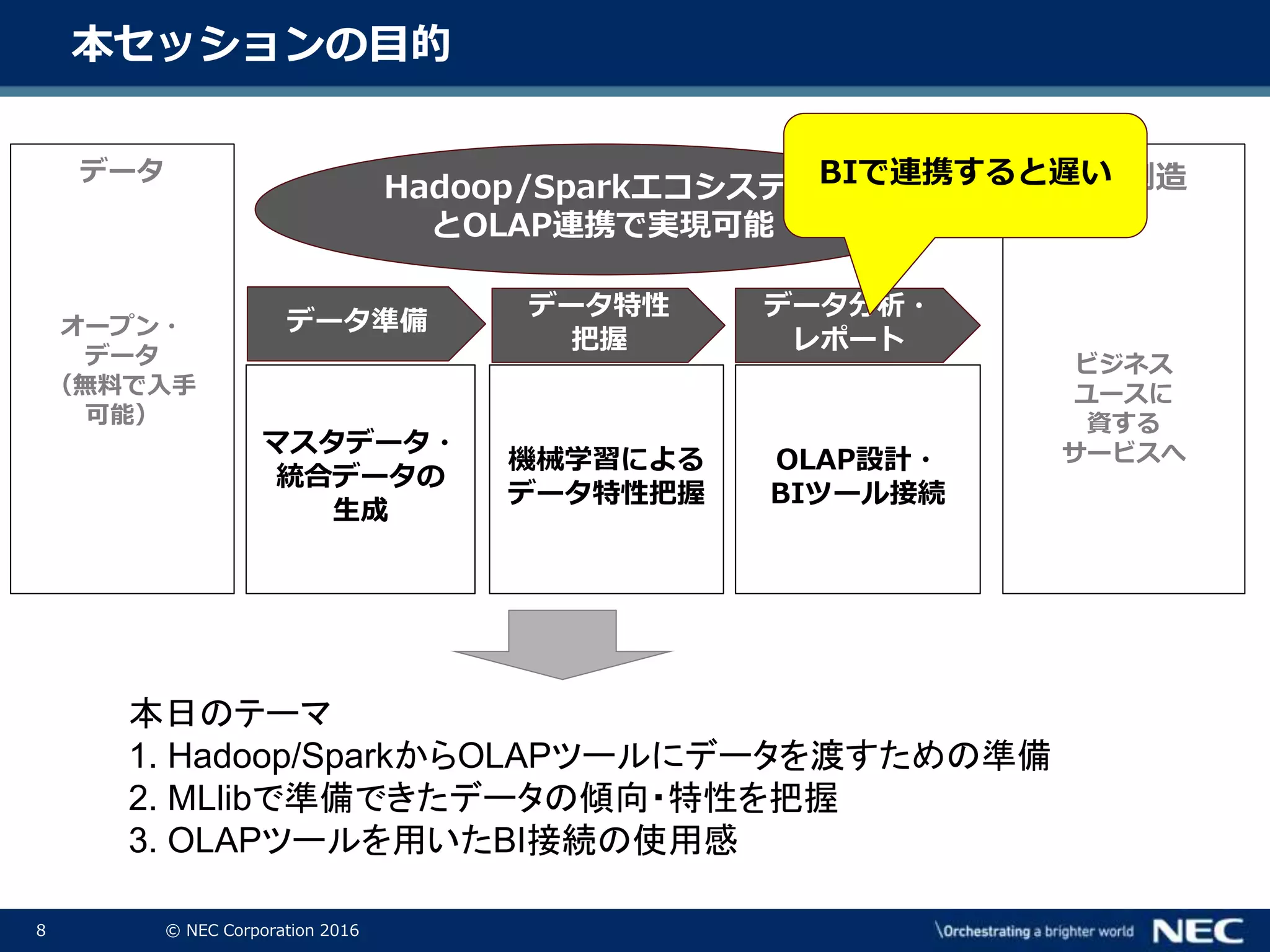
8 © NEC
Corporation 2016 本日のテーマ 1. Hadoop/SparkからOLAPツールにデータを渡すための準備 2. MLlibで準備できたデータの傾向・特性を把握 3. OLAPツールを用いたBI接続の使用感 本セッションの目的 マスタデータ・ 統合データの 生成 OLAP設計・ BIツール接続 価値創造 ビジネス ユースに 資する サービスへ機械学習による データ特性把握 データ準備 データ特性 把握 データ分析・ レポート Hadoop/Sparkエコシステム とOLAP連携で実現可能 データ オープン・ データ (無料で入手 可能) BIで連携すると遅い
9.
9 © NEC
Corporation 2016 アジェンダ 1. 今回の検証の概要 2. Hadoop/SparkからOLAPツールにデータを渡すための準備 3. MLlibで準備できたデータの傾向・特性を把握 4. OLAPツールを用いたBI接続の使用感 5. まとめ
10.
10 © NEC
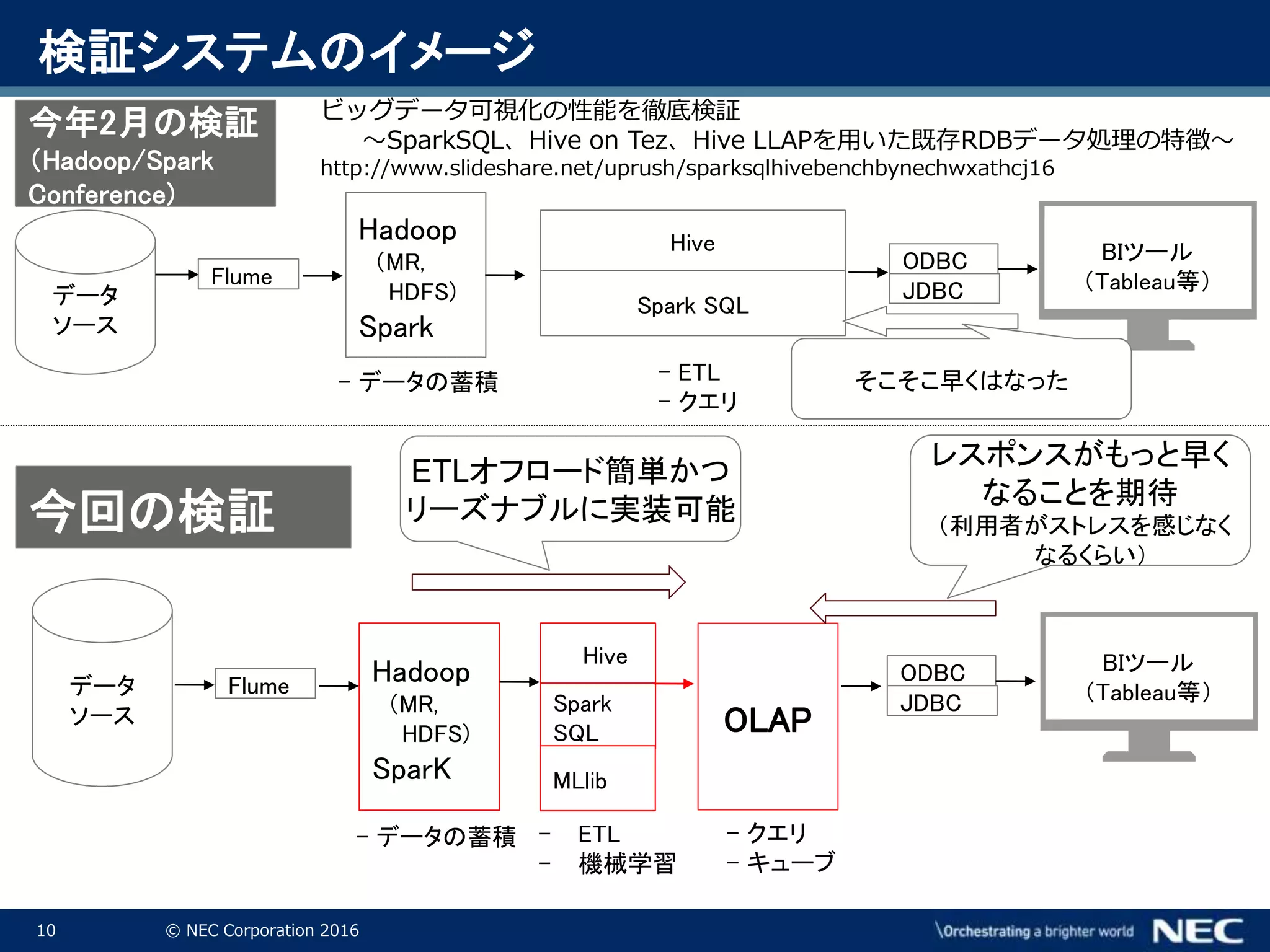
Corporation 2016 検証システムのイメージ データ ソース Flume Hadoop (MR, HDFS) Spark - データの蓄積 Hive Spark SQL ODBC JDBC OLAP BIツール (Tableau等) - ETL - クエリ 今年2月の検証 (Hadoop/Spark Conference) データ ソース Flume Hadoop (MR, HDFS) SparK Hive Spark SQL ODBC JDBC BIツール (Tableau等) - ETL - 機械学習 今回の検証 - クエリ - キューブ レスポンスがもっと早く なることを期待 (利用者がストレスを感じなく なるくらい) MLlib ETLオフロード簡単かつ リーズナブルに実装可能 - データの蓄積 ビッグデータ可視化の性能を徹底検証 ~SparkSQL、Hive on Tez、Hive LLAPを用いた既存RDBデータ処理の特徴~ http://www.slideshare.net/uprush/sparksqlhivebenchbynechwxathcj16 そこそこ早くはなった
11.
11 © NEC
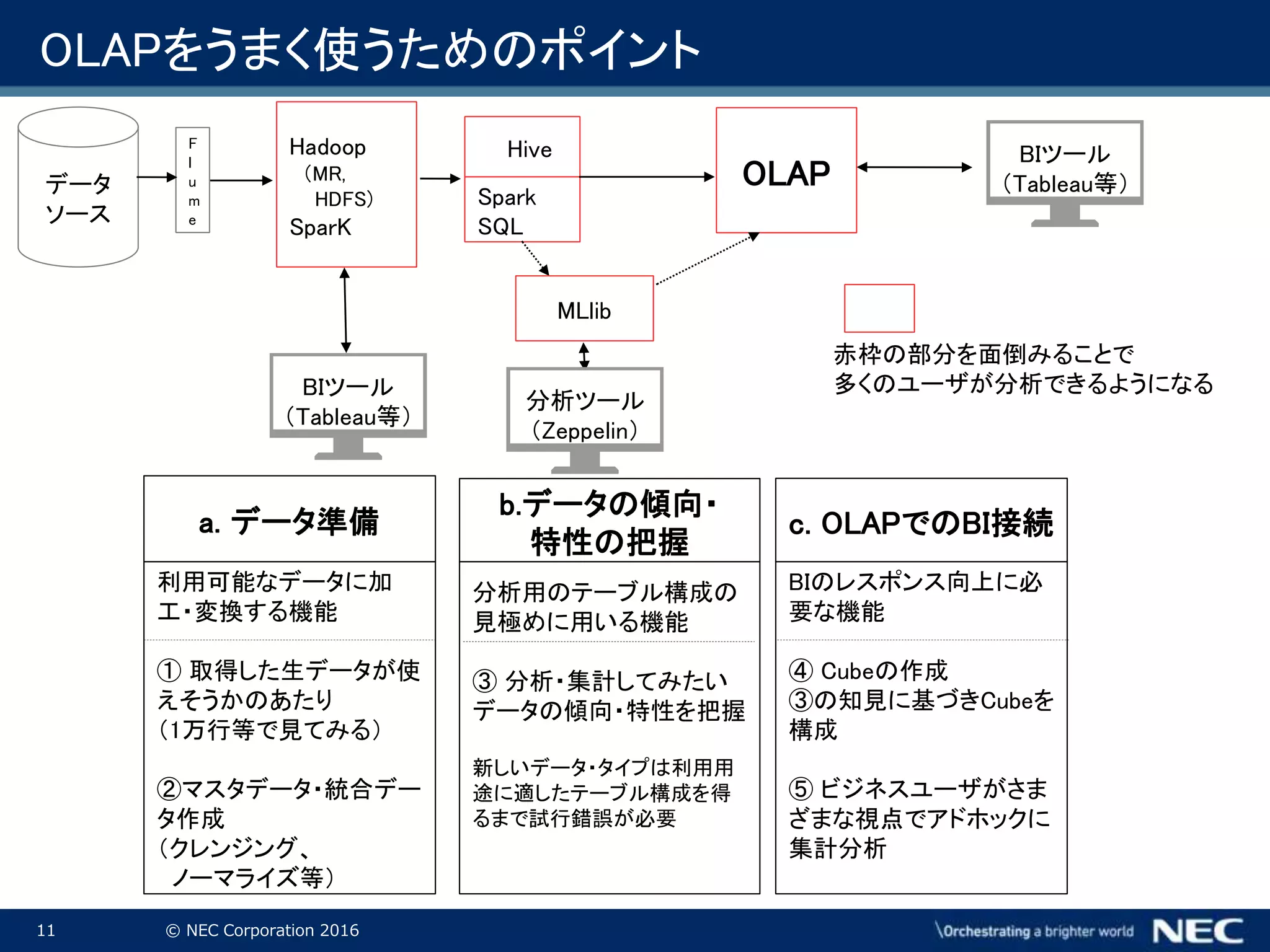
Corporation 2016 OLAPをうまく使うためのポイント OLAPデータ ソース F l u m e Hadoop (MR, HDFS) SparK Hive Spark SQL BIツール (Tableau等) MLlib 赤枠の部分を面倒みることで 多くのユーザが分析できるようになる BIツール (Tableau等) 分析ツール (Zeppelin) 利用可能なデータに加 工・変換する機能 ① 取得した生データが使 えそうかのあたり (1万行等で見てみる) ②マスタデータ・統合デー タ作成 (クレンジング、 ノーマライズ等) a. データ準備 分析用のテーブル構成の 見極めに用いる機能 ③ 分析・集計してみたい データの傾向・特性を把握 新しいデータ・タイプは利用用 途に適したテーブル構成を得 るまで試行錯誤が必要 b.データの傾向・ 特性の把握 BIのレスポンス向上に必 要な機能 ④ Cubeの作成 ③の知見に基づきCubeを 構成 ⑤ ビジネスユーザがさま ざまな視点でアドホックに 集計分析 c. OLAPでのBI接続
12.
12 © NEC
Corporation 2016 検証内容と利用リソースの概要 実施内容: ニューヨークタクシーのオープンデータ(実データ)を用いて、コミュニティバスの運営企画者の 気持ちになり、コミュニティバスを走らせて儲かりそうなルートを作成。 1. 今回用いる3つのオープンデータ - ニューヨークのタクシーの走行データ ・ イリノイ大学ライブラリ 提供 ・ ニューヨーク市のタクシー・リムジン委員会 提供 参考URL: http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml https://databank.illinois.edu/datasets/IDB-9610843 - 気象データ Quality Controlled Local Climatological Data 参考URL:http://www.ncdc.noaa.gov/qclcd/QCLCD?prior=N - ニューヨークの主要な施設関連データ Yelp(Yelp, Inc.が運営するローカルビジネスレビューサイト) 参考URL: https://www.yelp.com/developers 2. 今回用いるOLAPツール Kyvos Insight (商用ベースですいません。オープンソースだとApache Kylinとかあります) 参考URL: http://www.kyvosinsights.com/ 3. 今回用いるBIツール Tableau (最近特に有名どころなので) 参考URL: http://www.tableau.com/ja-jp
13.
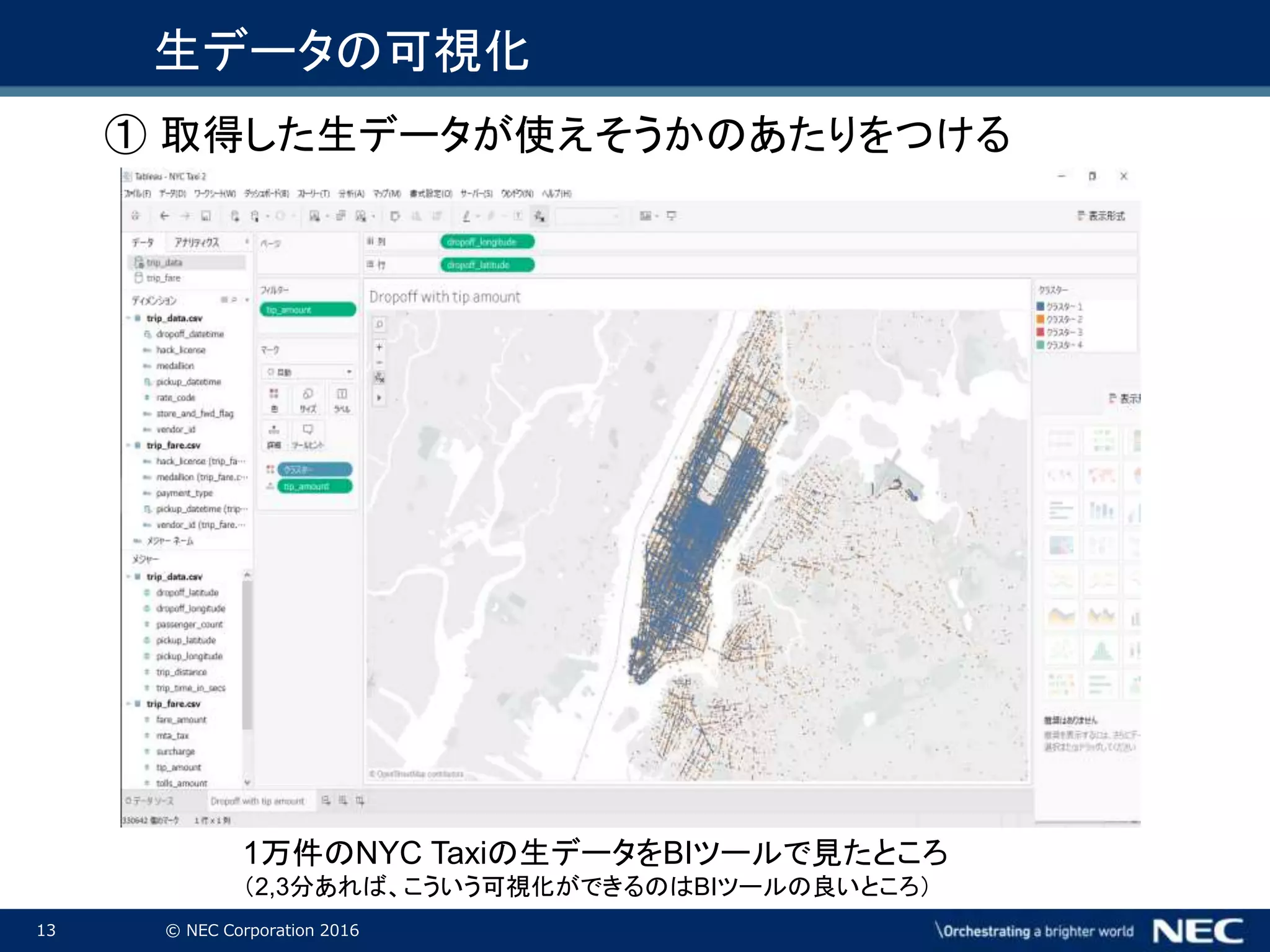
13 © NEC
Corporation 2016 1万件のNYC Taxiの生データをBIツールで見たところ (2,3分あれば、こういう可視化ができるのはBIツールの良いところ) 生データの可視化 ① 取得した生データが使えそうかのあたりをつける
14.
14 © NEC
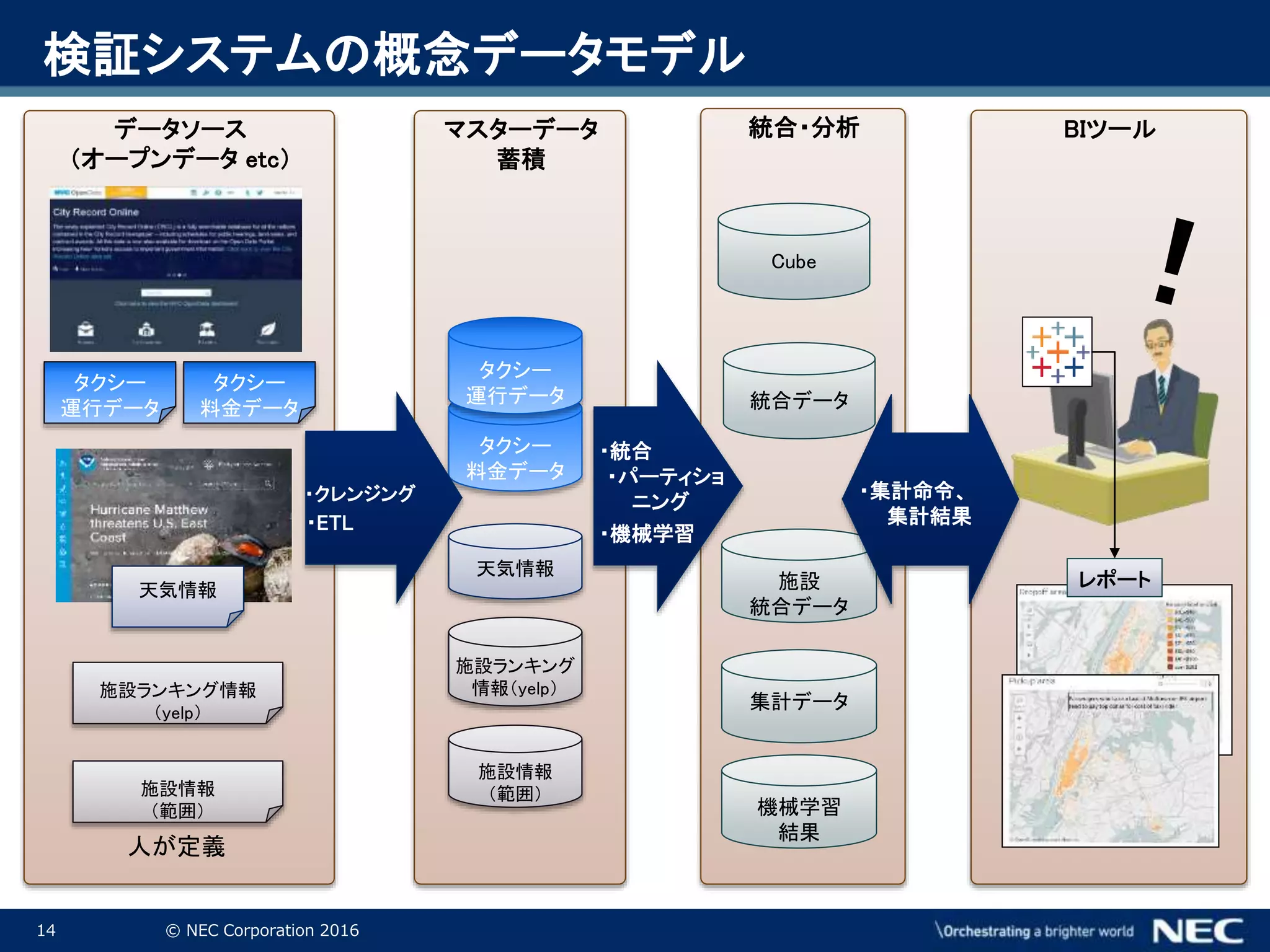
Corporation 2016 検証システムの概念データモデル データソース (オープンデータ etc) マスターデータ 蓄積 統合・分析 BIツール 天気情報 施設ランキング 情報(yelp) 施設情報 (範囲) タクシー 料金データ タクシー 運行データ タクシー 運行データ タクシー 料金データ 天気情報 施設ランキング情報 (yelp) 人が定義 施設 統合データ 統合データ ・クレンジング ・ETL ・統合 ・パーティショ ニング ・集計命令、 集計結果 施設情報 (範囲) レポート 集計データ 機械学習 結果 ・機械学習 Cube
15.
15 © NEC
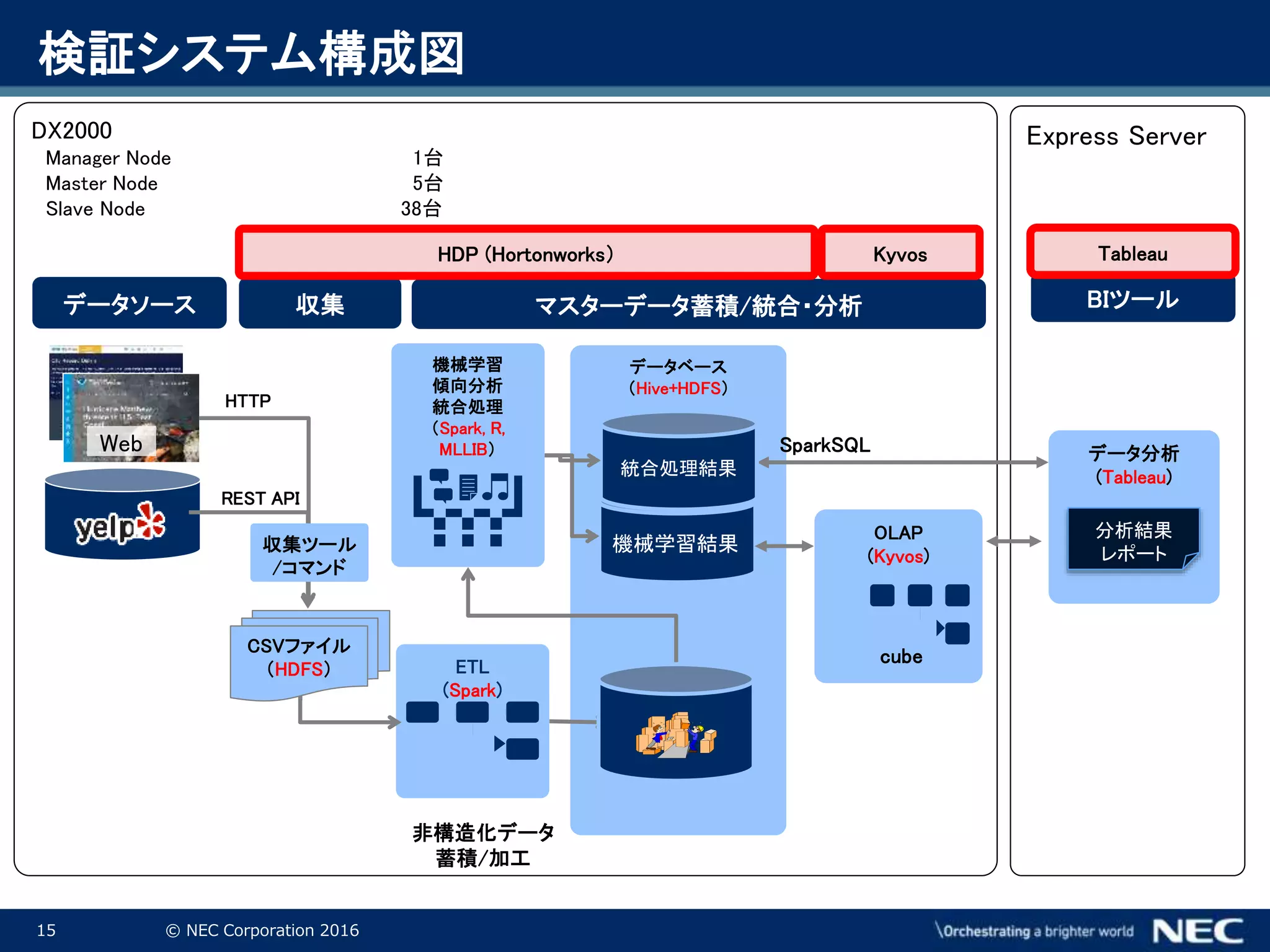
Corporation 2016 Express ServerDX2000 Manager Node 1台 Master Node 5台 Slave Node 38台 BIツール収集 ETL (Spark) マスターデータ蓄積/統合・分析 データベース (Hive+HDFS) HDP (Hortonworks) 機械学習 傾向分析 統合処理 (Spark, R, MLLIB) Tableau CSVファイル (HDFS) 非構造化データ 蓄積/加工 機械学習結果 OLAP (Kyvos) SparkSQL 統合処理結果 Kyvos cube データ分析 (Tableau) 分析結果 レポート データソース Web 収集ツール /コマンド REST API HTTP 検証システム構成図
16.
16 © NEC
Corporation 2016 1,395,244,966 レコード 施設ランキング情報 Yelp APIにて取得 |-- categories |-- deals | |-- (略) |-- display_phone |-- gift_certificates | |-- (略) |-- id |-- image_url |-- is_claimed |-- is_closed |-- location | |-- address | | |-- element | |-- city | |-- coordinate | | |-- latitude | | |-- longitude | |-- country_code | |-- cross_streets | |-- display_address | | |-- element | |-- geo_accuracy | |-- neighborhoods | | |-- element | |-- postal_code | |-- state_code |-- menu_date_updated |-- menu_provider |-- mobile_url |-- name |-- phone |-- rating |-- rating_img_url |-- rating_img_url_large |-- rating_img_url_small |-- review_count |-- reviews | |-- (略) |-- snippet_image_url |-- snippet_text |-- url 541 レコード 統合データ データソースと統合データ タクシー運行/料金データ https://databank.illinois.edu/datasets/ID B-9610843 (運行データ) medallion hack_license vendor_id rate_code store_and_fwd_flag pickup_datetime dropoff_datetime passenger_count trip_time_in_secs trip_distance pickup_longitude pickup_latitude dropoff_longitude dropoff_latitude (料金データ) medallion hack_license vendor_id pickup_datetime payment_type fare_amount surcharge mta_tax tip_amount tolls_amount total_amount タクシー運行&料金データ http://www.nyc.gov/html/tlc/html/about /trip_record_data.shtml vendor_id pickup_datetime dropoff_datetime passenger_count trip_distance pickup_longitude pickup_latitude rate_code store_and_fwd_flag dropoff_longitude dropoff_latitude payment_type fare_amount surcharge mta_tax tip_amount tolls_amount total_amount 1,395,244,966レ コード 380,633,912レコード 天気情報 http://www.ncdc.noaa.gov/orders/qclcd/ WBAN WMO CallSign ClimateDivisionCode ClimateDivisionStateCode ClimateDivisionStationCode Name State Location Latitude Longitude GroundHeight StationHeight Barometer TimeZone 319,393,646 レコード
17.
17 © NEC
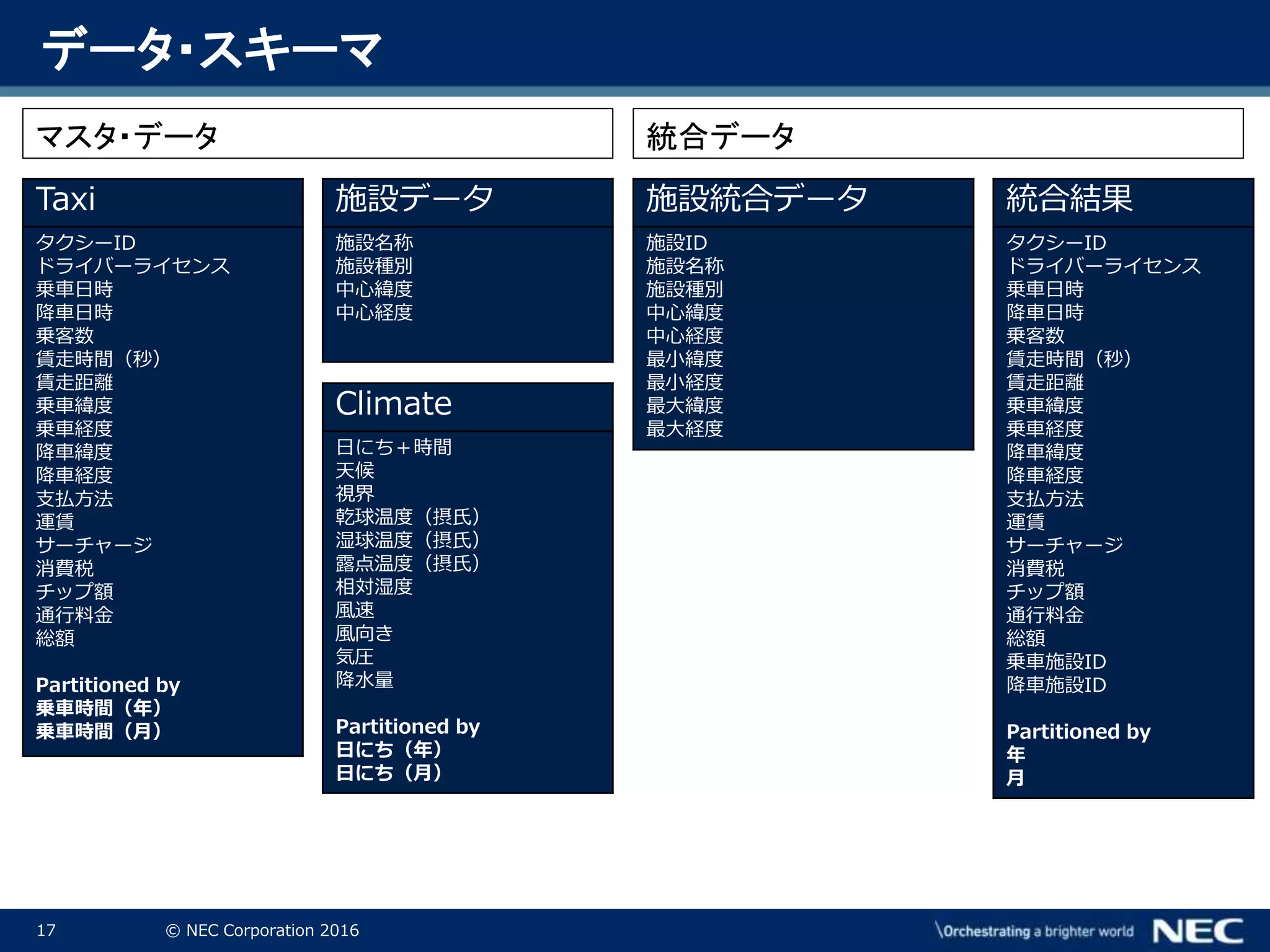
Corporation 2016 Taxi タクシーID ドライバーライセンス 乗車日時 降車日時 乗客数 賃走時間(秒) 賃走距離 乗車緯度 乗車経度 降車緯度 降車経度 支払方法 運賃 サーチャージ 消費税 チップ額 通行料金 総額 Partitioned by 乗車時間(年) 乗車時間(月) マスタ・データ 施設統合データ 施設ID 施設名称 施設種別 中心緯度 中心経度 最小緯度 最小経度 最大緯度 最大経度 統合結果 タクシーID ドライバーライセンス 乗車日時 降車日時 乗客数 賃走時間(秒) 賃走距離 乗車緯度 乗車経度 降車緯度 降車経度 支払方法 運賃 サーチャージ 消費税 チップ額 通行料金 総額 乗車施設ID 降車施設ID Partitioned by 年 月 施設データ 施設名称 施設種別 中心緯度 中心経度 統合データ データ・スキーマ Climate 日にち+時間 天候 視界 乾球温度(摂氏) 湿球温度(摂氏) 露点温度(摂氏) 相対湿度 風速 風向き 気圧 降水量 Partitioned by 日にち(年) 日にち(月)
18.
18 © NEC
Corporation 2016 アジェンダ 1. 今回の検証の概要 2. Hadoop/SparkからOLAPツールにデータを渡すための準備 3. MLlibで準備できたデータの傾向・特性を把握 4. OLAPツールを用いたBI接続の使用感 5. まとめ
19.
19 © NEC
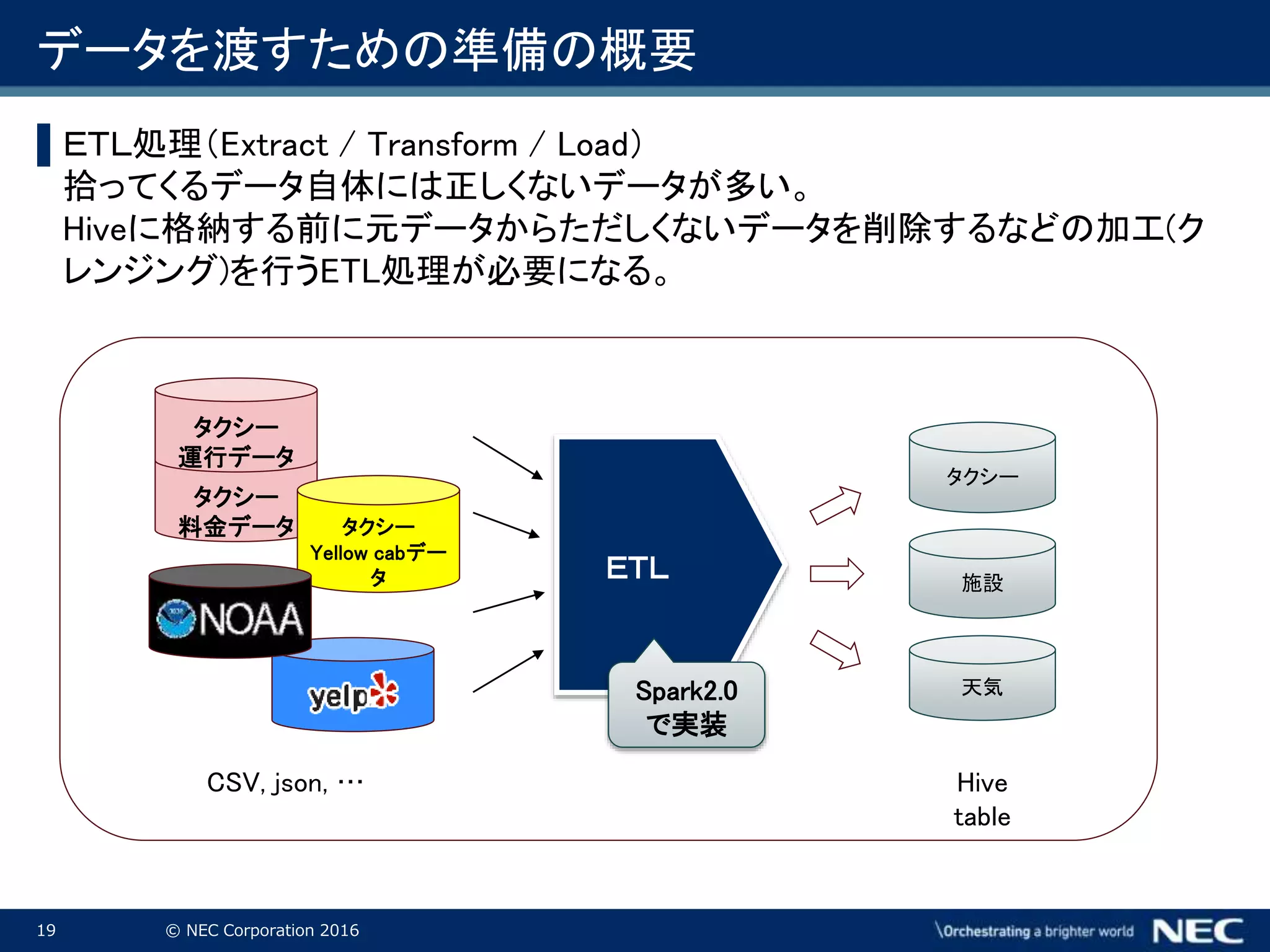
Corporation 2016 データを渡すための準備の概要 ▌ETL処理(Extract / Transform / Load) 拾ってくるデータ自体には正しくないデータが多い。 Hiveに格納する前に元データからただしくないデータを削除するなどの加工(ク レンジング)を行うETL処理が必要になる。 タクシー 料金データ タクシー Yellow cabデー タ タクシー 運行データ CSV, json, … ETL タクシー 天気 施設 Hive table Spark2.0 で実装
20.
20 © NEC
Corporation 2016 データを渡すための準備のポイント(1) medallion license pickup_datetime dropoff_datetime … 2010006241 2010023523 2010-01-07 12:52:00 2010-01-07 13:04:00 … 2010003044 2010012294 2010-01-16 12:39:00 2010-01-16 12:45:00 … 2010003667 2010024794 2010-01-20 19:15:00 2010-- 19:23:00 … 2010000073 2010017381 2010-01-22 17:55:00 2010-01-22 12:56:00 … dropoff_datetimeが 不正なため、このレ コードは排除 ▌クレンジング スキーマに合わないレコードの削除はsparkでファイル読み込み時に行う • 例 – 格納するスキーマを定義 DROPMALFORMEDモードを利用するとスキーマに合わないレコードを排除しつつ生データを読込むことができる val trip_df = spark.read.option("header", "true").option("mode", "DROPMALFORMED").schema(tripSchema).csv(“taxi_trip.csv”) val tripSchema = StructType(Seq( StructField(“medallion”, StringType, true), StructField(“license”, StringType, true), StructField(“pickup_datetime”, TimestampType, true), StructField(“dropoff_datetime”, TimestampType, true), : ) )
21.
21 © NEC
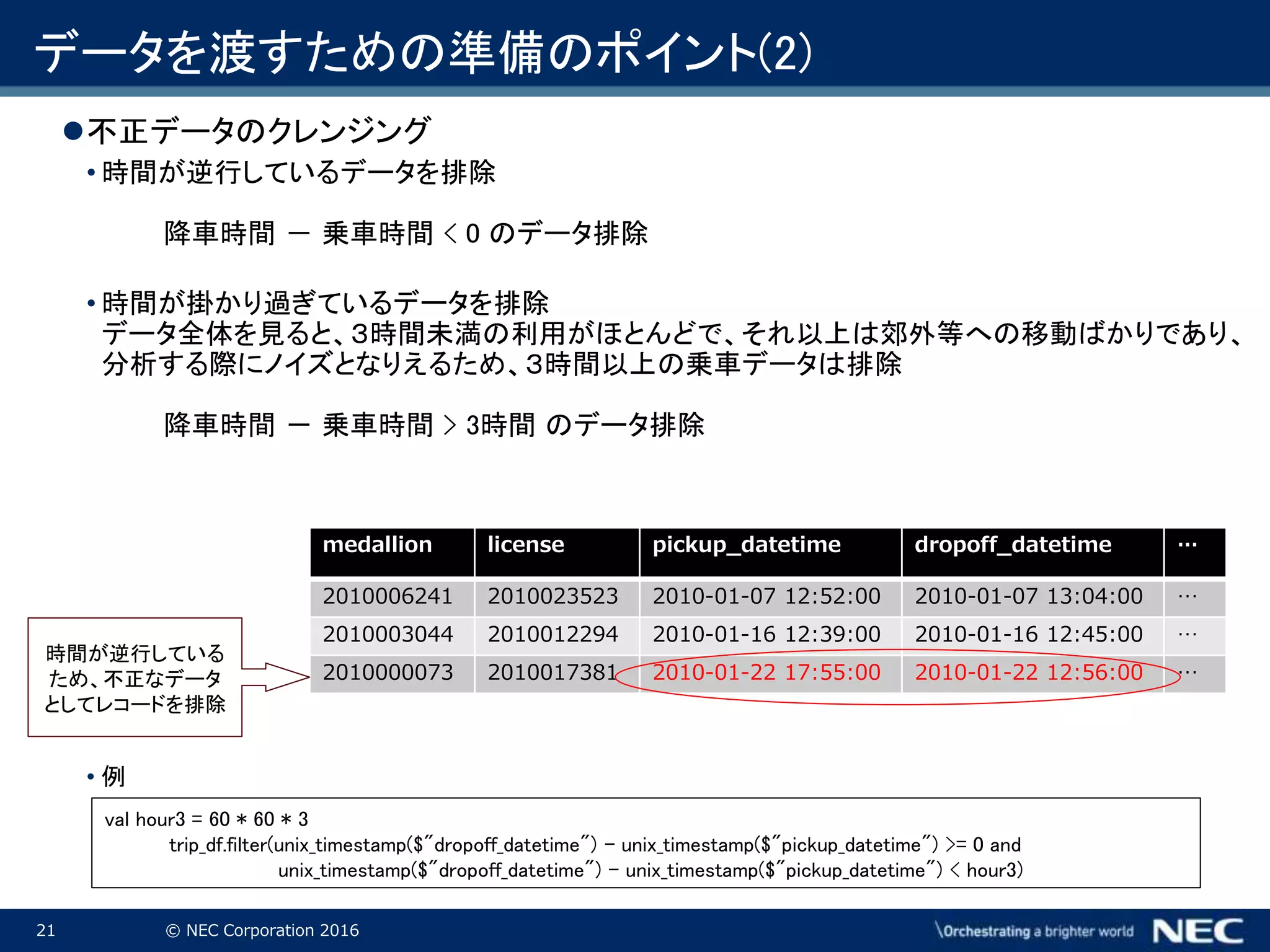
Corporation 2016 データを渡すための準備のポイント(2) 不正データのクレンジング • 時間が逆行しているデータを排除 降車時間 - 乗車時間 < 0 のデータ排除 • 時間が掛かり過ぎているデータを排除 データ全体を見ると、3時間未満の利用がほとんどで、それ以上は郊外等への移動ばかりであり、 分析する際にノイズとなりえるため、3時間以上の乗車データは排除 降車時間 - 乗車時間 > 3時間 のデータ排除 • 例 medallion license pickup_datetime dropoff_datetime … 2010006241 2010023523 2010-01-07 12:52:00 2010-01-07 13:04:00 … 2010003044 2010012294 2010-01-16 12:39:00 2010-01-16 12:45:00 … 2010000073 2010017381 2010-01-22 17:55:00 2010-01-22 12:56:00 … 時間が逆行している ため、不正なデータ としてレコードを排除 val hour3 = 60 * 60 * 3 trip_df.filter(unix_timestamp($"dropoff_datetime") - unix_timestamp($"pickup_datetime") >= 0 and unix_timestamp($"dropoff_datetime") - unix_timestamp($"pickup_datetime") < hour3)
22.
22 © NEC
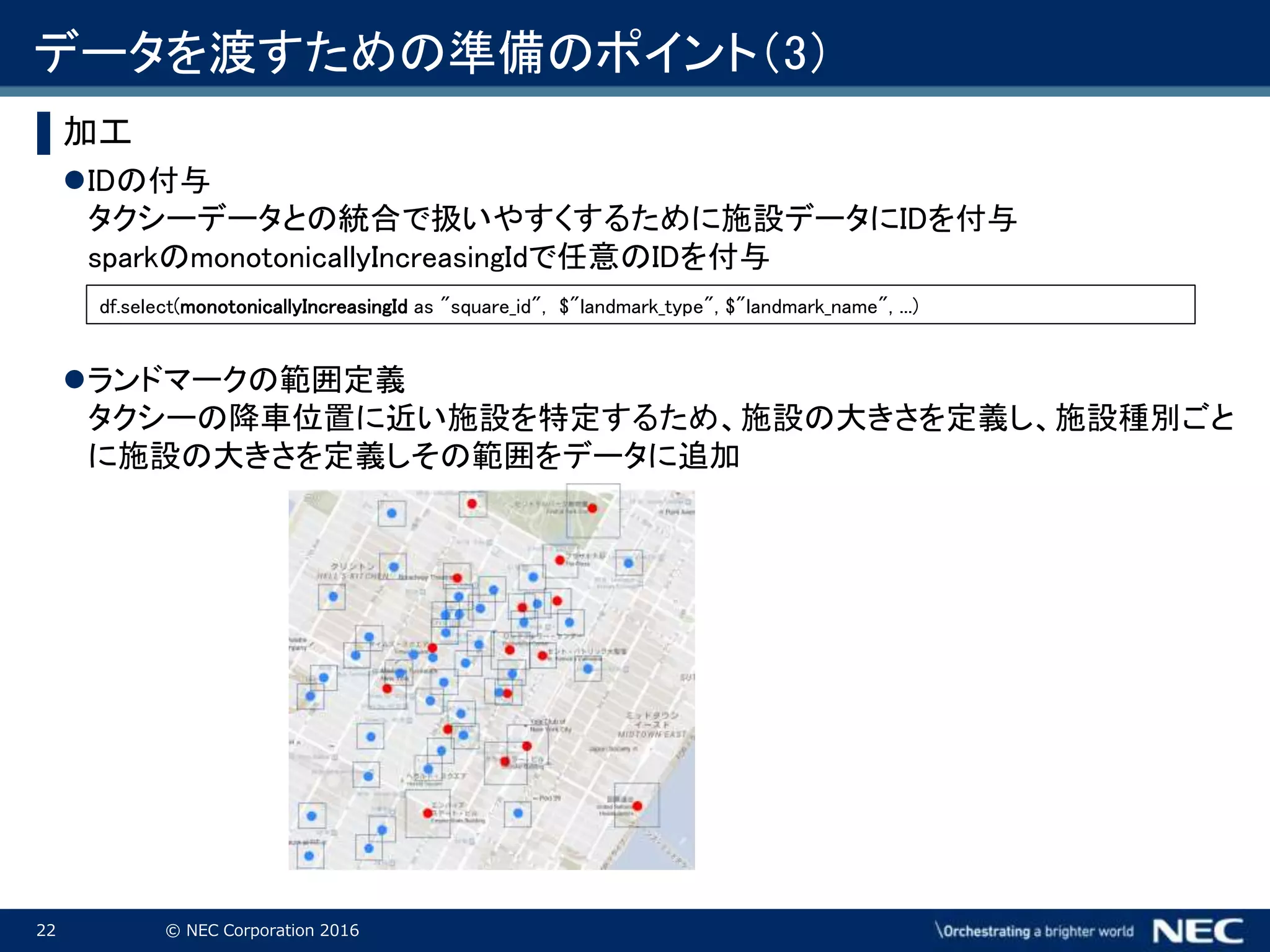
Corporation 2016 ▌加工 IDの付与 タクシーデータとの統合で扱いやすくするために施設データにIDを付与 sparkのmonotonicallyIncreasingIdで任意のIDを付与 ランドマークの範囲定義 タクシーの降車位置に近い施設を特定するため、施設の大きさを定義し、施設種別ごと に施設の大きさを定義しその範囲をデータに追加 df.select(monotonicallyIncreasingId as "square_id", $"landmark_type", $"landmark_name", ...) データを渡すための準備のポイント(3)
23.
23 © NEC
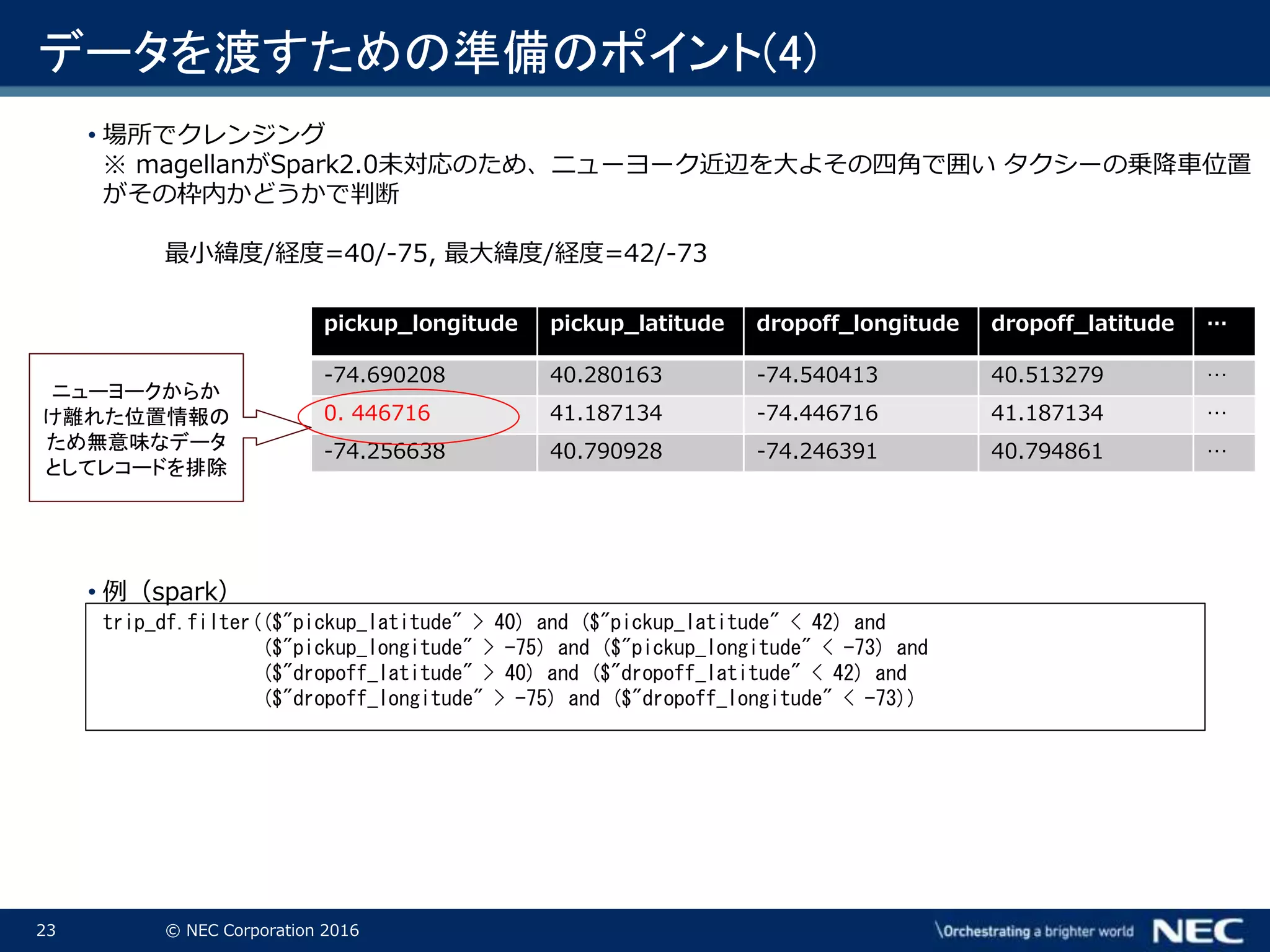
Corporation 2016 データを渡すための準備のポイント(4) • 場所でクレンジング ※ magellanがSpark2.0未対応のため、ニューヨーク近辺を大よその四角で囲い タクシーの乗降車位置 がその枠内かどうかで判断 最小緯度/経度=40/-75, 最大緯度/経度=42/-73 • 例(spark) trip_df.filter(($"pickup_latitude" > 40) and ($"pickup_latitude" < 42) and ($"pickup_longitude" > -75) and ($"pickup_longitude" < -73) and ($"dropoff_latitude" > 40) and ($"dropoff_latitude" < 42) and ($"dropoff_longitude" > -75) and ($"dropoff_longitude" < -73)) pickup_longitude pickup_latitude dropoff_longitude dropoff_latitude … -74.690208 40.280163 -74.540413 40.513279 … 0. 446716 41.187134 -74.446716 41.187134 … -74.256638 40.790928 -74.246391 40.794861 … ニューヨークからか け離れた位置情報の ため無意味なデータ としてレコードを排除
24.
24 © NEC
Corporation 2016 ▌テーブル保存 利用時の効率を上げるためのポイント • ファイルフォーマット – Hiveでは、ParquetよりORCの方が効率が良いため、ORCフォーマットで保存 • パーティション – 検索効率を上げるためにもパーティションは必須 – 今回はそこまで膨大なデータ量でもないため、年&月くらいでパーティショニング • 位置情報でソート – 年月でフィルターした後は、位置情報でデータを検索することが想定されるため、緯度/経度でソーティング パーティションは、あまり細かく分けすぎると逆に性能劣化につながってしまうので注意が必要 Tips Spark DataFrameからパーティショニングしてHiveテーブルに保存することは出来ないので、 一度、一次テーブルに保存した後、HiveQLでテーブル生成&データロードを行った Tips データを渡すための準備(保存方法)
25.
25 © NEC
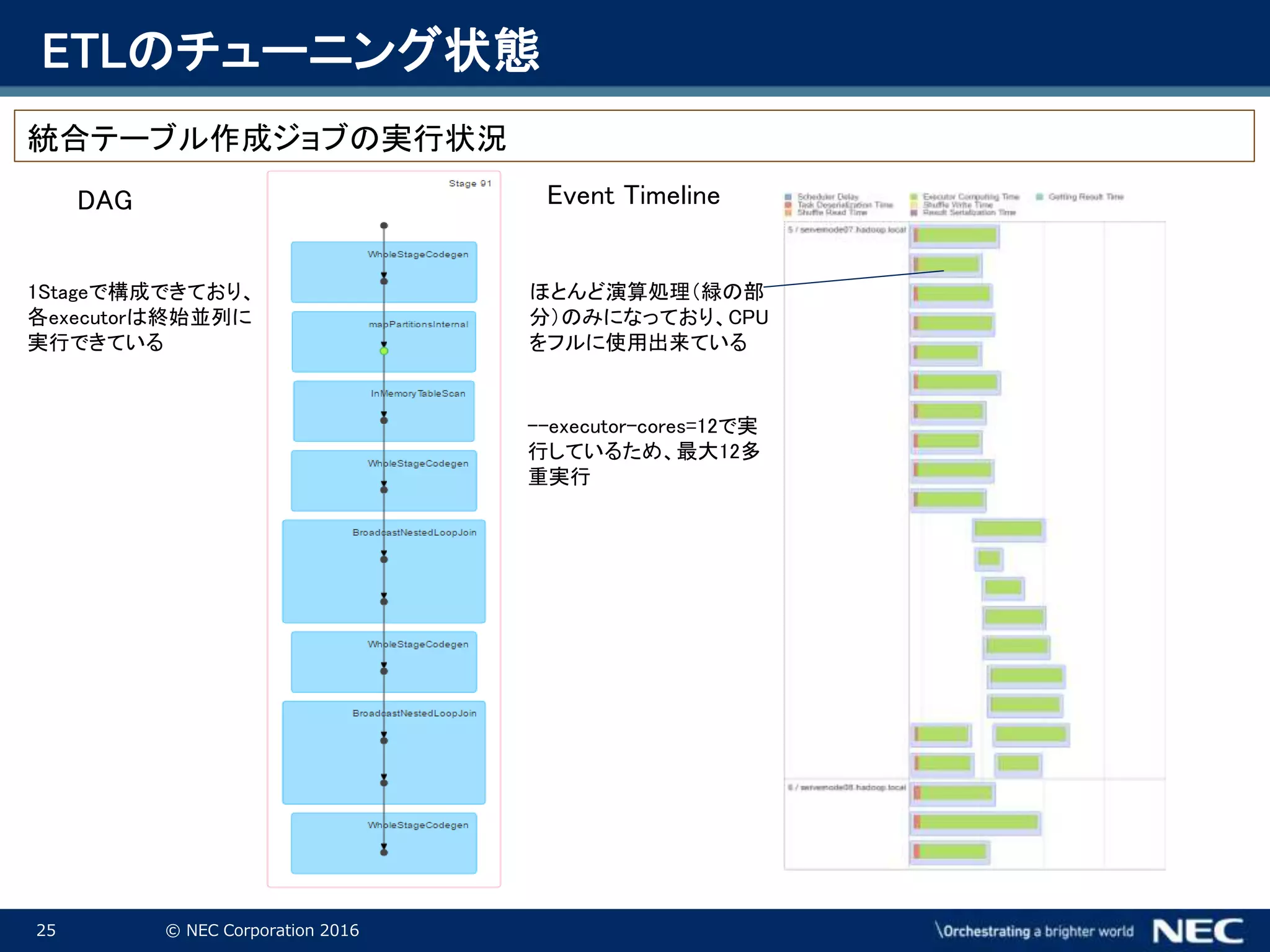
Corporation 2016 DAG Event Timeline 1Stageで構成できており、 各executorは終始並列に 実行できている ほとんど演算処理(緑の部 分)のみになっており、CPU をフルに使用出来ている --executor-cores=12で実 行しているため、最大12多 重実行 統合テーブル作成ジョブの実行状況 ETLのチューニング状態
26.
26 © NEC
Corporation 2016 アジェンダ 1. 今回の検証の概要 2. Hadoop/SparkからOLAPツールにデータを渡すための準備 3. MLlibで準備できたデータの傾向・特性を把握 4. OLAPツールを用いたBI接続の使用感 5. まとめ
27.
27 © NEC
Corporation 2016 データの傾向・特性の把握 ▌データ集計に関する課題 BIツールを適用する前のデータ処理において、データ 処理、結果確認を何度も繰り返す場合がある。 例えば、今回のシステムではこの機械学習など。 Spark-shellなどインタラクティブなツールは存 在するが、結果が分かりにくい!??? ③ 分析・集計してみたいデータの傾向・特性を把握
28.
28 © NEC
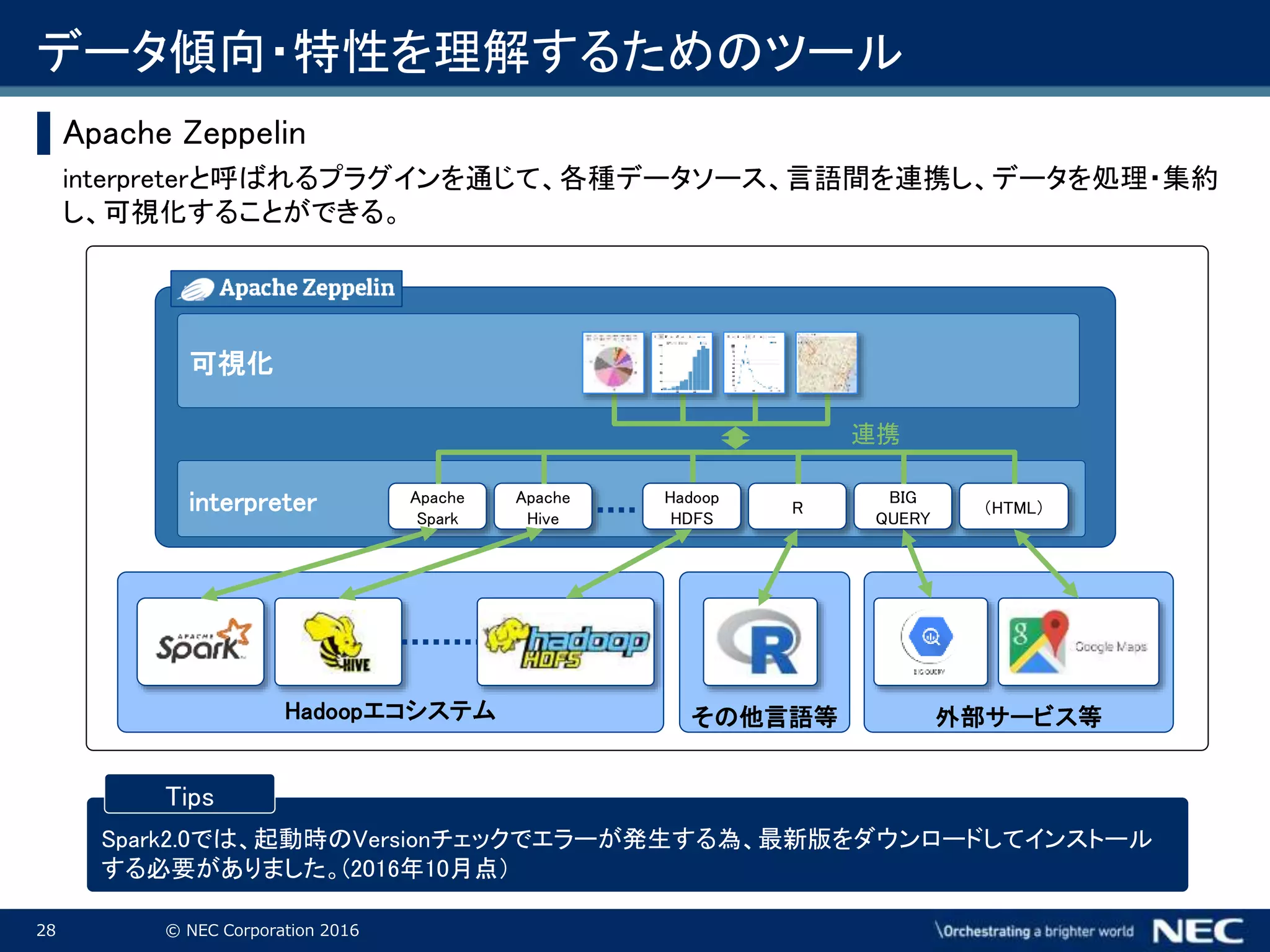
Corporation 2016 Hadoopエコシステム データ傾向・特性を理解するためのツール ▌Apache Zeppelin interpreterと呼ばれるプラグインを通じて、各種データソース、言語間を連携し、データを処理・集約 し、可視化することができる。 Spark2.0では、起動時のVersionチェックでエラーが発生する為、最新版をダウンロードしてインストール する必要がありました。(2016年10月点) Tips Apache Spark Apache Hive Apache Hive interpreter Apache Spark Apache Hive Hadoop HDFS R 可視化 連携 その他言語等 Apache Hive 外部サービス等 Apache Hive BIG QUERY Apache Hive (HTML)
29.
29 © NEC
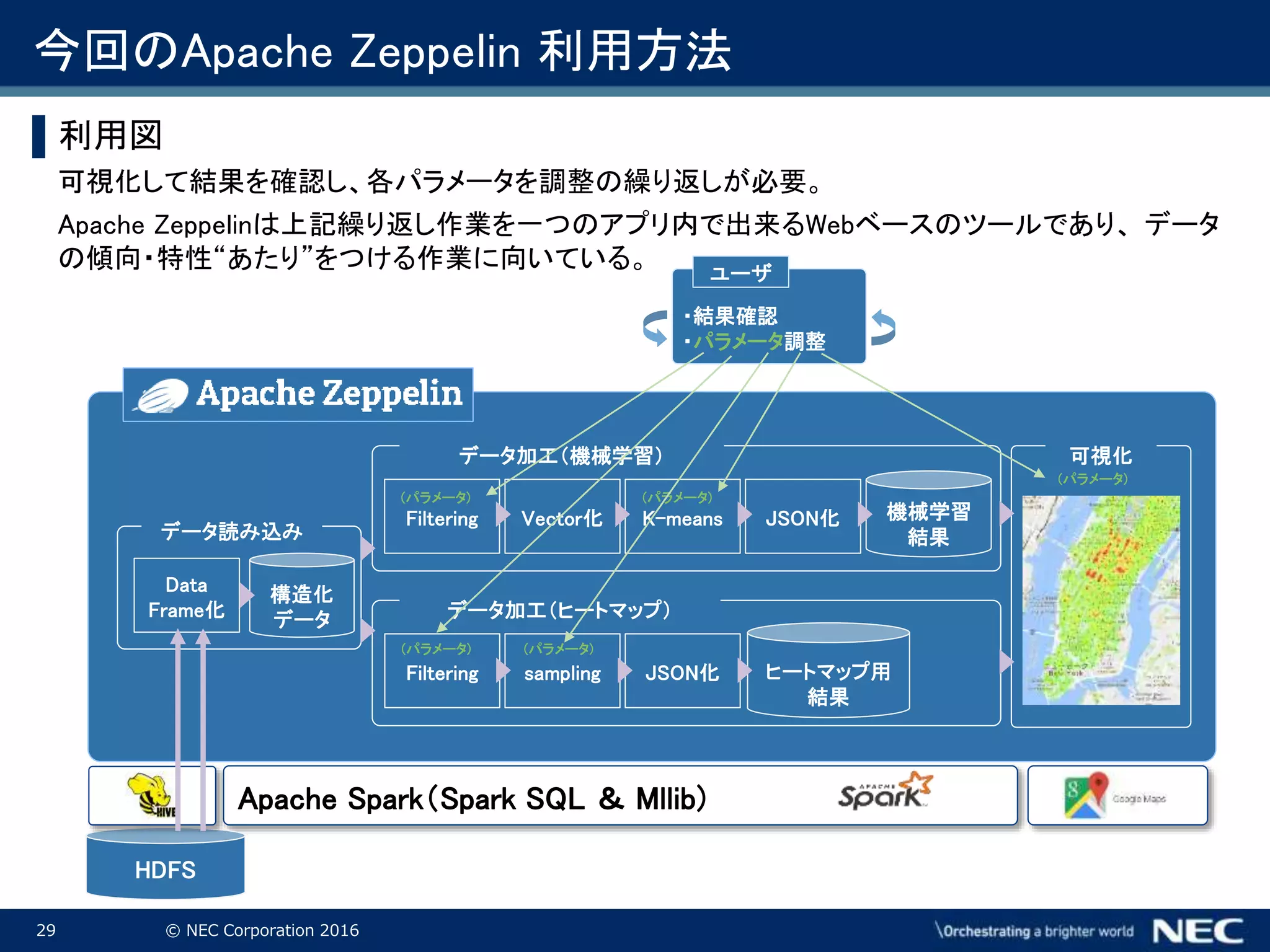
Corporation 2016 今回のApache Zeppelin 利用方法 ▌利用図 可視化して結果を確認し、各パラメータを調整の繰り返しが必要。 Apache Zeppelinは上記繰り返し作業を一つのアプリ内で出来るWebベースのツールであり、 データ の傾向・特性“あたり”をつける作業に向いている。 Apache Spark(Spark SQL & Mllib) HDFS データ読み込み Data Frame化 構造化 データ データ加工(機械学習) Filtering Vector化 K-means 機械学習 結果 データ加工(ヒートマップ) Filtering ヒートマップ用 結果 sampling JSON化 JSON化 可視化 (パラメータ) (パラメータ) (パラメータ)(パラメータ) (パラメータ) ユーザ ・結果確認 ・パラメータ調整 Apache Hive
30.
30 © NEC
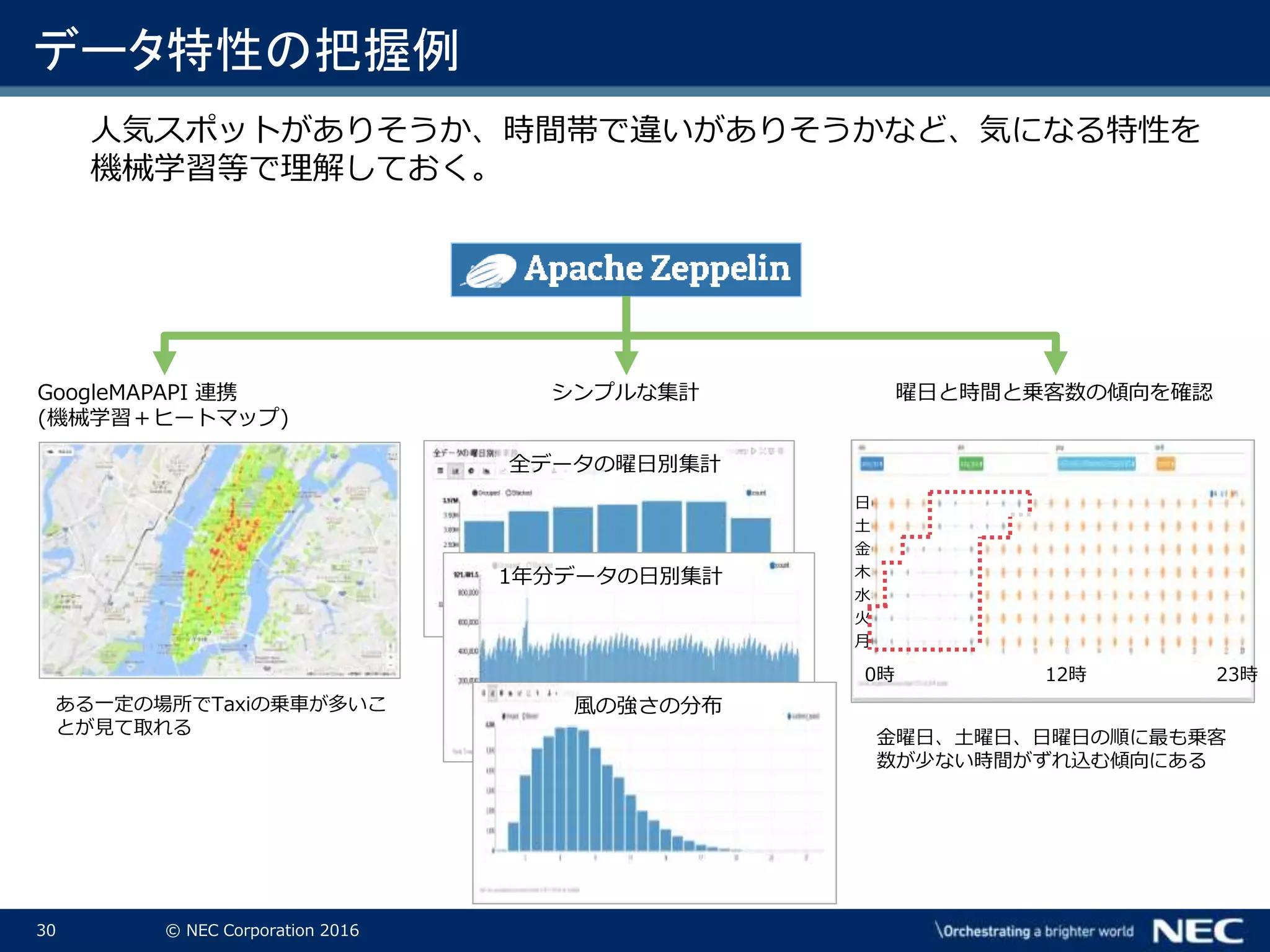
Corporation 2016 データ特性の把握例 ある一定の場所でTaxiの乗車が多いこ とが見て取れる 人気スポットがありそうか、時間帯で違いがありそうかなど、気になる特性を 機械学習等で理解しておく。 GoogleMAPAPI 連携 (機械学習+ヒートマップ) 曜日と時間と乗客数の傾向を確認 金曜日、土曜日、日曜日の順に最も乗客 数が少ない時間がずれ込む傾向にある 月 火 水 木 金 土 日 0時 12時 23時 全データの曜日別集計 1年分データの日別集計 シンプルな集計 風の強さの分布
31.
31 © NEC
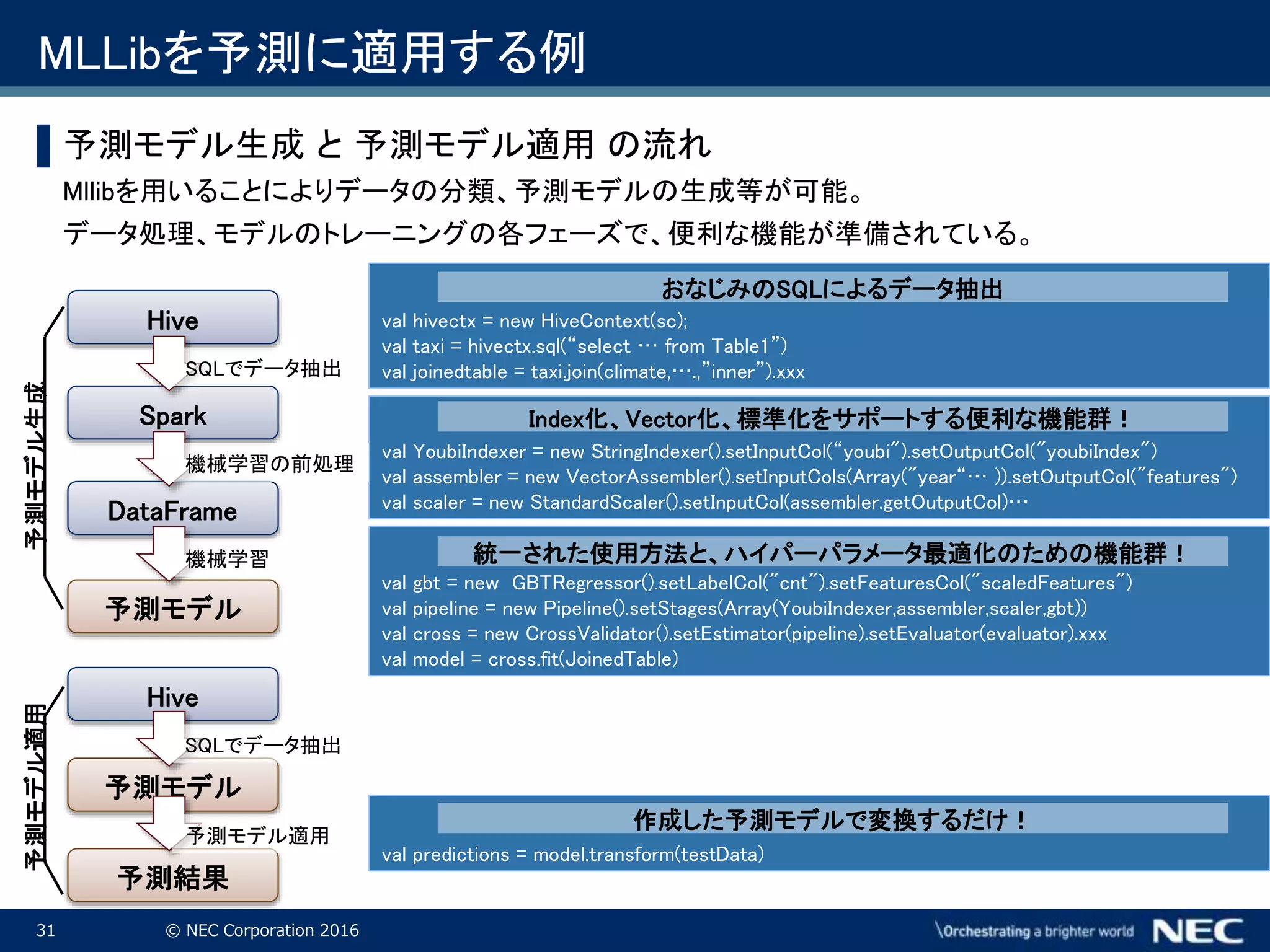
Corporation 2016 MLLibを予測に適用する例 ▌予測モデル生成 と 予測モデル適用 の流れ Mllibを用いることによりデータの分類、予測モデルの生成等が可能。 データ処理、モデルのトレーニングの各フェーズで、便利な機能が準備されている。 Hive Spark 予測モデル val hivectx = new HiveContext(sc); val taxi = hivectx.sql(“select … from Table1”) val joinedtable = taxi.join(climate,….,”inner”).xxx DataFrame val YoubiIndexer = new StringIndexer().setInputCol(“youbi").setOutputCol("youbiIndex") val assembler = new VectorAssembler().setInputCols(Array("year“… )).setOutputCol("features") val scaler = new StandardScaler().setInputCol(assembler.getOutputCol)… val gbt = new GBTRegressor().setLabelCol("cnt").setFeaturesCol("scaledFeatures") val pipeline = new Pipeline().setStages(Array(YoubiIndexer,assembler,scaler,gbt)) val cross = new CrossValidator().setEstimator(pipeline).setEvaluator(evaluator).xxx val model = cross.fit(JoinedTable) Index化、Vector化、標準化をサポートする便利な機能群! 統一された使用方法と、ハイパーパラメータ最適化のための機能群! おなじみのSQLによるデータ抽出 予測モデル Hive 予測結果 val predictions = model.transform(testData) 作成した予測モデルで変換するだけ! 予測モデル生成予測モデル適用 SQLでデータ抽出 機械学習の前処理 機械学習 SQLでデータ抽出 予測モデル適用
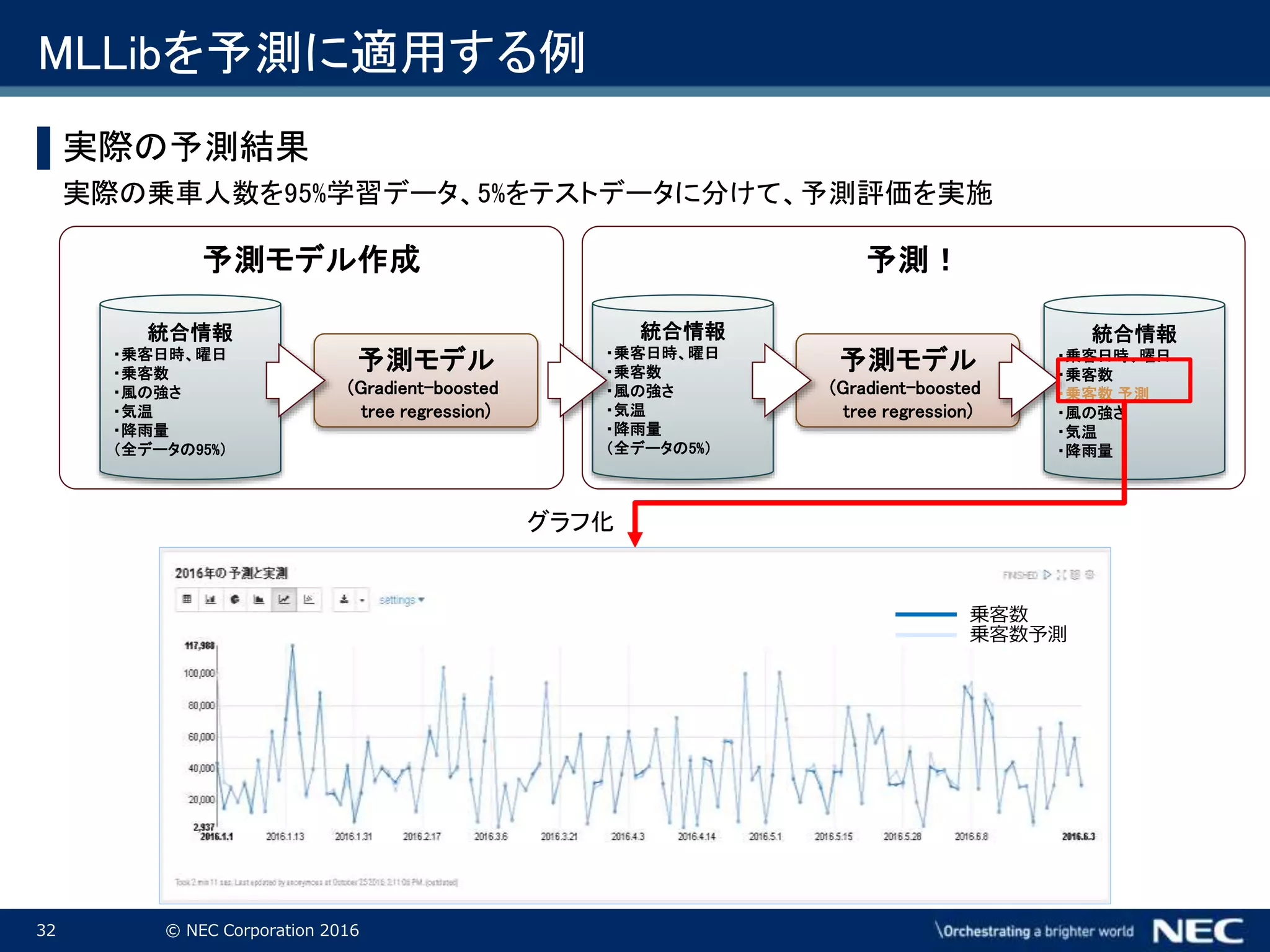
32.
32 © NEC
Corporation 2016 予測モデル作成 予測! MLLibを予測に適用する例 ▌実際の予測結果 実際の乗車人数を95%学習データ、5%をテストデータに分けて、予測評価を実施 予測モデル (Gradient-boosted tree regression) 統合情報 ・乗客日時、曜日 ・乗客数 ・風の強さ ・気温 ・降雨量 (全データの95%) 予測モデル (Gradient-boosted tree regression) 統合情報 ・乗客日時、曜日 ・乗客数 ・風の強さ ・気温 ・降雨量 (全データの5%) 統合情報 ・乗客日時、曜日 ・乗客数 ・乗客数 予測 ・風の強さ ・気温 ・降雨量 グラフ化 乗客数 乗客数予測
33.
33 © NEC
Corporation 2016 アジェンダ 1. 今回の検証の概要 2. Hadoop/SparkからOLAPツールにデータを渡すための準備 3. MLlibで準備できたデータの傾向・特性を把握 4. OLAPツールを用いたBI接続の使用感 5. まとめ
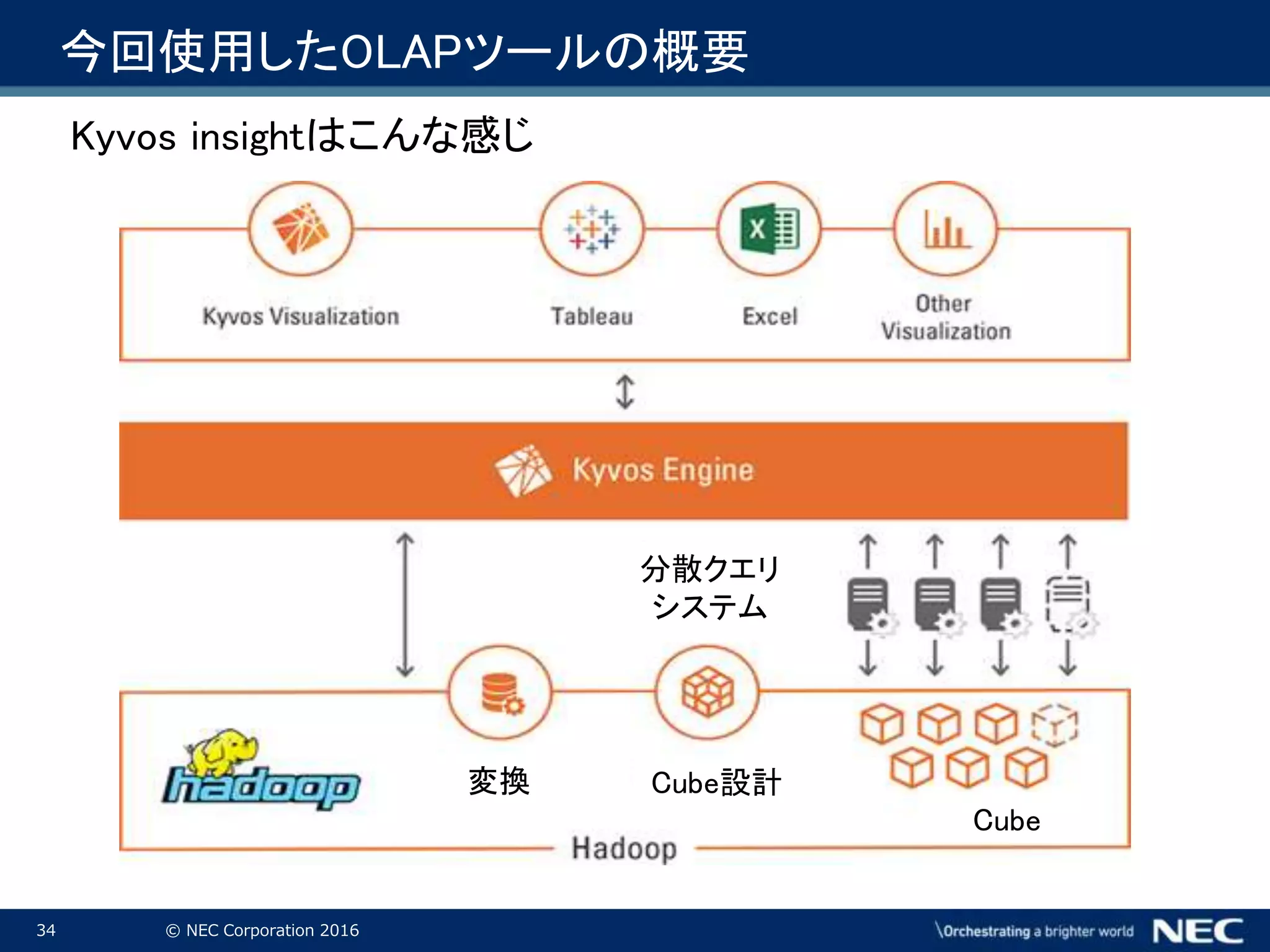
34.
34 © NEC
Corporation 2016 Kyvos insightはこんな感じ 今回使用したOLAPツールの概要 分散クエリ システム 変換 Cube設計 Cube
35.
35 © NEC
Corporation 2016 Kyvosの特徴 ・大規模データでも処理が可能 ・HadoopとBI間の遅延を改善 ・エンタープライズレベルのセキュリティを実装可能 ・特性 - ノンプログラミングでデータを加工しCubeを構築可能 - Hadoop上にCubeを構築するため、データ移動のオーバーラップが生じない - XMLA/MDX準拠のBIツールとの連携が可能 Tableau, Excel, Tibco Spotfire, SAP BO等
36.
36 © NEC
Corporation 2016 今回作成したCube例 2014年~2016年のデータのCube例 ディメンジョンとカーディナリティの 列のカウント数: 372,990,174 Cube前のファイルサイズ: 57.39 GB Cubeのサイズ: 380.6 GB Cubeの構築に要した時間: 4時間45分 利点: ・BIからCubeへのアクセスがレスポン スは早い (ほとんどのBIからのクエリは5秒以内でレ スポンスを返せる) 欠点: ・Cubeのサイズはかなり大きい ディメンジョンやカーディナリティ等による ・大規模データのCube構築には時間 がかかる 実際に使う場合は、初回に大規模な データをCubeし、あとはインクリメンタルに 追加を検討
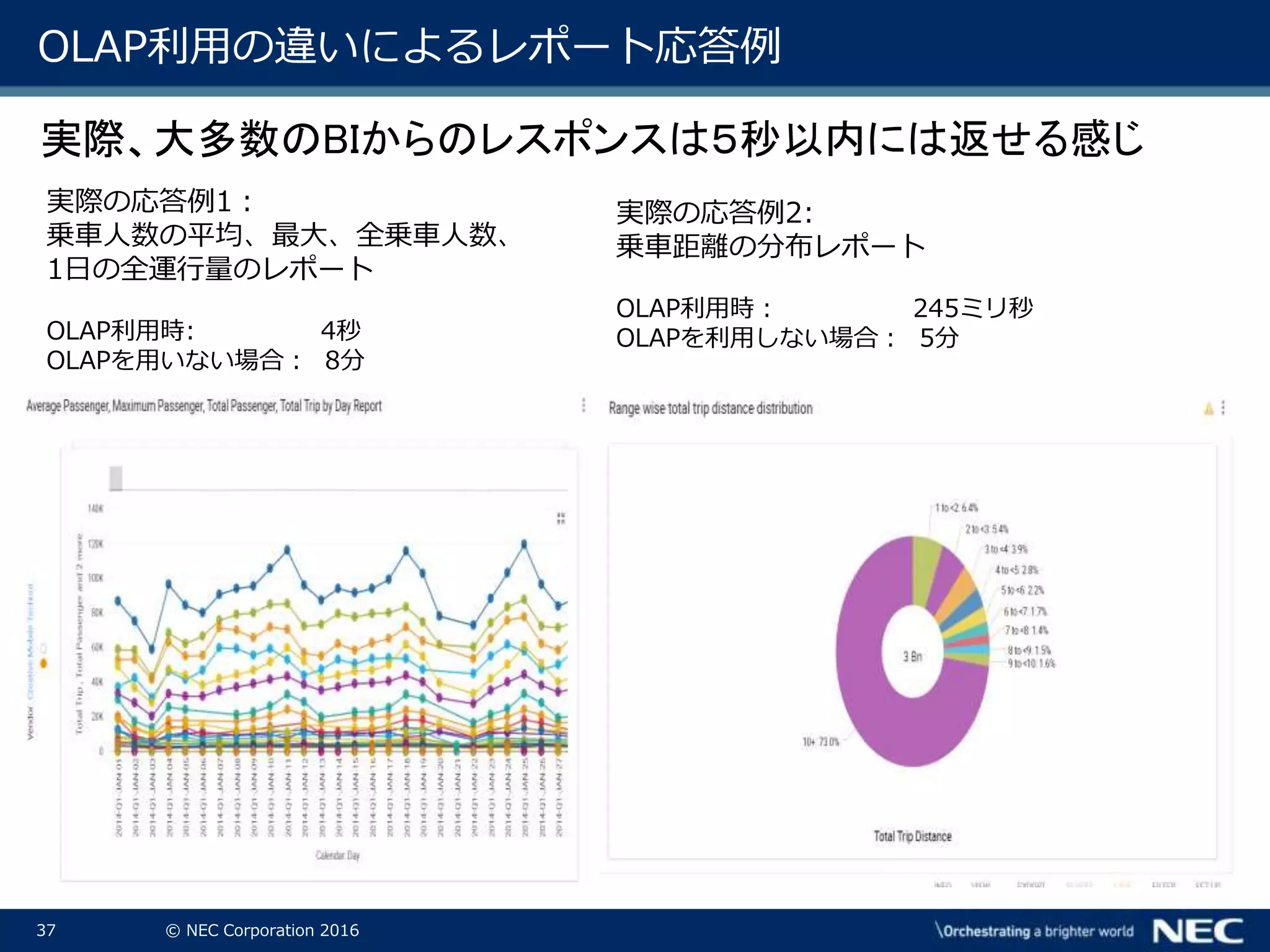
37.
37 © NEC
Corporation 2016 OLAP利用の違いによるレポート応答例 実際の応答例1: 乗車人数の平均、最大、全乗車人数、 1日の全運行量のレポート OLAP利用時: 4秒 OLAPを用いない場合: 8分 実際の応答例2: 乗車距離の分布レポート OLAP利用時: 245ミリ秒 OLAPを利用しない場合: 5分 実際、大多数のBIからのレスポンスは5秒以内には返せる感じ
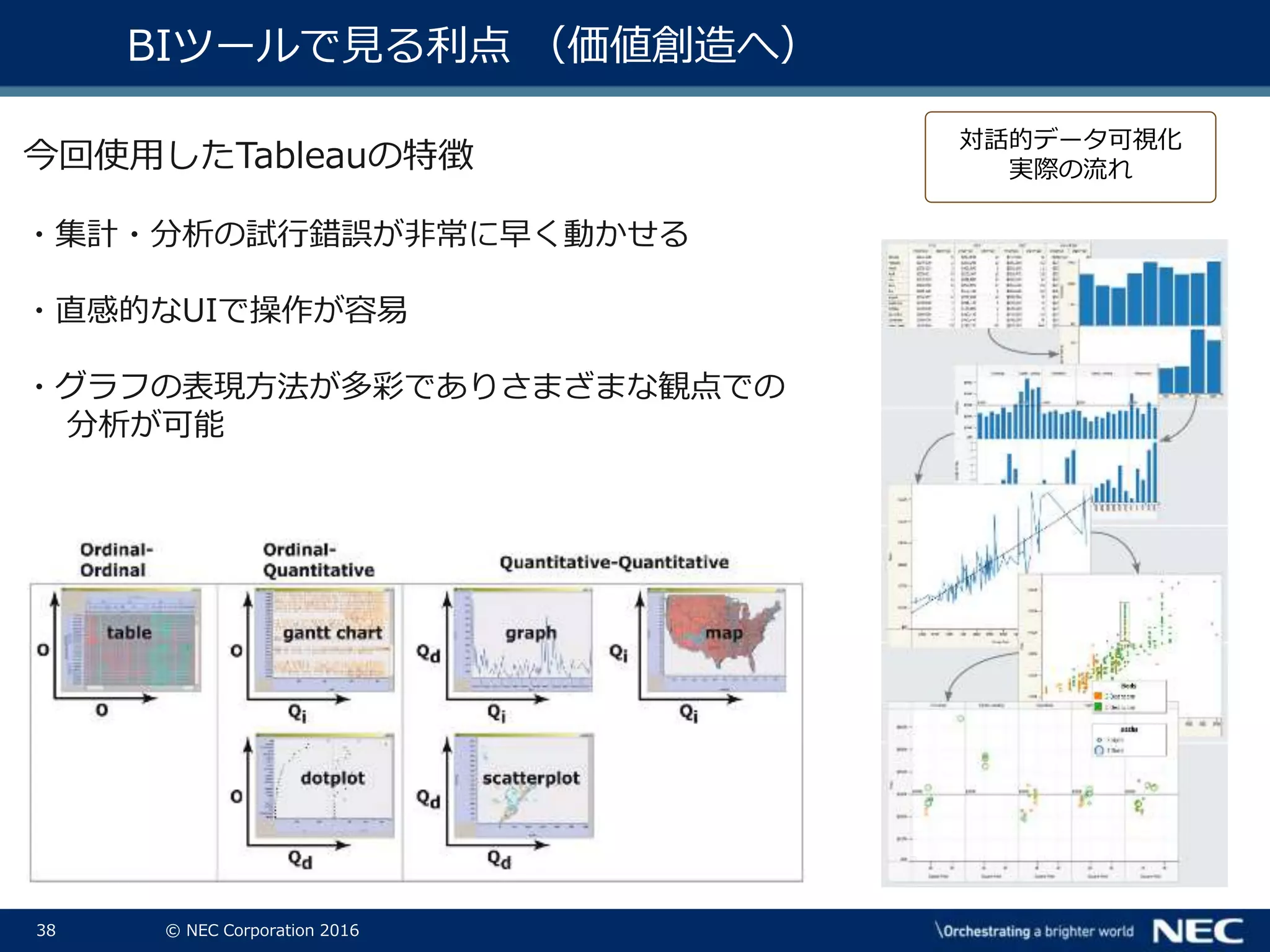
38.
38 © NEC
Corporation 2016 BIツールで見る利点 (価値創造へ) 今回使用したTableauの特徴 ・集計・分析の試行錯誤が非常に早く動かせる ・直感的なUIで操作が容易 ・グラフの表現方法が多彩でありさまざまな観点での 分析が可能 対話的データ可視化 実際の流れ
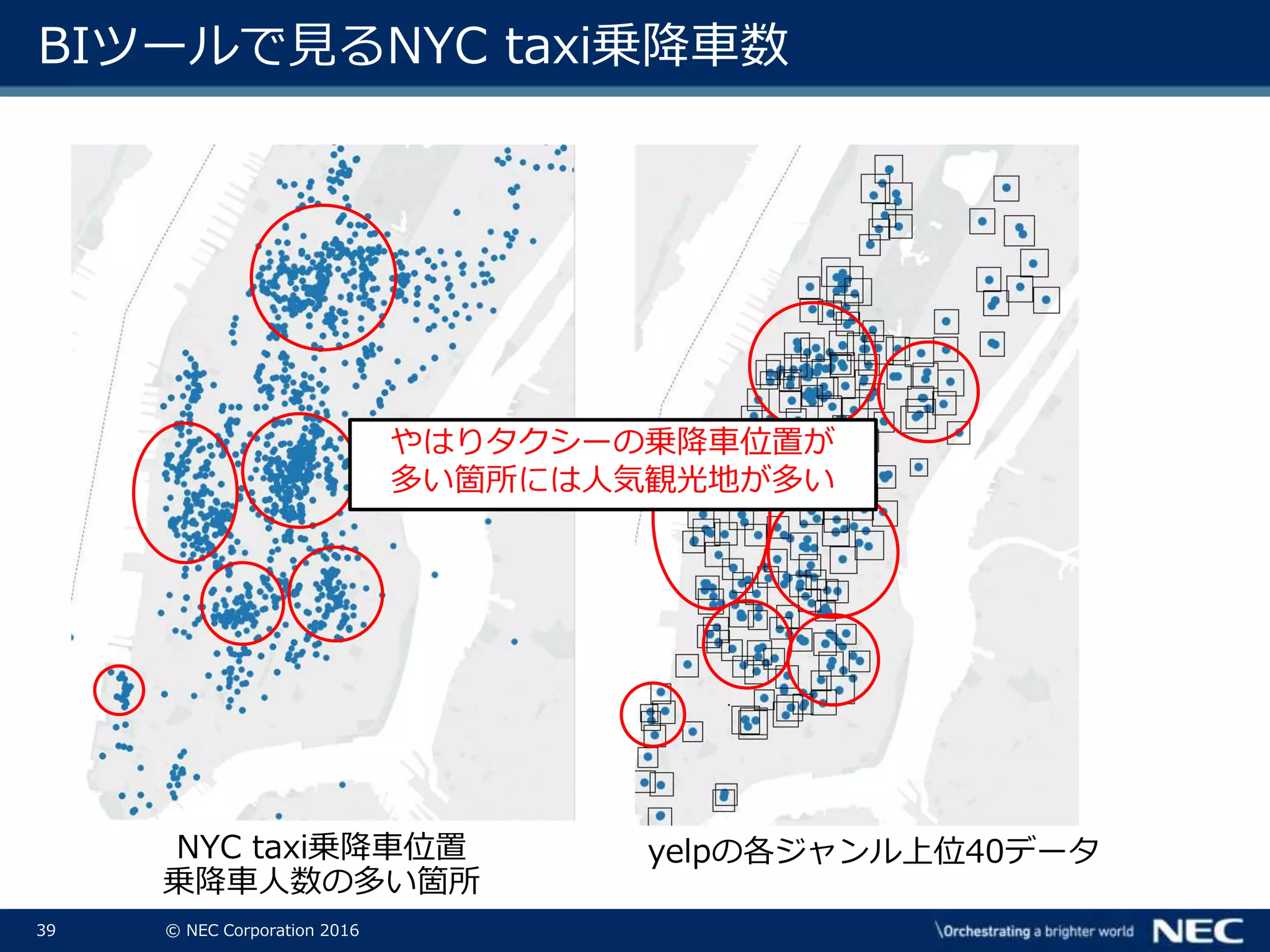
39.
39 © NEC
Corporation 2016 BIツールで見るNYC taxi乗降車数 NYC taxi乗降車位置 乗降車人数の多い箇所 yelpの各ジャンル上位40データ やはりタクシーの乗降車位置が 多い箇所には人気観光地が多い
40.
40 © NEC
Corporation 2016 NYC taxiから見たバスルート探索 :タイムズスクエアなど観光地 :公園や緑地など :博物館や記念館,美術館など :観光地や人気レストラン このように、ドメイン知識のある 人の知見が加わることでバス ルート探索への応用といった ソリューションへと役立てること ができる。 分析のキーポイント 人気スポット別の集計、乗降者数別の集計、時間帯による差など さまざまな視点でルートを決定
41.
41 © NEC
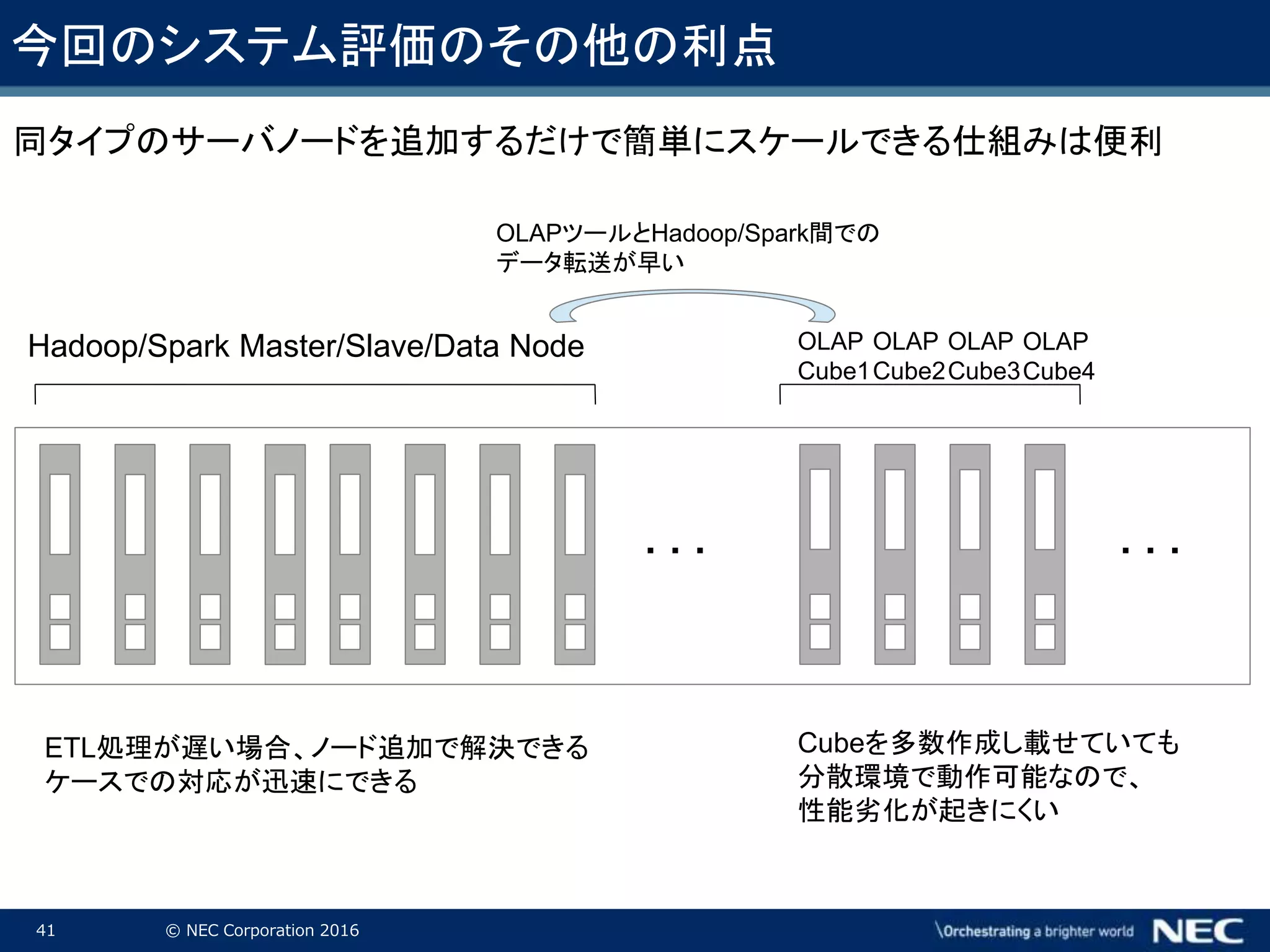
Corporation 2016 今回のシステム評価のその他の利点 OLAPツールとHadoop/Spark間での データ転送が早い OLAP Cube1 OLAP Cube2 OLAP Cube3 OLAP Cube4 Cubeを多数作成し載せていても 分散環境で動作可能なので、 性能劣化が起きにくい Hadoop/Spark Master/Slave/Data Node ETL処理が遅い場合、ノード追加で解決できる ケースでの対応が迅速にできる 同タイプのサーバノードを追加するだけで簡単にスケールできる仕組みは便利 ・ ・ ・・ ・ ・
42.
42 © NEC
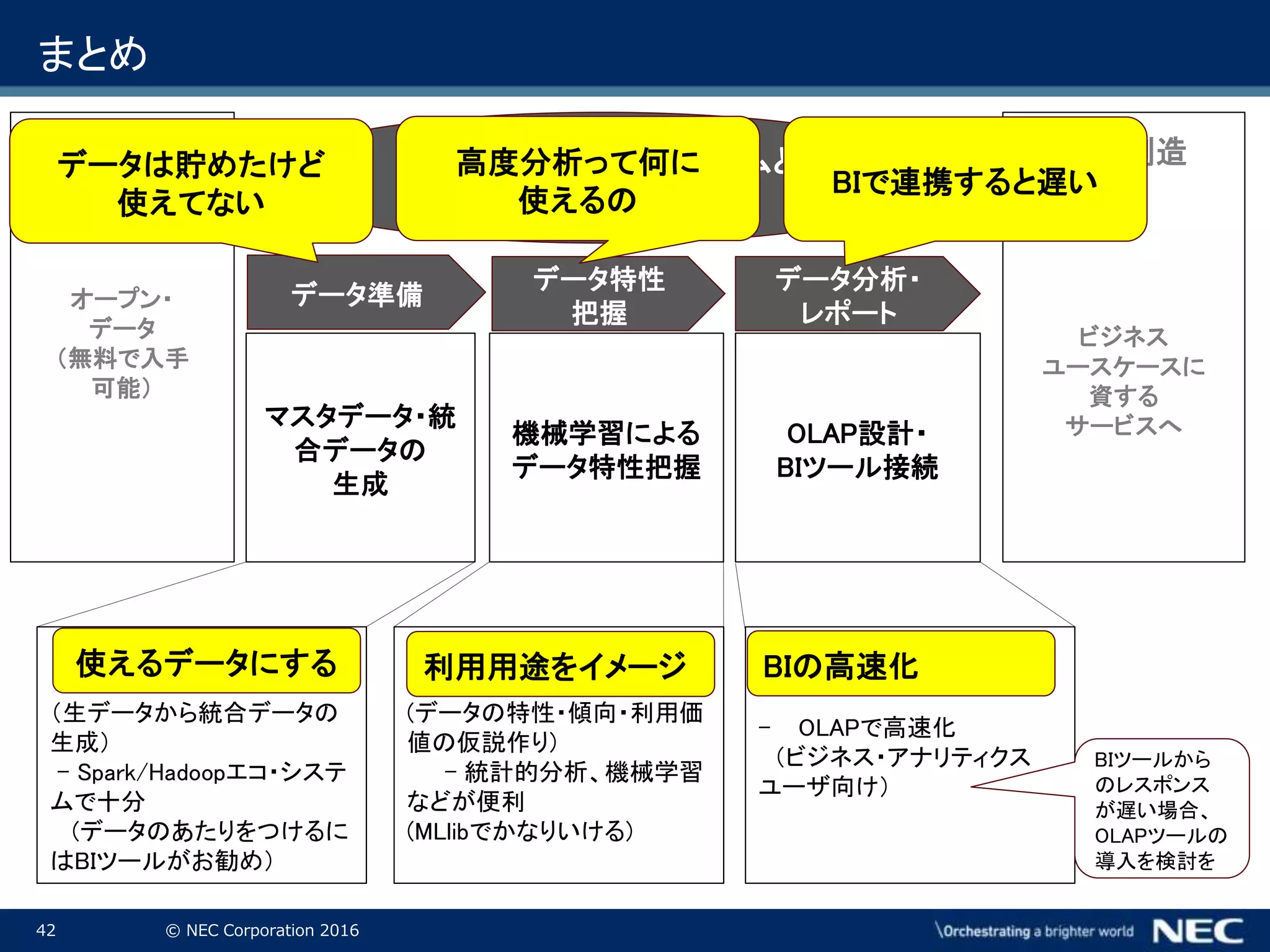
Corporation 2016 まとめ マスタデータ・統 合データの 生成 OLAP設計・ BIツール接続 価値創造 ビジネス ユースケースに 資する サービスへ機械学習による データ特性把握 データ準備 データ特性 把握 データ分析・ レポート Hadoop/Sparkエコシステムと OLAP連携で実現可能 データ オープン・ データ (無料で入手 可能) (生データから統合データの 生成) - Spark/Hadoopエコ・システ ムで十分 (データのあたりをつけるに はBIツールがお勧め) (データの特性・傾向・利用価 値の仮説作り) - 統計的分析、機械学習 などが便利 (MLlibでかなりいける) - OLAPで高速化 (ビジネス・アナリティクス ユーザ向け) BIツールから のレスポンス が遅い場合、 OLAPツールの 導入を検討を データは貯めたけど 使えてない 使えるデータにする 利用用途をイメージ 高度分析って何に 使えるの BIで連携すると遅い BIの高速化
43.
43 © NEC
Corporation 2016 ODPi(Open Data Platform Initiative)とは 共通のリファレンス仕様とテストスイートを策定しビッグデータエコシステムの簡素化・ 標準化を推進する非営利団体 ODPiの目的 オープンソースベースのビッグデータソリューションで標準的に用いられるコンポーネントを 定義・統合・テスト・認証することで、安定したビッグデータソリューションを迅速に提供します。 さらにODPIコアを他のビッグデータコンポーネントを結合するための生成・テストツールを 準備することで、さまざまなユーザニーズに対応できる柔軟性も持ち合わせます。 参加メンバー Hortonworks, IBM, Povotalをはじめ29企業が参加 NECも参加し、私がNECの窓口として主に活動 ODPiの活動概要 2015年2月 ODPi設立 2016年3月 ODPi Runtime Specification 1.0をリリース 2016年9月27日 ODPi Runtime Specification 2.0 をリリース 主な追加機能 Hive、HCFS(Hadoop Compatible File System)のサポート 本活動にご興味があれば以下のURLをぜひ参照ください。 https://www.odpi.org/ その他のHadoop関連活動 ODPi活動
45.
45 © NEC
Corporation 2016 参考
46.
46 © NEC
Corporation 2016 Apache Kylinとは - 非常に高速でスケールするOLAPエンジン Kylinは100億件を超えるデータに対し、Hadoop上でのクエリの遅延を減らす設計 - Hadoop上でのANSI SQLインターフェース KylinはHadoop上でのANSI SQLを提供し、多くのANSI SQLクエリ機能をサポート - MOLAP Cube データモデルを定義し100億件を超える生データのレコードをKylinにプレビルド可能 - BIツールとのシームレスな統合 Kylinは現在、Tableau, Power BIやExcelのようなBIツールとの統合機能を提供。 Microstrategyは近日リリース予定 - その他のハイライト - ジョブ管理とモニタリング - 圧縮とエンコーディングのサポート - Cubeのインクリメンタル リフレッシュ - 重複排除カウント用の近似クエリ(HyperLogLog) - 管理・構築、モニタ、Cubeのクエリ様の簡易Webインターフェース - Cube/プロジェクト レベルでACLを設定するセキュリティ機能 - LADP統合 出展: http://kylin.apache.org/ の WHAT IS KYLIN?より
47.
47 © NEC
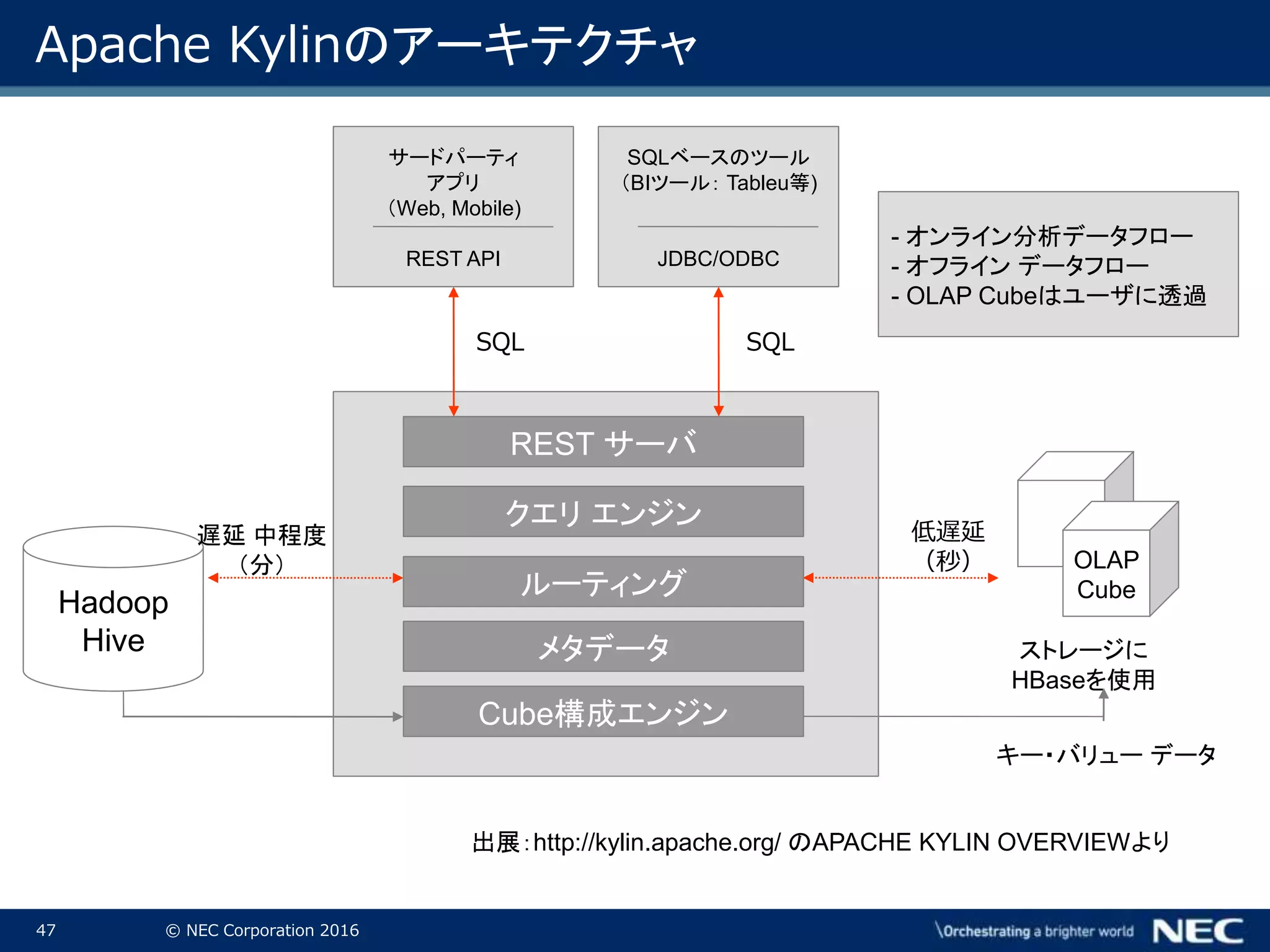
Corporation 2016 Apache Kylinのアーキテクチャ サードパーティ アプリ (Web, Mobile) REST API SQLベースのツール (BIツール: Tableu等) JDBC/ODBC Hadoop Hive REST サーバ クエリ エンジン ルーティング メタデータ Cube構成エンジン 遅延 中程度 (分) 低遅延 (秒) OLAP Cube ストレージに HBaseを使用 キー・バリュー データ SQL SQL - オンライン分析データフロー - オフライン データフロー - OLAP Cubeはユーザに透過 出展:http://kylin.apache.org/ のAPACHE KYLIN OVERVIEWより
Download