Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yoshikazu Suganuma
PPTX, PDF
1,596 views
データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
Hadoop Spark Conference 2019 データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
Data & Analytics
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
Apache Hadoopの現在と未来
by
Yahoo!デベロッパーネットワーク
PDF
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
スキーマレスカラムナフォーマット「Yosegi」で実現する スキーマの柔軟性と処理性能を両立したログ収集システム / Hadoop / Spark Con...
by
Yahoo!デベロッパーネットワーク
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
Apache Hadoopの現在と未来
by
Yahoo!デベロッパーネットワーク
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
スキーマレスカラムナフォーマット「Yosegi」で実現する スキーマの柔軟性と処理性能を両立したログ収集システム / Hadoop / Spark Con...
by
Yahoo!デベロッパーネットワーク
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
What's hot
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
PPT
Hadoop loves H2
by
Tadashi Satoh
PDF
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
PPT
Amazon Redshift ベンチマーク Hadoop + Hiveと比較
by
FlyData Inc.
PDF
Hadoop概要説明
by
Satoshi Noto
PDF
Hadoop入門
by
Preferred Networks
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
PDF
Hadoopことはじめ
by
均 津田
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PDF
(LT)Spark and Cassandra
by
datastaxjp
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
Hadoop loves H2
by
Tadashi Satoh
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
Amazon Redshift ベンチマーク Hadoop + Hiveと比較
by
FlyData Inc.
Hadoop概要説明
by
Satoshi Noto
Hadoop入門
by
Preferred Networks
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
Hadoopことはじめ
by
均 津田
HDFS Router-based federation
by
NTT DATA OSS Professional Services
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
(LT)Spark and Cassandra
by
datastaxjp
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Similar to データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
PPT
Hadoop~Yahoo!Japanの活用について
by
kaminashi
PPTX
20170803 bigdataevent
by
Makoto Uehara
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
第1回Hadoop関西勉強会参加レポート
by
You&I
PDF
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
PDF
Hadoopとは
by
Hirokazu Yatsunami
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
PDF
Hadoop operation chaper 4
by
Yukinori Suda
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
PPTX
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
PDF
Yahoo! JAPANのデータ基盤とHadoop #dbts2016
by
Yahoo!デベロッパーネットワーク
PDF
Hadoopの概念と基本的知識
by
Ken SASAKI
PDF
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
PDF
Microsoft の深層学習への取り組み
by
Hirono Jumpei
Hadoop~Yahoo!Japanの活用について
by
kaminashi
20170803 bigdataevent
by
Makoto Uehara
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
第1回Hadoop関西勉強会参加レポート
by
You&I
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
Hadoopとは
by
Hirokazu Yatsunami
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
Hadoop operation chaper 4
by
Yukinori Suda
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
Yahoo! JAPANのデータ基盤とHadoop #dbts2016
by
Yahoo!デベロッパーネットワーク
Hadoopの概念と基本的知識
by
Ken SASAKI
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
Microsoft の深層学習への取り組み
by
Hirono Jumpei
データサイズ2ペタ ソネット・メディア・ネットワークスでのImpala活用とHadoop運用
1.
データサイズ2ペタ ソネット・メディア・ネットワークス でのImpala活用とHadoop運用 Hadoop / Spark
Conference Japan 2019 So-net Media Networks 菅沼 嘉一
2.
菅沼 嘉一 Yoshikazu Suganuma So-net
Media Networks 分析基盤T Cloudera Hadoopの障害対応したり、python/Goでツール作成したり Go言語好き!
3.
目次 ● Hadoopの用途 ● Hadoopの環境 ●
ビッグデータ管理大変だよね!
4.
Hadoopの用途
5.
Logicadとは... So-net Media Networksが提供する 広告配信プラットフォーム
6.
● 広告配信ログを保管 ● データサイズ:約2PB ●
総レコード数:約1.1兆 ● 1日あたり約8TB増加 ● 主にデータ分析用途
7.
Hadoopの環境
8.
サーバースペック(データノード) スペック: Dell PowerEdge R720xd/R730xd/R740xd/R740xd2(予定) メモリ:約370GB/サーバー HDD:約90~160TB/サーバー (10TB
x 18, 10TB x 12, 8TB x 12) PowerEdge R740xd
9.
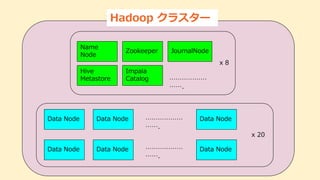
Hadoop構成 CDH 5.15 データノード:20 台
= 約2PB その他ノード:8台 (合計28台/1クラスター) (Zookeeper, Journal NodeにはIntel Optane SSDストレージ搭載) メタデータはAWS RDSに保管 Active-Standby の2クラスター構成
10.
Data Node Data
Node Data Node Data Node Data Node Data Node ……………… ……. ……………… ……. x 20 Name Node Zookeeper JournalNode Hive Metastore Impala Catalog ……………… ……. x 8 Hadoop クラスター
11.
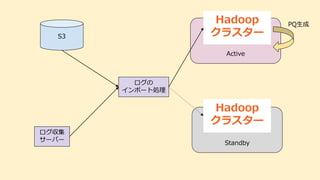
Active Hadoop クラスター Standby Hadoop クラスター S3 ログの インポート処理 ログ収集 サーバー PQ生成
12.
主なImpalaの使い方 Hiveから1時間毎にParquet生成 Impala + Parquet
はレスポンス最速 クエリ数:約13万クエリ/月 PQサイズ:約750TB
13.
ビッグデータ管理 大変だよね.....!?
14.
すぐに容量枯渇する...!? 8TB/day 増加するので容量を注視 保存期間をまめに調整 データ容量が90%近くになると Hive, Impalaのレスポンスが悪くなる傾向 早めにデータノードを追加
15.
DBのパーティション数は約18万 データをパーティショニングすることで性能は上がるが パーティション数がボトルネックになることがある 過去にImpalaが動かなくなったこともある (CDH5.7で約20万あった時) 推奨値は3~4万だとか....無理ゲーじゃない?
16.
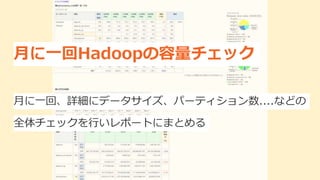
月に一回Hadoopの容量チェック 月に一回、詳細にデータサイズ、パーティション数....などの 全体チェックを行いレポートにまとめる
17.
Elasticsearch+kibanaで監視 データ容量の推移をグラフ化 HDFSの各種データサイズをhdfsコマンドで取得し Elasticsearchに貯める Impalaクエリの傾向調査 Cloudera Manager APIからImpalaクエリを取得して Elasticsearchに貯める
18.
バージョンアップは覚悟しておけ....!? (マジで) CDHのバージョンアップはどこかでミスがあると インストールできなくなる(「戻る」は押さない) そのためActive-Standbyの2クラスターを構築 (片方づつバージョンアップ)
19.
Active-Standbyの2クラスター構成 同じHW構成を2つ構築して片方づつ運用 メリット: バージョンアップ作業、機能検証がはかどる デメリット: コストがかかる 移行コストが高い
20.
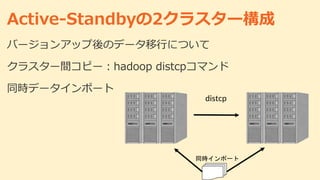
Active-Standbyの2クラスター構成 バージョンアップ後のデータ移行について クラスター間コピー:hadoop distcpコマンド 同時データインポート distcp 同時インポート
21.
CDHバージョン遍歴 今年はCDH6.1にバージョンアップ予定 年代 クラスターA クラスターB 2015~
CDH5.1 (hadoop-2.3.0) 2016~ CDH5.7 (hadoop-2.6.0) 2018~ CDH5.15(現在) (hadoop-2.6.0) 2019~ CDH6.1(構築中) (hadoop-3.0.0)
22.
Thanks !
Editor's Notes
#4
本日の目次ですがスライドにありますように ・Hadoopの用途 ・Hadoopの環境 ・ビッグデータを管理をしていく上での大変だったところ を紹介したいと思います。
#6
ソネット・メディア・ネットワークスではDSP型の広告配信プラットフォームであるLogicadというサービスを提供しています。 膨大な配信ログをもとに最適な入札額を推定し、精度の高いターゲティングを提供しています。
#7
Hadoopの用途としては、主にLogicadの広告配信ログを保管しています。 全体総量としてのデータサイズは約2ペタバイトを保管していて、レコード数としては約1.1兆レコードになります。 一日あたりに増加するログの量としては、約8TB近く増えていっています。 ログの使用用途ついてですが、主にデータ分析の用途に使っています。
#8
次にHadoopの環境を紹介します
#9
Hadoopはオンプレ環境で運用しています。 データノードのサーバースペックですが、Dell製のPowerEdge R720xdからR740xdを使っています。 メモリは1台あたり約370ギガバイトのメモリを用意し、ディスク容量は1台あたり90テラバイトから160テラバイトを搭載しています。
#10
Hadoop構成についてですが、HadoopのディストリビューションはCloudera Hadoopを使っておりバージョンは5.15です。 データノードは20台、データノード以外のノードは8台あり、合計で1クラスターあたり28台で構成しています。 一部ZookeeperとJournal NodeにはIntel Optane SSDメモリを搭載しています。 またバージョンアップを考慮して、同じサーバー構成を2つ用意してActive-Standby の2クラスター構成で運用しています。 それについては後程スライドで紹介したいと思います。
#11
システム構成図ですが、説明は飛ばします。
#13
主なImpalaの使い方についてです。 主にやっていることは、ログを1時間ごとにHiveで読みとってParquet形式に変換しています。 カラム指向のParquetファイルをImpalaで検索する組み合わせは、体感的にとても早いと感じていて基本的にImpalaを使っています。 クエリ数:約13万クエリ/月でPQサイズ:約750TBです
#14
次にビッグデータを管理していく上での大変なところを紹介します。
#15
一日当たり8TB増加するのですぐに容量が枯渇していきます。 そのために容量を常にチェックしており、まめに古いデータを削除して保存期間を調整しています。 またデータ容量が90%近くになるとHive, Impalaのレスポンスが悪くなる傾向わかっているので、データ増加を予測して早めのデータノードを追加していきます。
#16
データ容量も問題になることもありますが、パーティション数が多すぎることで問題が起こることもありました。 一つ前の世代のクラスターでは5.7を使っていてパーティションが20万あった時があり、Impalaが動かなくなったことがありました。 今のバージョン5.15では多めの18万パーティションあっても動くようです。 Clouderaの推奨値では5万以下のパーティション数に抑えるようにと聞いたことがありますが、非常に難しいんじゃないかと思っています。
#17
データサイズの傾向やパーティション数を把握するために、月に一回Hadoopの全体チェックをしています。 全体チェックをすることで、データベースのテーブル数や個々のデータサイズの増加傾向を把握したり、パーティション数を把握できます。 そうすることでパーティションの切り方を再検討してリスクを減らすことができるのでとても大事なレポートになっています。
#18
他にもElasticsearchとkibanaを使って監視もしています。 具体的に言うとバッチ処理によって、定期的にデータベースの各種データサイズとCloudera ManagerのAPIからクエリログをElasticsearchに貯めこんでいます。 時系列でデータの増加傾向を把握したり、クエリ調査に使ったりしています。
#19
Cloudera Hadoopのバージョンアップについてですが、これはほんとに苦労するポイントです。 どこの発表でもバージョンアップは大変と聞きますがほんとうに大変です。 インストール画面でどこかミスをするとインストールが先にすすまなくなり苦労するので Active-Stanbyの2クラスターを構築し、片方づつバージョンアップしています。
#20
Active-Standbyの2クラスター構成は主にバージョンアップ作業をスムースにするためにこの構成にしています。 ローリングアップデートも対応しているんですが、あまり信用していません。 ですが、反面デメリットとして倍の費用がかかるのでコストはとてもかかります。 またバッチ処理などを移し替えるために移行コストが高いという難点もあります。 そういうデメリットはありますがバージョンアップ作業が安心して行えるメリットが大きいのでこのような構成にしています。
#21
バージョンアップ後のデータ移行についてです。 hadoopのdistcpでデータを移行します。それと同時にログデータを両方のクラスターに更新することで、2つのクラスターを同期させます。
#22
最後にCDHバージョンですが、これまで第一世代のCDH5.1から始まり5.7、現在5.15と来ています。 今年の春から6.1のバージョンアップを目指して目下構築準備をすすめているところです。
#23
以上です ありがとうございました
Download