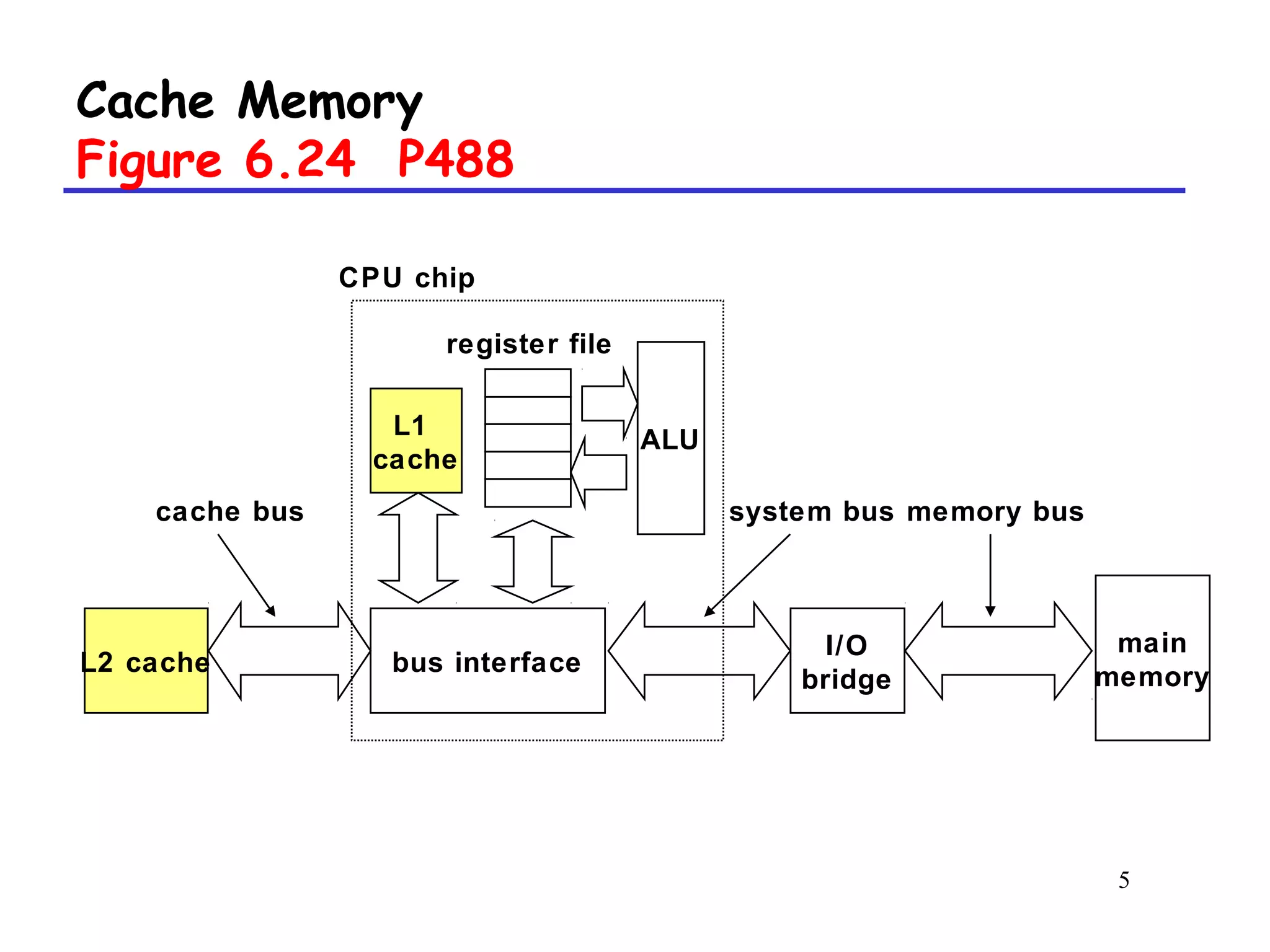
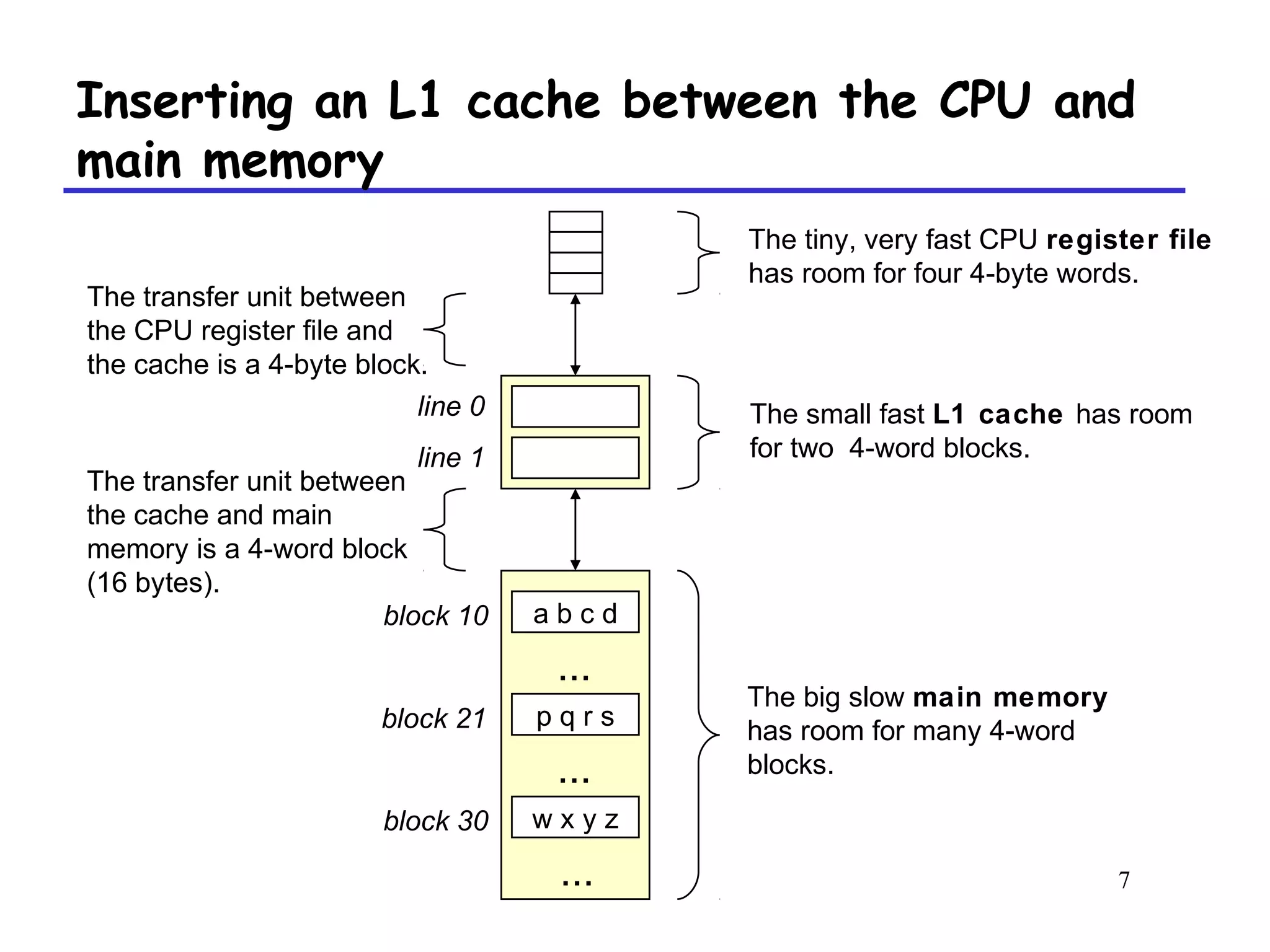
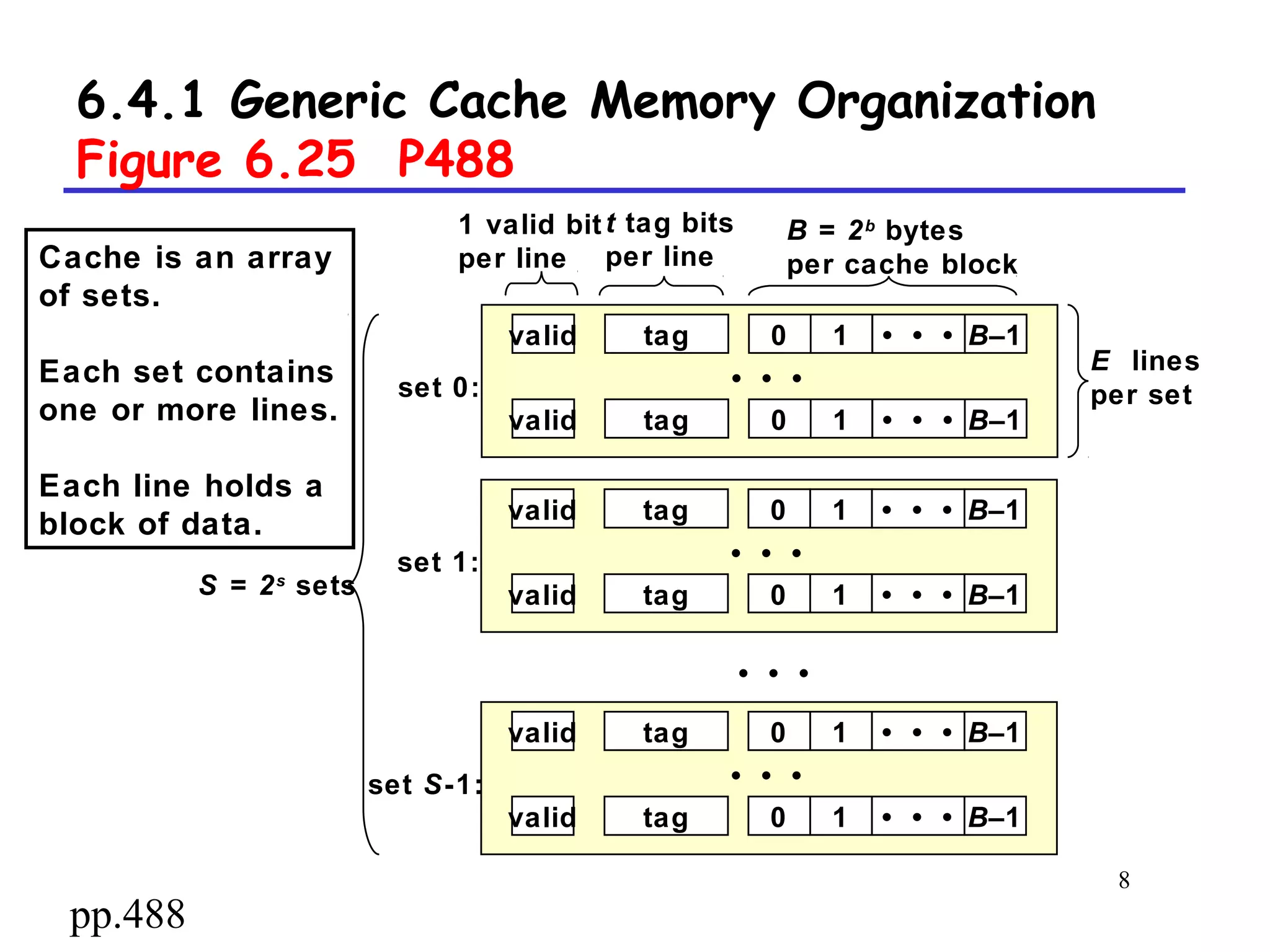
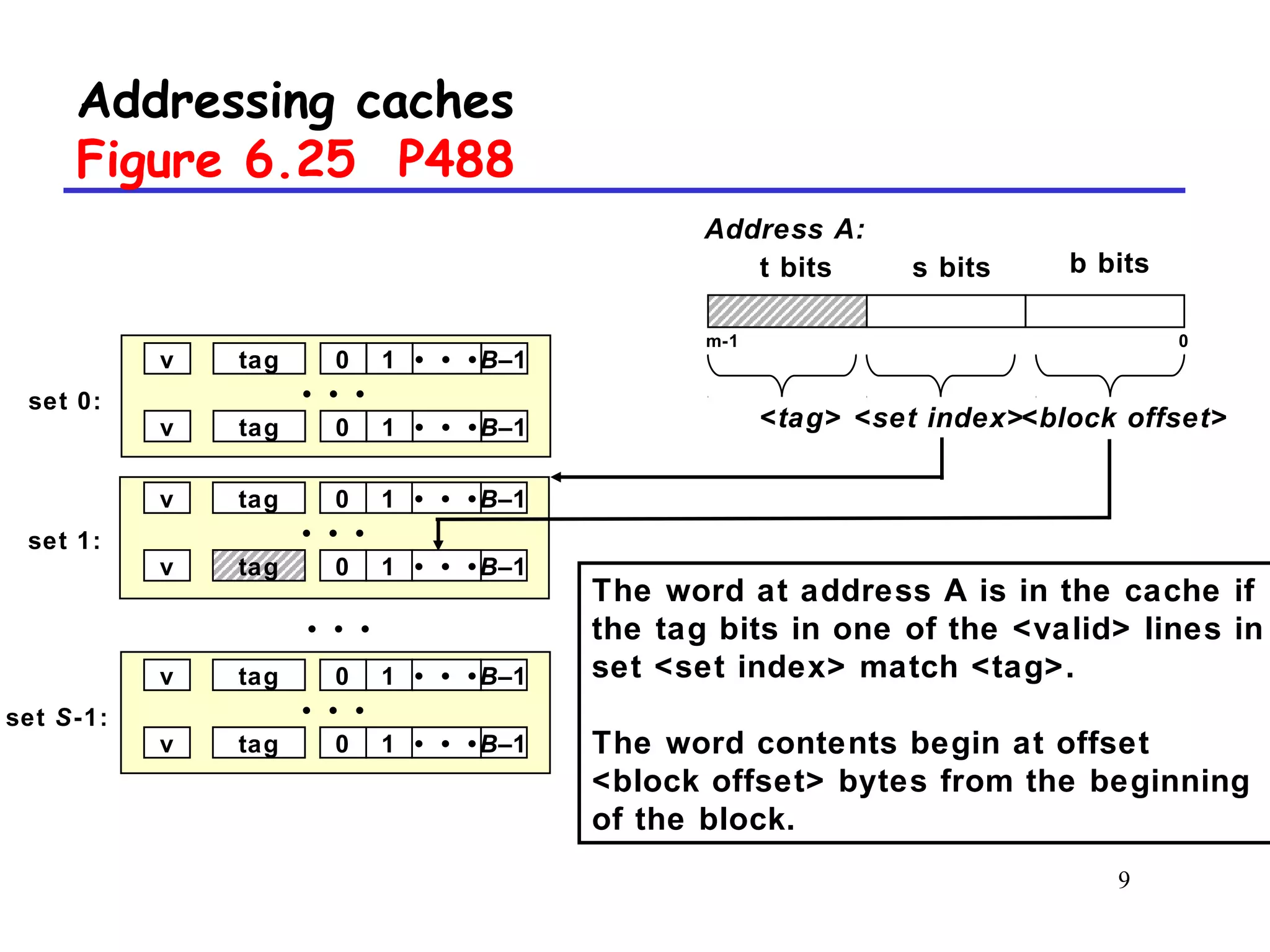
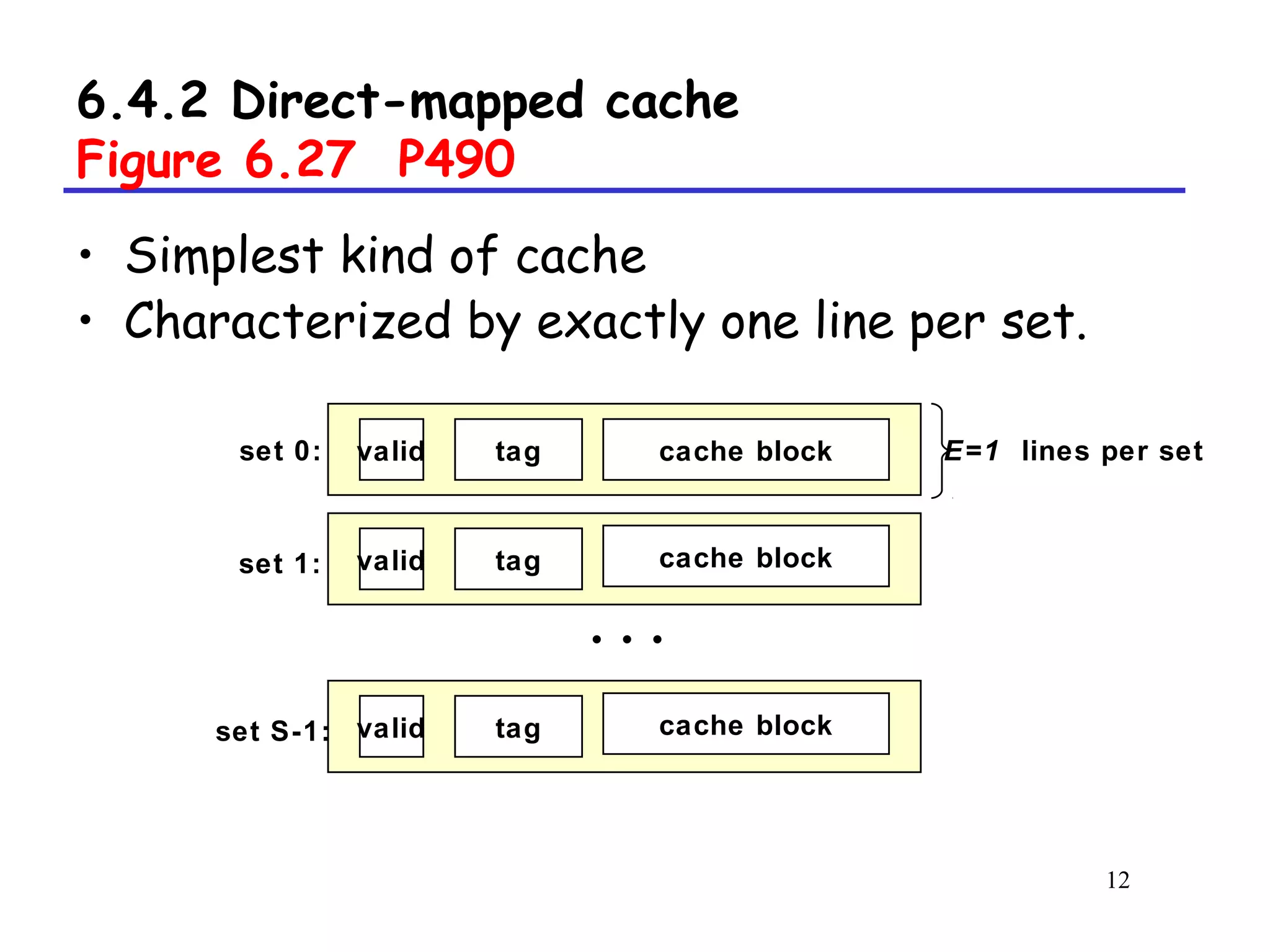
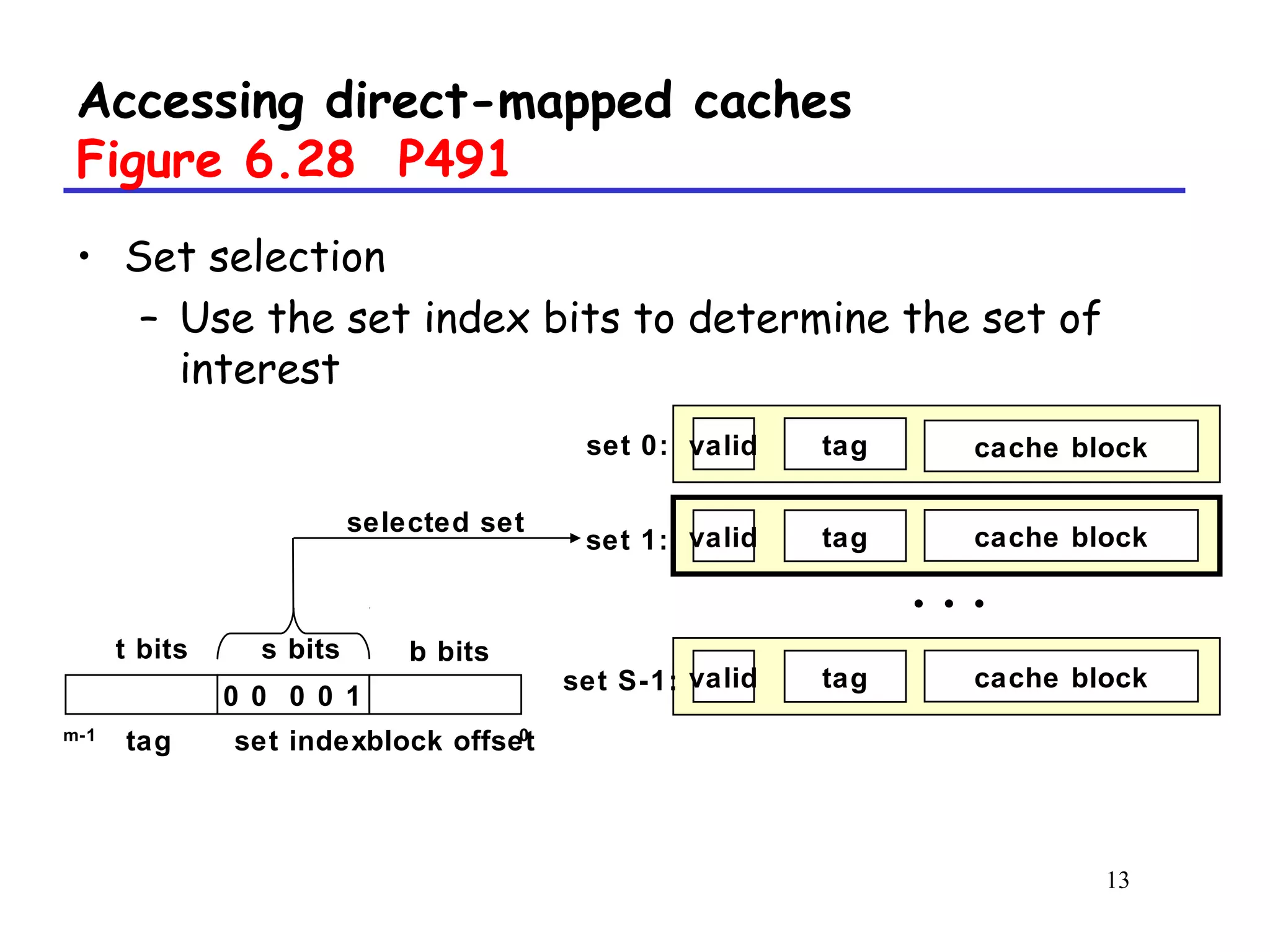
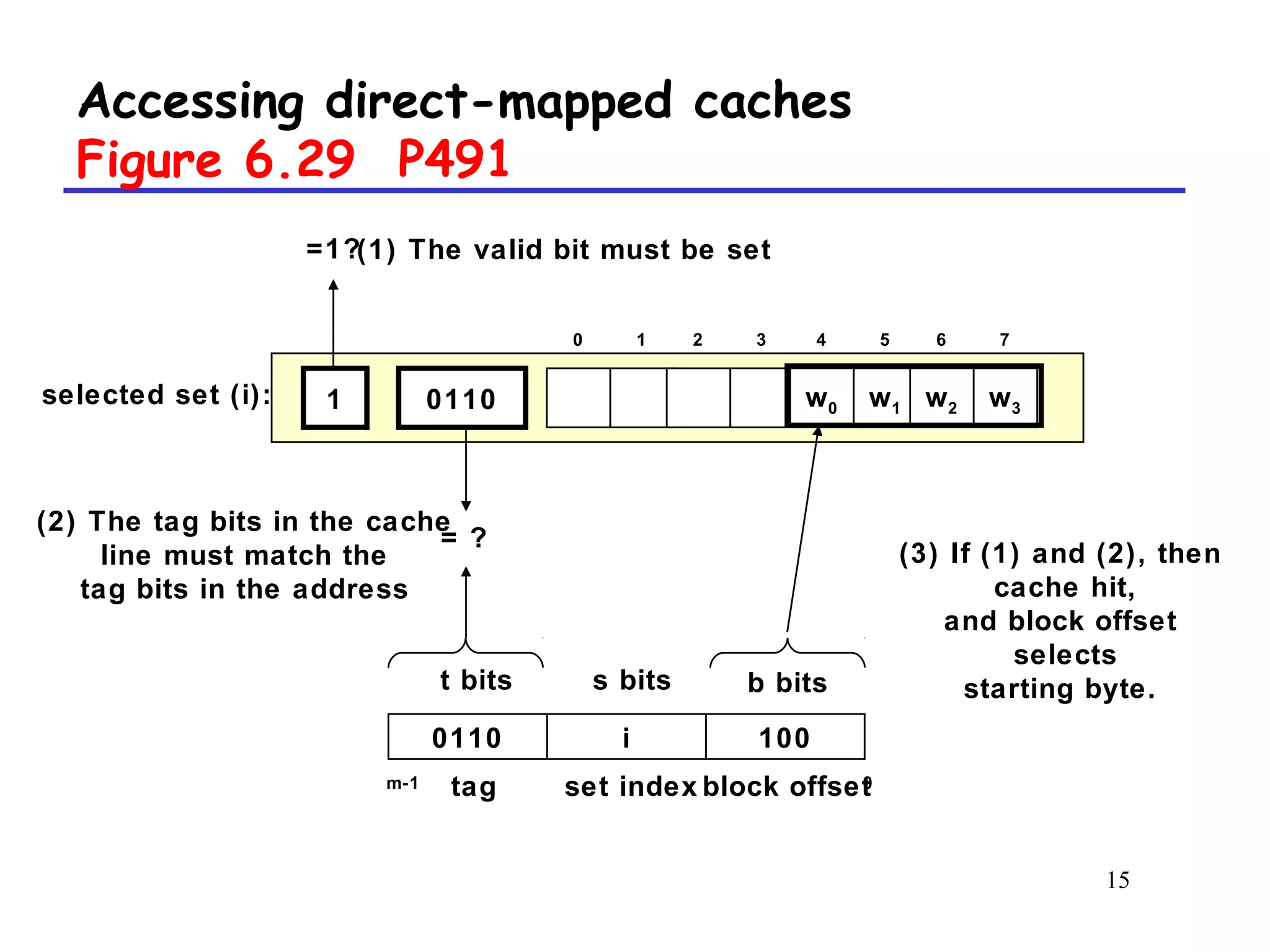
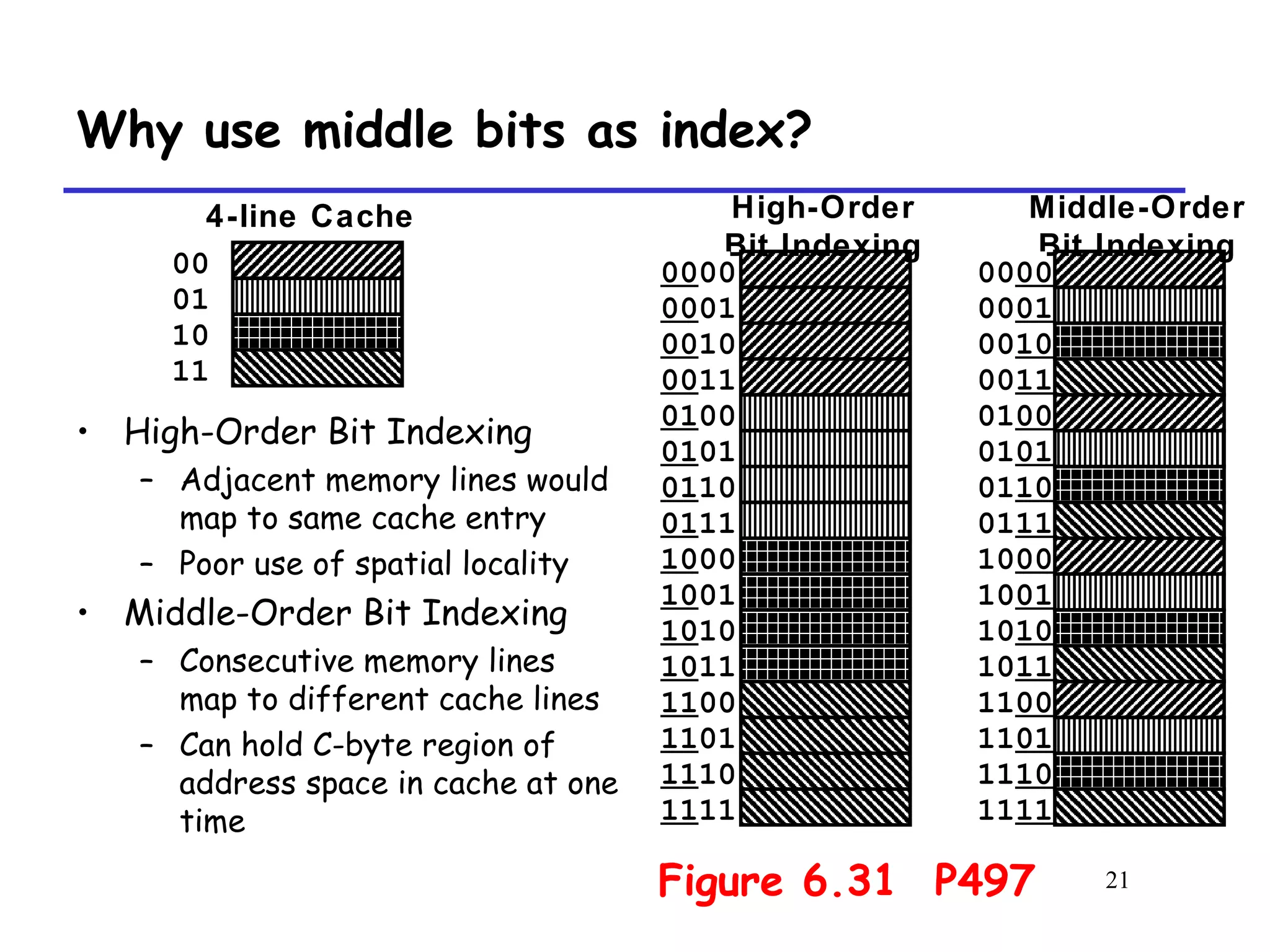
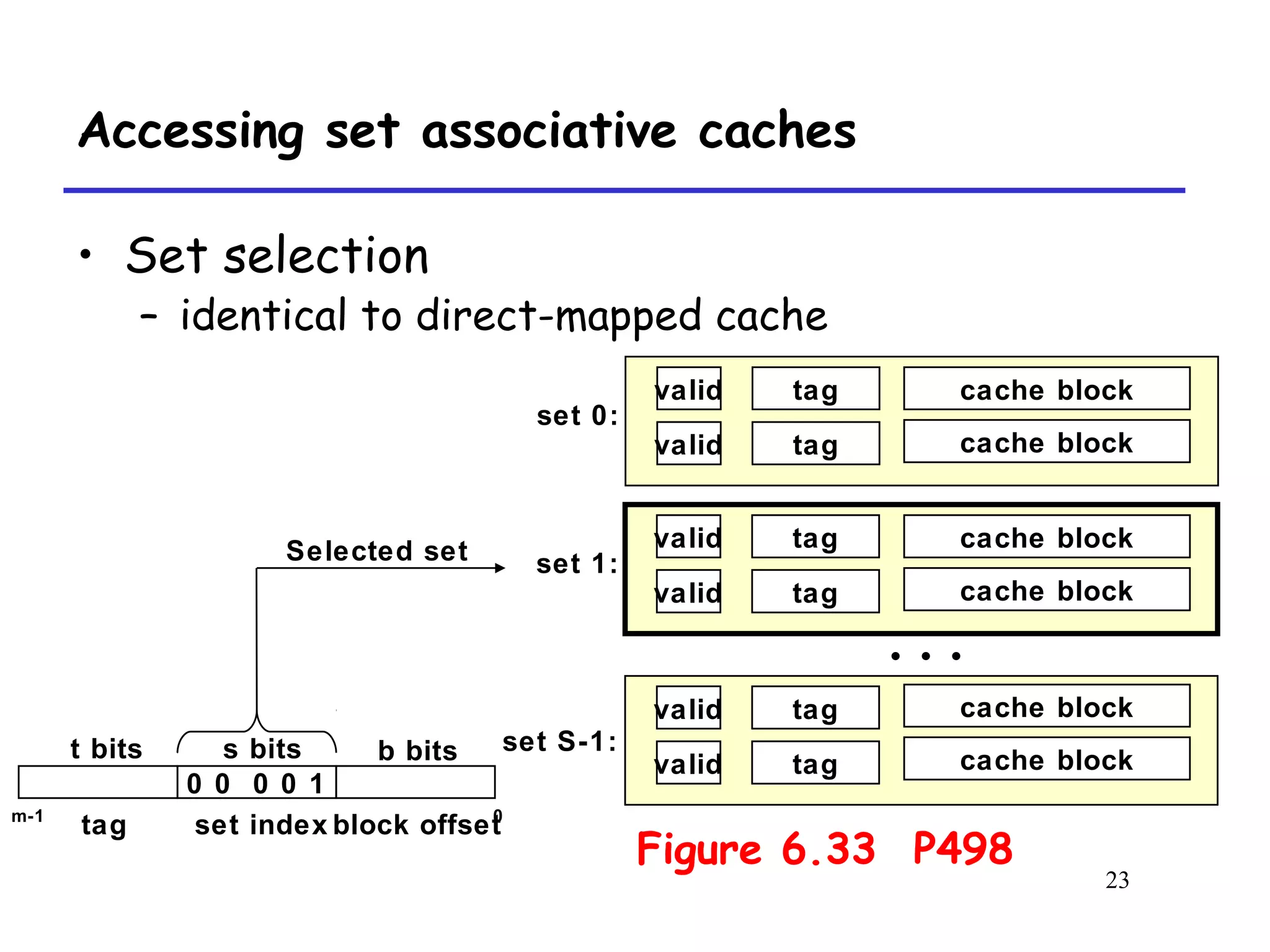
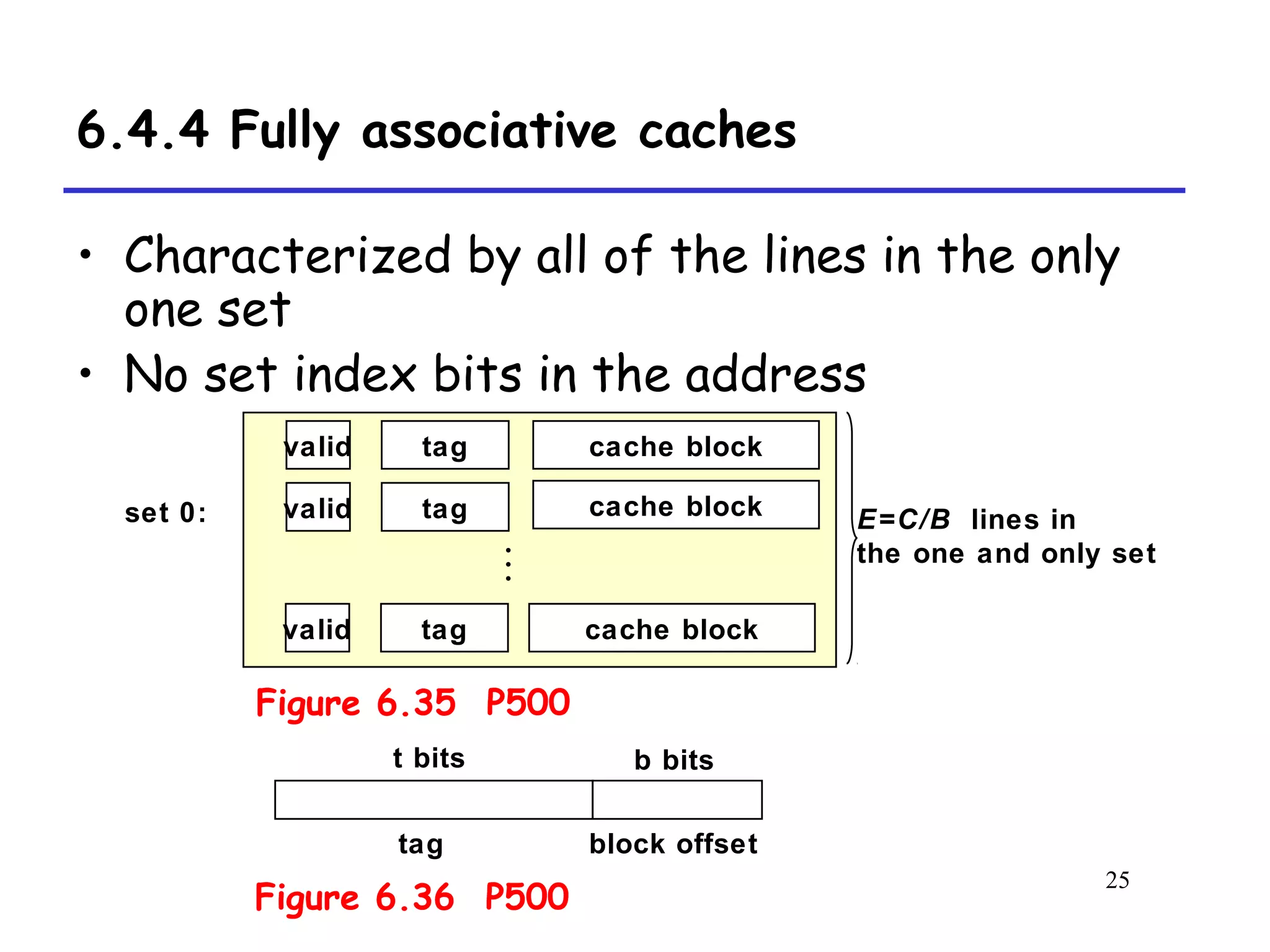
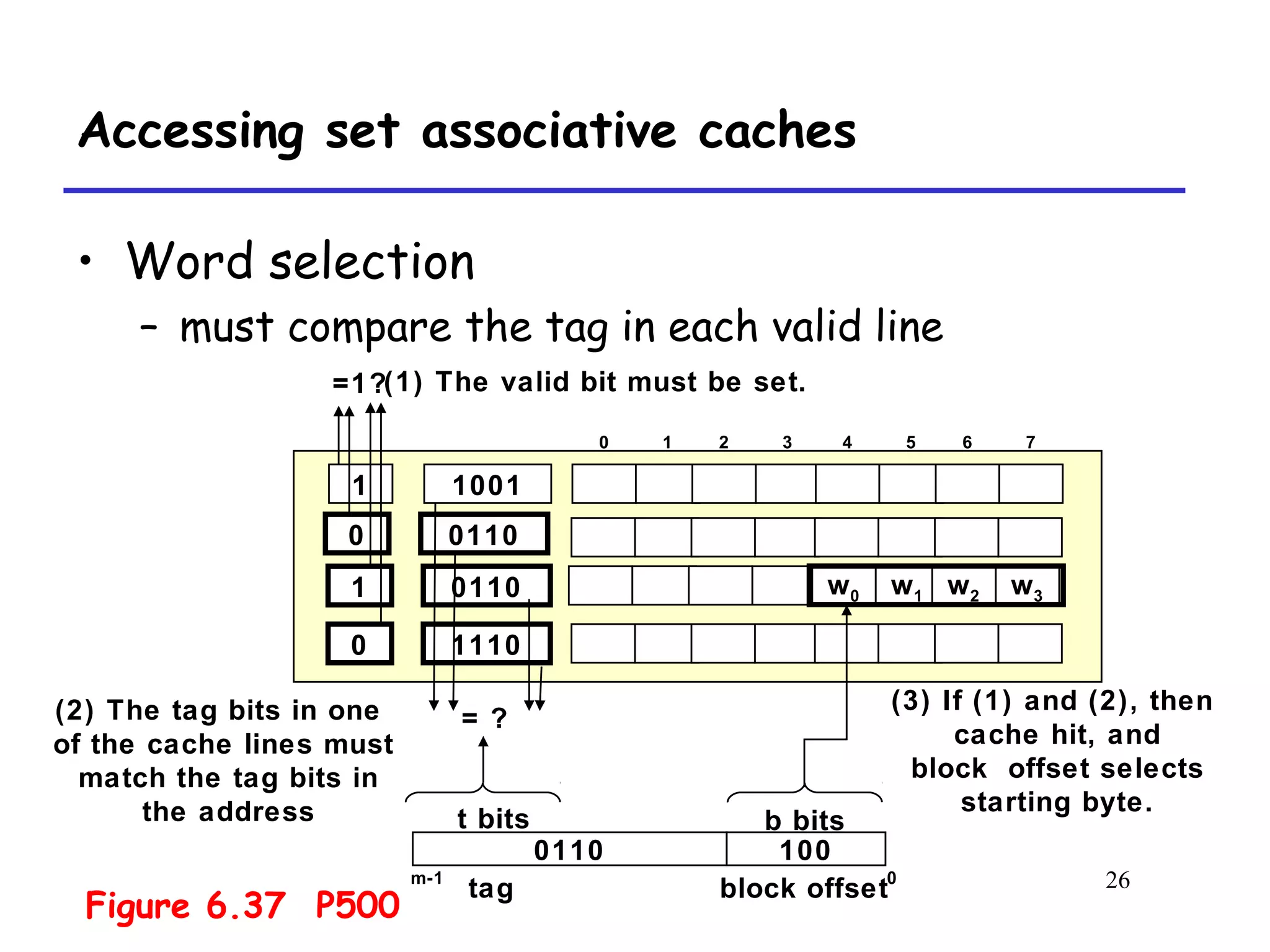
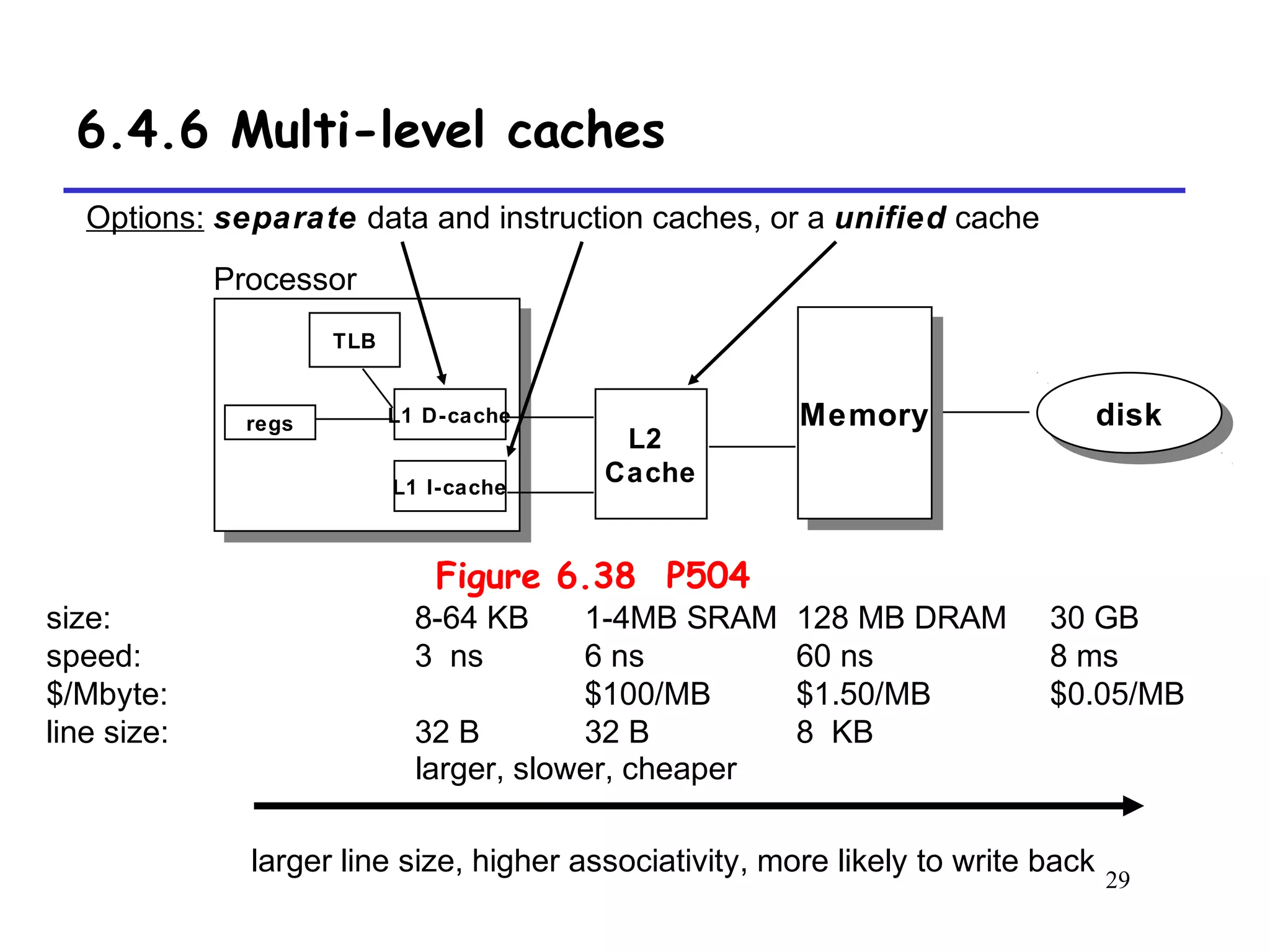
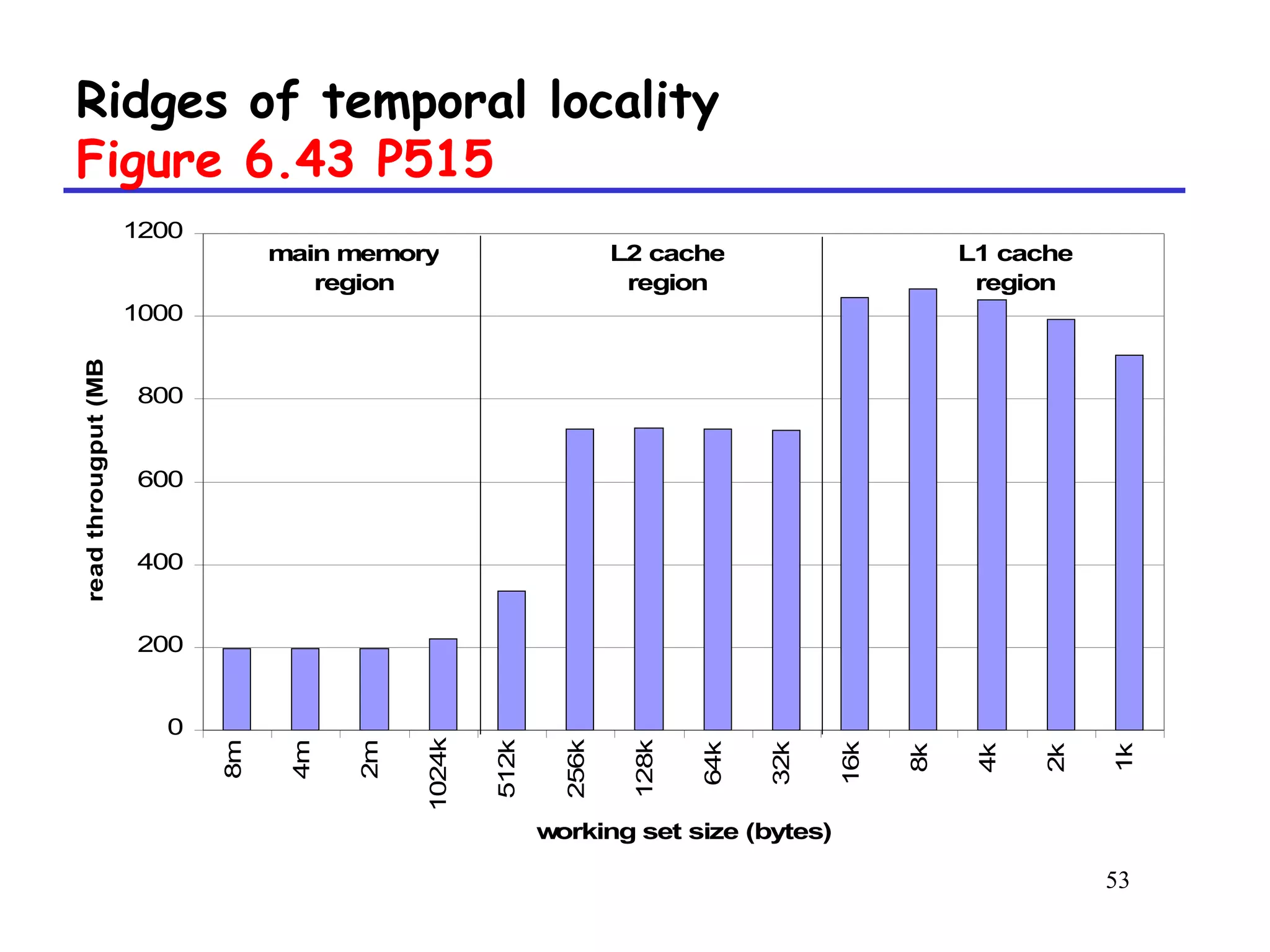
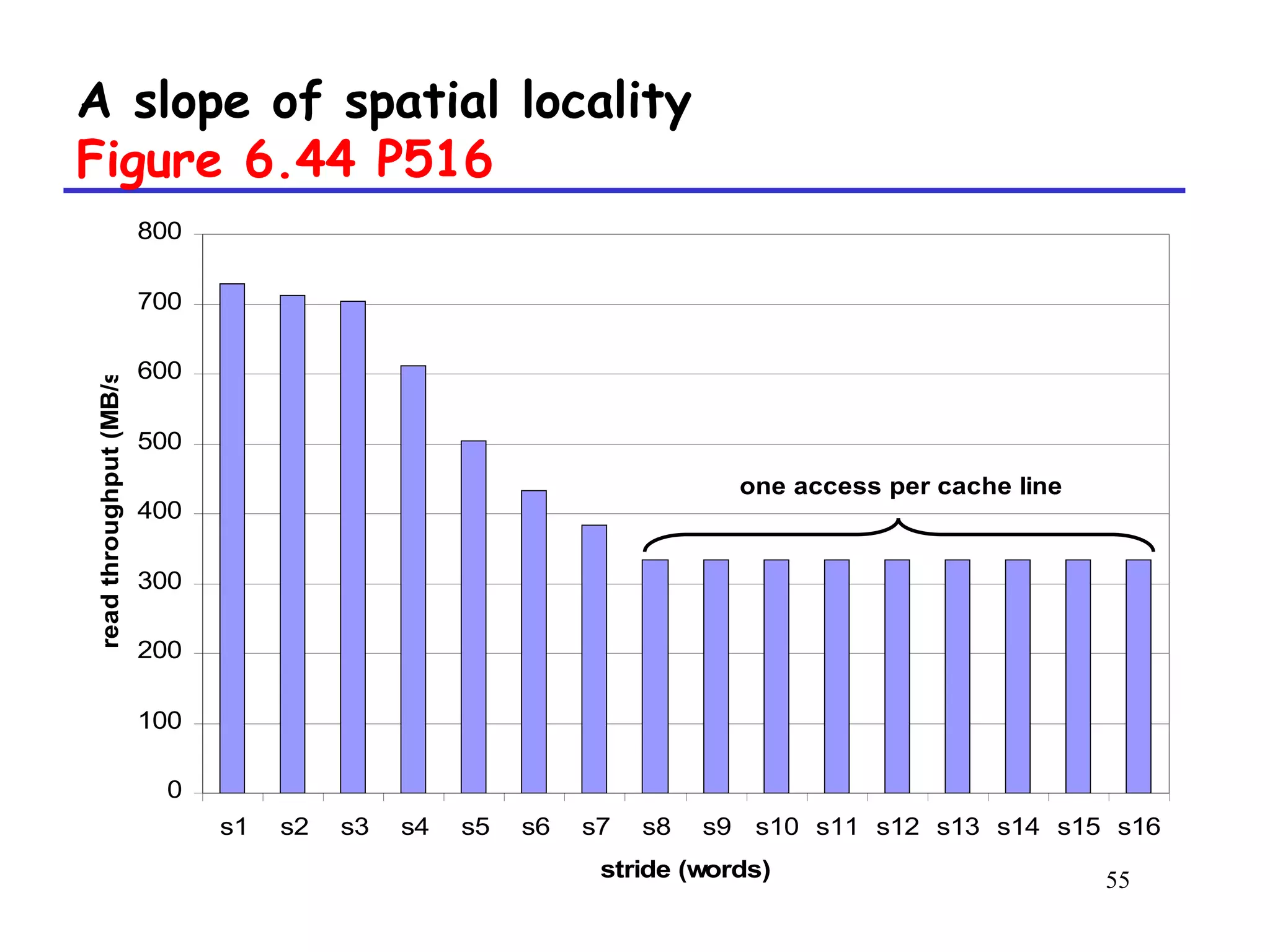
The document discusses cache memory organization and how to write cache-friendly code. It describes the typical levels of cache memory (L1, L2, L3) and how they are organized. There are three main types of cache organization: direct-mapped, set-associative, and fully associative. The document provides examples of accessing each type of cache and discusses issues with writes. It emphasizes the importance of exploiting spatial and temporal locality when writing code to minimize cache misses.











![19
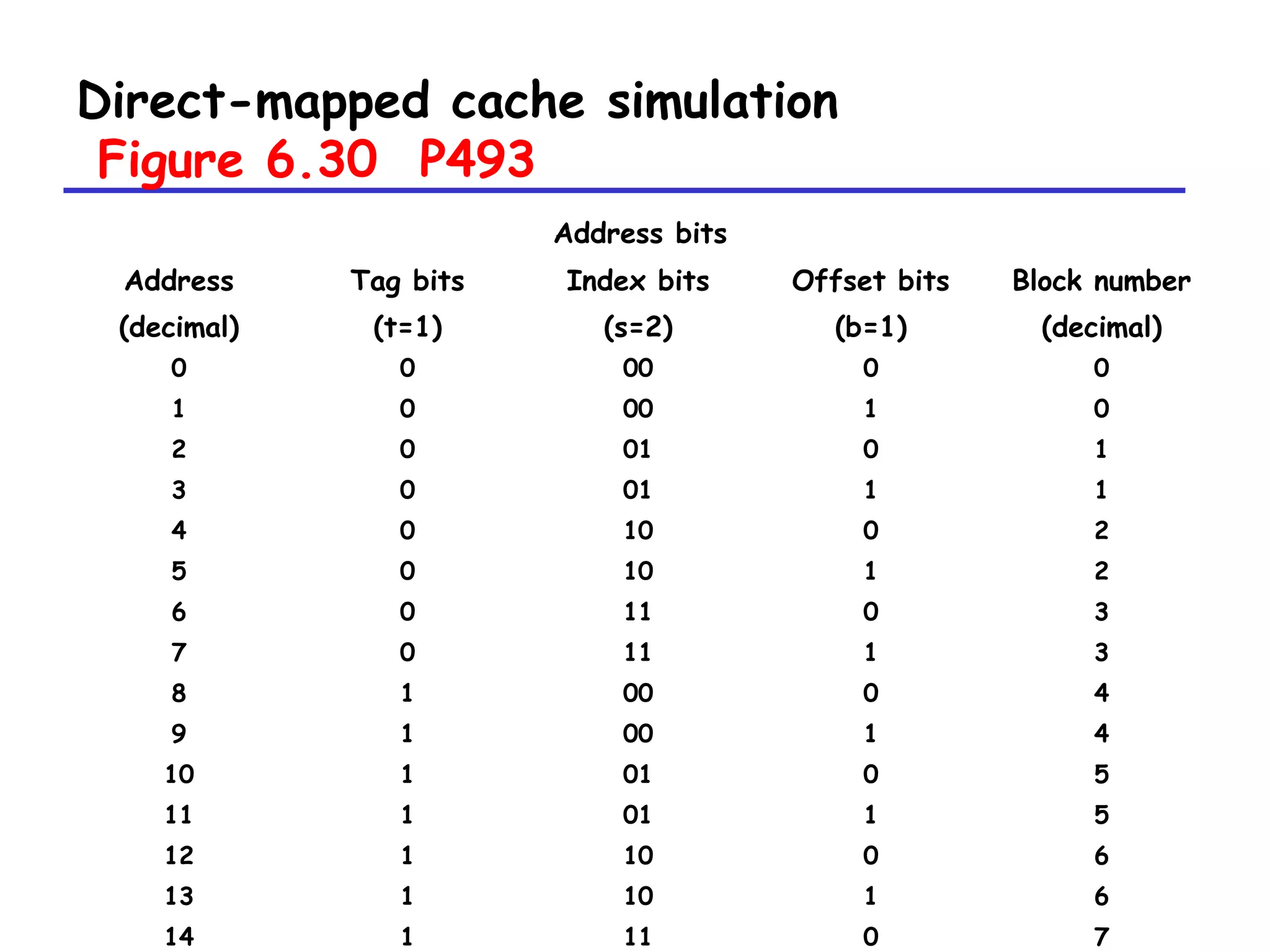
Direct-mapped cache simulation P493
1 0 m[1] m[0]
v tag data
1 1 m[13] m[12]
0 [0000] (miss)
(4)
1 1 m[9] m[8]
v tag data
1 1 m[13] m[12]
8 [1000] (miss)
(3)
1 0 m[1] m[0]
v tag data
1 1 m[13] m[12]
13 [1101] (miss)
(2)
1 0 m[1] m[0]
v tag data
0 [0000] (miss)
(1)
M=16 byte addresses, B=2 bytes/block, S=4 sets, E=1
entry/set
Address trace (reads):
0 [0000] 1 [0001] 13 [1101] 8 [1000] 0 [0000]
x
t=1 s=2 b=1
xx x](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-19-2048.jpg)










![36
Writing Cache-Friendly Code P507
8[h]7[h]6[h]5[m]4[h]3[h]2[h]1[m]Access order,
[h]it or [m]iss
i= 7i= 6i= 5i= 4i= 3i= 2i= 1i=0v[i]
Temporal locality,
These variables are usually put in registersint sumvec(int v[N])
{
int i, sum = 0 ;
for (i = 0 ; i < N ; i++)
sum += v[i] ;
return sum ;
}](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-36-2048.jpg)


![39
Writing cache-friendly code P508
• Example (M=4, N=8, 10cycles/iter)
int sumvec(int a[M][N])
{
int i, j, sum = 0 ;
for (i = 0 ; i < M ; i++)
for ( j = 0 ; j < N ; j++ )
sum += a[i][j] ;
return sum ;
}](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-39-2048.jpg)
![40
Writing cache-friendly code
a[i][j] j=0 j= 1 j= 2 j= 3 j= 4 j= 5 j= 6 j= 7
i=0
i=1
i=2
i=3
1[m]
9[m]
17[m]
25[m]
2[h]
10[h]
18[h]
26[h]
3[h]
11[h]
19[h]
27[h]
4[h]
12[h]
20[h]
28[h]
5[m]
13[m]
21[m]
29[m]
6[h]
14[h]
22[h]
30[h]
7[h]
15[h]
23[h]
31[h]
8[h]
16[h]
24[h]
32[h]](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-40-2048.jpg)
![41
Writing cache-friendly code P508
• Example (M=4, N=8, 20cycles/iter)
int sumvec(int v[M][N])
{
int i, j, sum = 0 ;
for ( j = 0 ; j < N ; j++ )
for ( i = 0 ; i < M ; i++ )
sum += v[i][j] ;
return sum ;
}](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-41-2048.jpg)
![42
Writing cache-friendly code
a[i][j] j=0 j= 1 j= 2 j= 3 j= 4 j= 5 j= 6 j= 7
i=0
i=1
i=2
i=3
1[m]
2[m]
3[m]
4[m]
5[m]
6[m]
7[m]
8[m]
9[m]
10[m]
11[m]
12[m]
13[m]
14[m]
15[m]
16[m]
17[m]
18[m]
19[m]
20[m]
21[m]
22[m]
23[m]
24[m]
25[m]
26[m]
27[m]
28[m]
29[m]
30[m]
31[m]
32[m]](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-42-2048.jpg)


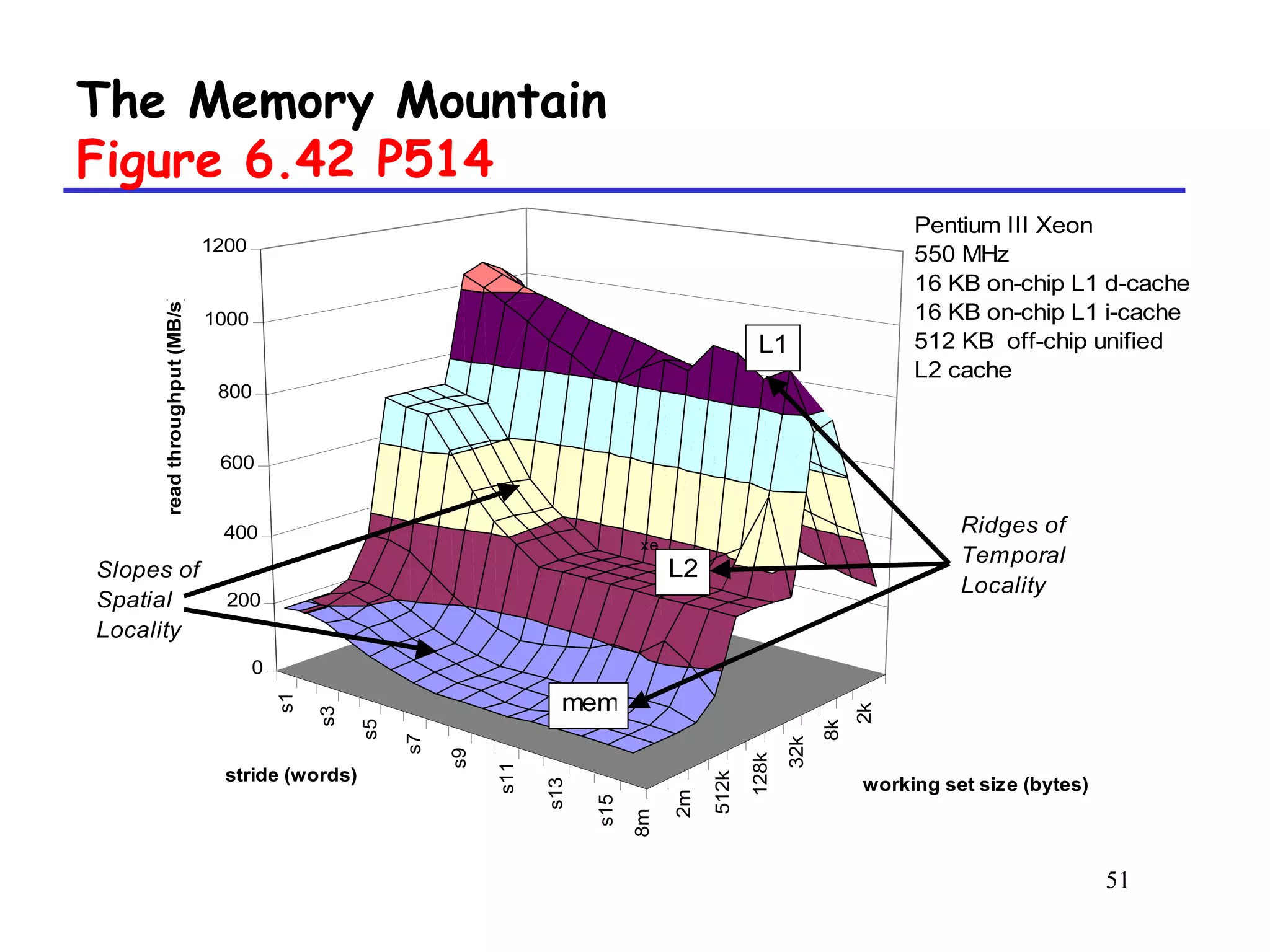
![45
Memory mountain main routine
Figure 6.41 P513
/* mountain.c - Generate the memory mountain. */
#define MINBYTES (1 << 10) /* Working set size ranges from 1 KB */
#define MAXBYTES (1 << 23) /* ... up to 8 MB */
#define MAXSTRIDE 16 /* Strides range from 1 to 16 */
#define MAXELEMS MAXBYTES/sizeof(int)
int data[MAXELEMS]; /* The array we'll be traversing */](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-45-2048.jpg)


![48
Memory mountain test function
Figure 6.40 P512
/* The test function */
void test (int elems, int stride) {
int i, result = 0;
volatile int sink;
for (i = 0; i < elems; i += stride)
result += data[i];
sink = result; /* So compiler doesn't optimize away the loop */
}](https://image.slidesharecdn.com/vuwjieb7qocucmtj5gqq-signature-ae26f77d3b74dab2b49fd9d5cac26e1d3e8bae38f07ed08692104e643a0387d3-poli-160427172511/75/Memory-caching-48-2048.jpg)



























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















