Downloaded 1,272 times



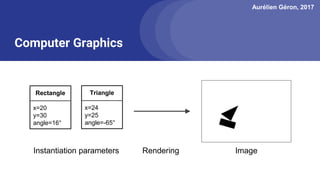
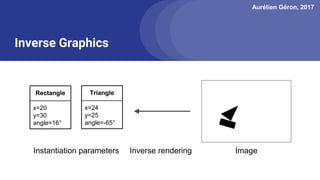
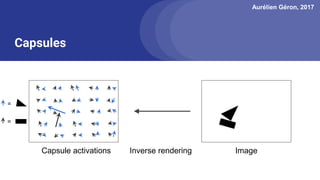
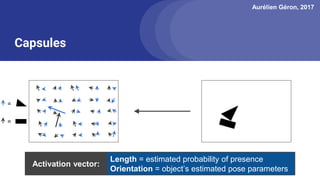
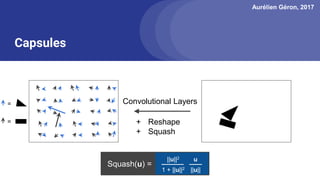
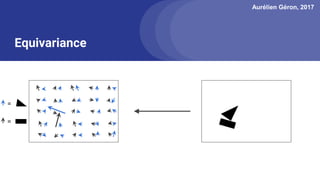
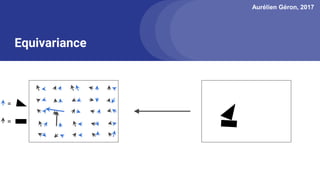

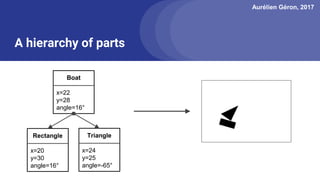
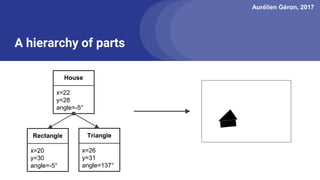
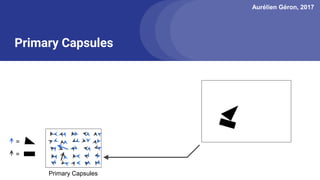
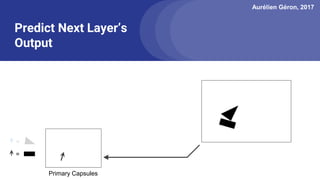
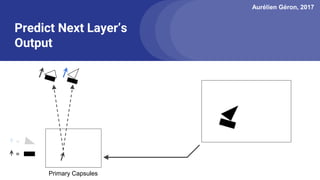
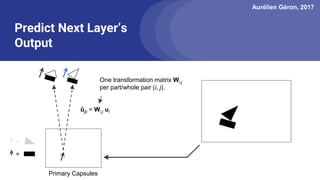
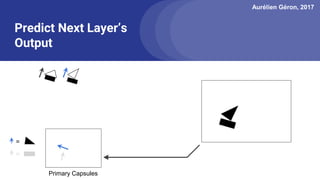
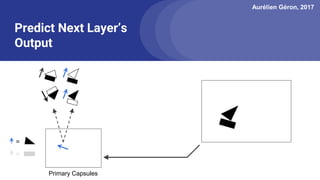
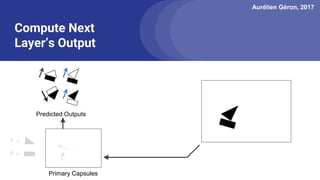
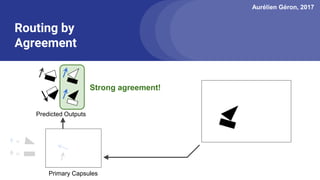
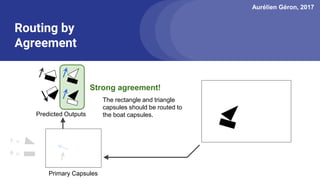
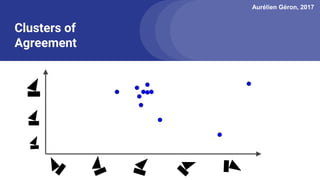
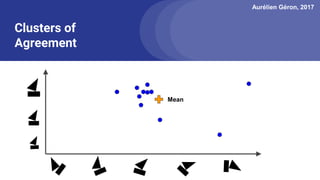
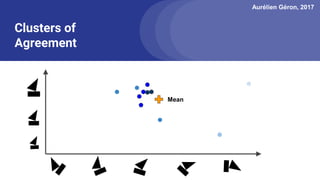
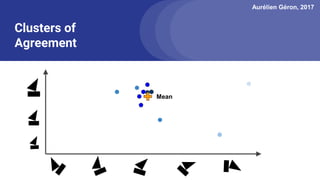
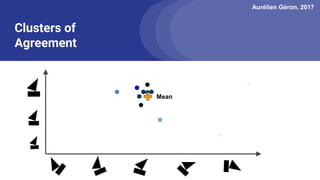
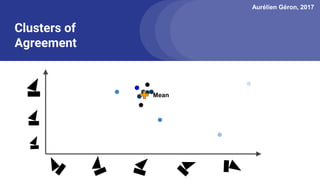
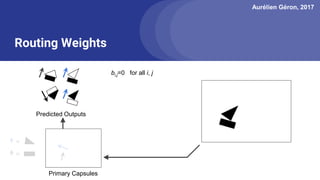
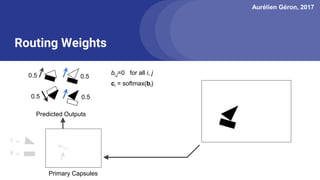
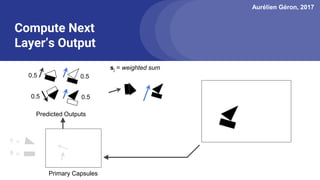
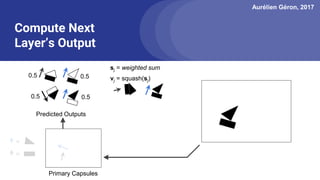
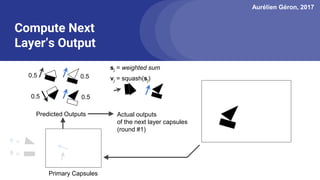
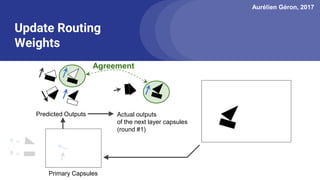
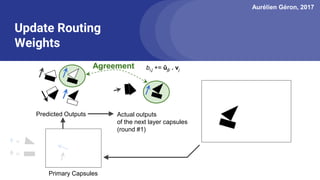
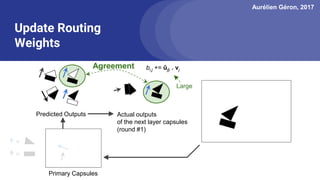
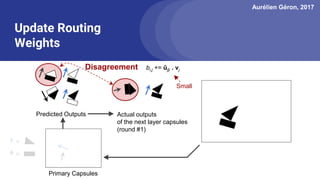
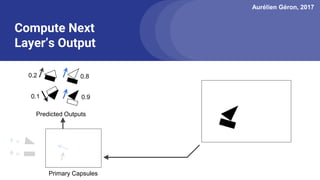
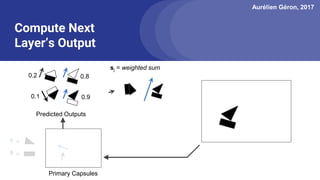
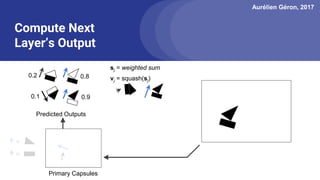
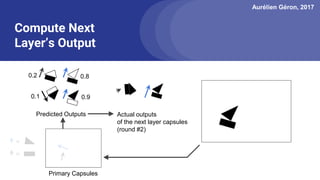
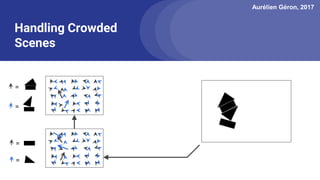
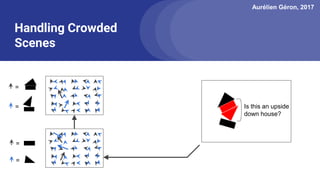
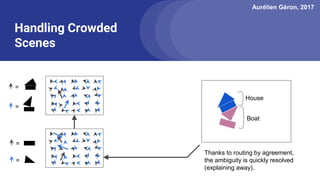
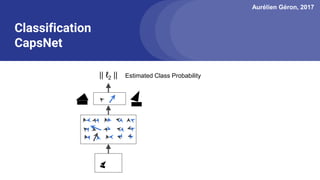
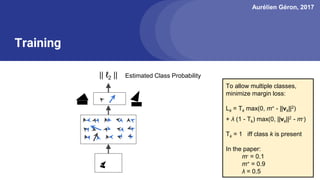
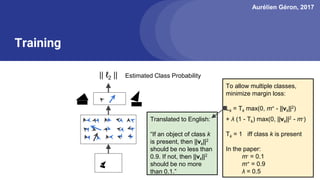
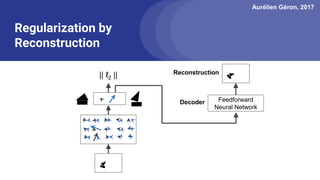
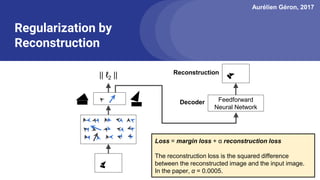

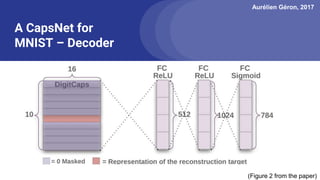






The document discusses capsule networks, focusing on their architecture and functionality, including dynamic routing, activations, and handling of perspective transformations. It highlights the advantages of capsule networks, such as high accuracy on MNIST and robustness to affine transformations, while also addressing limitations like slow training and issues with closely clustered objects. Additionally, it provides links to various implementations and resources related to capsule networks.










![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Paper] dynamic routing between capsules](https://cdn.slidesharecdn.com/ss_thumbnails/paperdynamicroutingbetweencapsules-210509101120-thumbnail.jpg?width=640&height=640&fit=bounds)





















