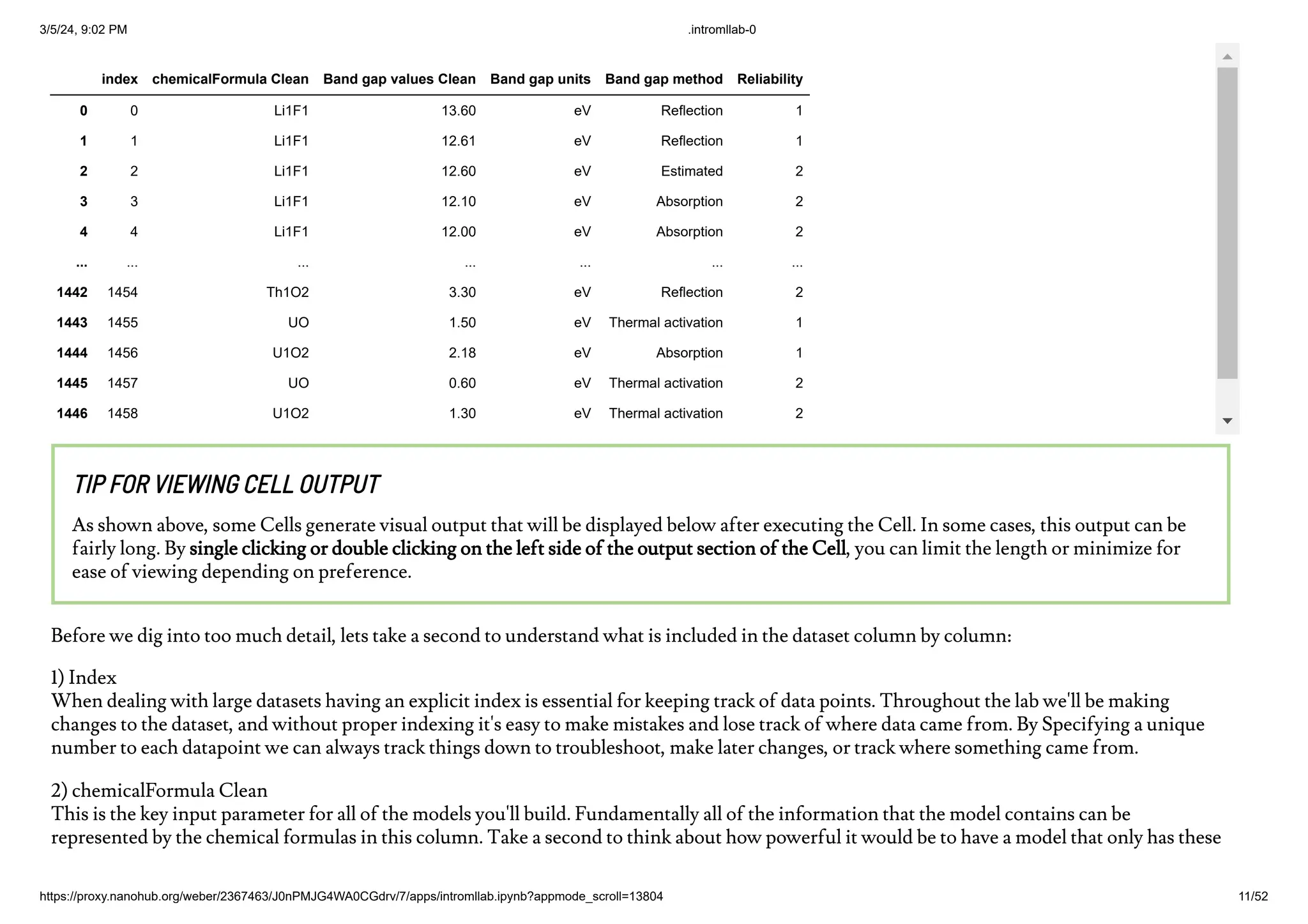
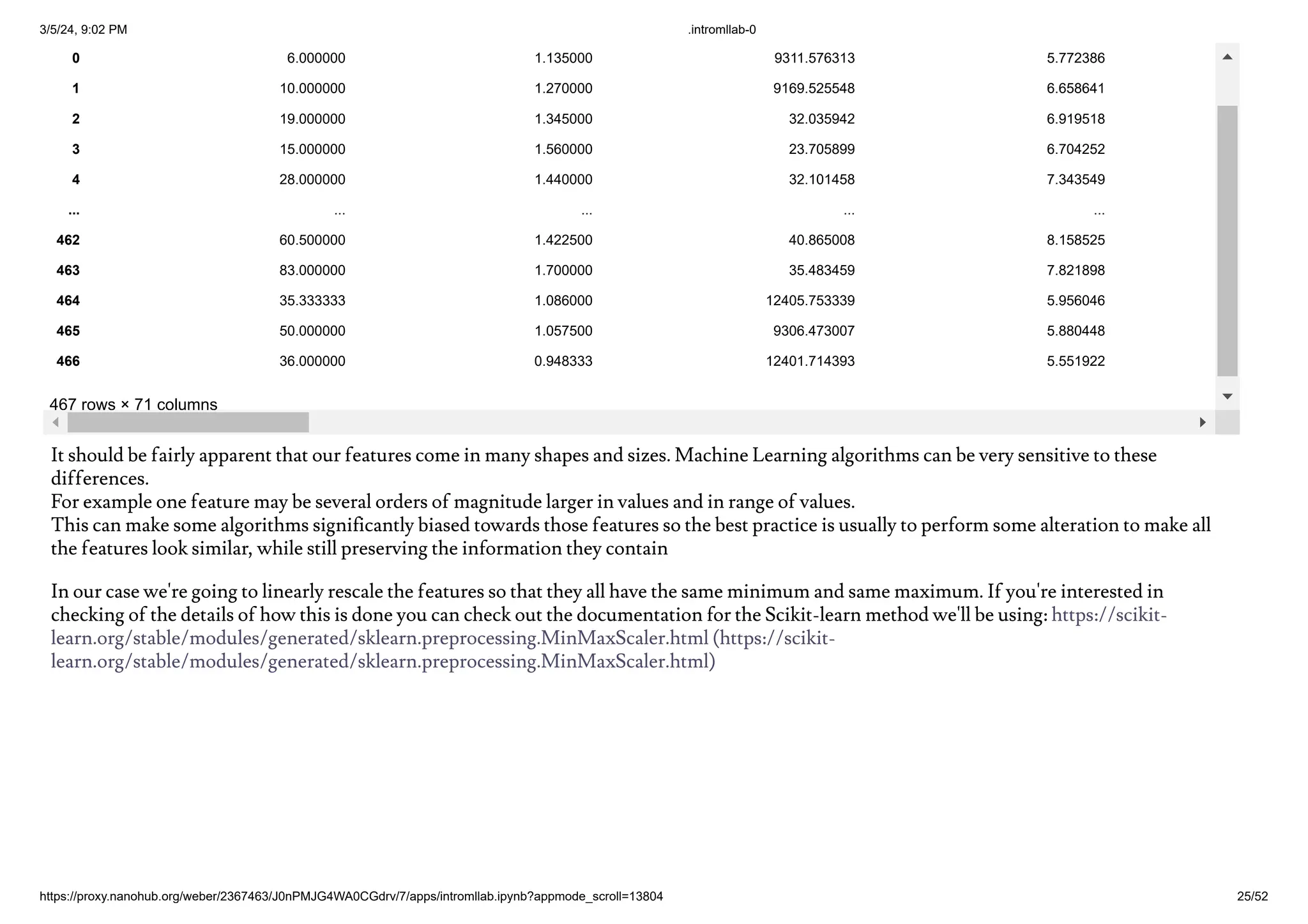
The document outlines a lab activity for students, focusing on applying a machine learning workflow to a materials science dataset. It aims to deepen understanding of machine learning concepts while providing hands-on experience with Jupyter Notebooks and standard Python packages. The activity involves elements like data cleaning, feature generation, model evaluation, and aims to predict materials for solar cells and wide band gap semiconductors.




![3/5/24, 9:02 PM .intromllab-0
https://proxy.nanohub.org/weber/2367463/J0nPMJG4WA0CGdrv/7/apps/intromllab.ipynb?appmode_scroll=13804 5/52
SECTION 6: HYPERPARAMETER OPTIMIZATION
ESTABLISHING A CROSS-VALIDATION SCHEME
DEFINING A PARAMETER SPACE
SETTING UP A GRID SEARCH
Exercise 6.1
VISUALIZING BIAS-VARIANCE TRADEOFF
Exercise 6.2
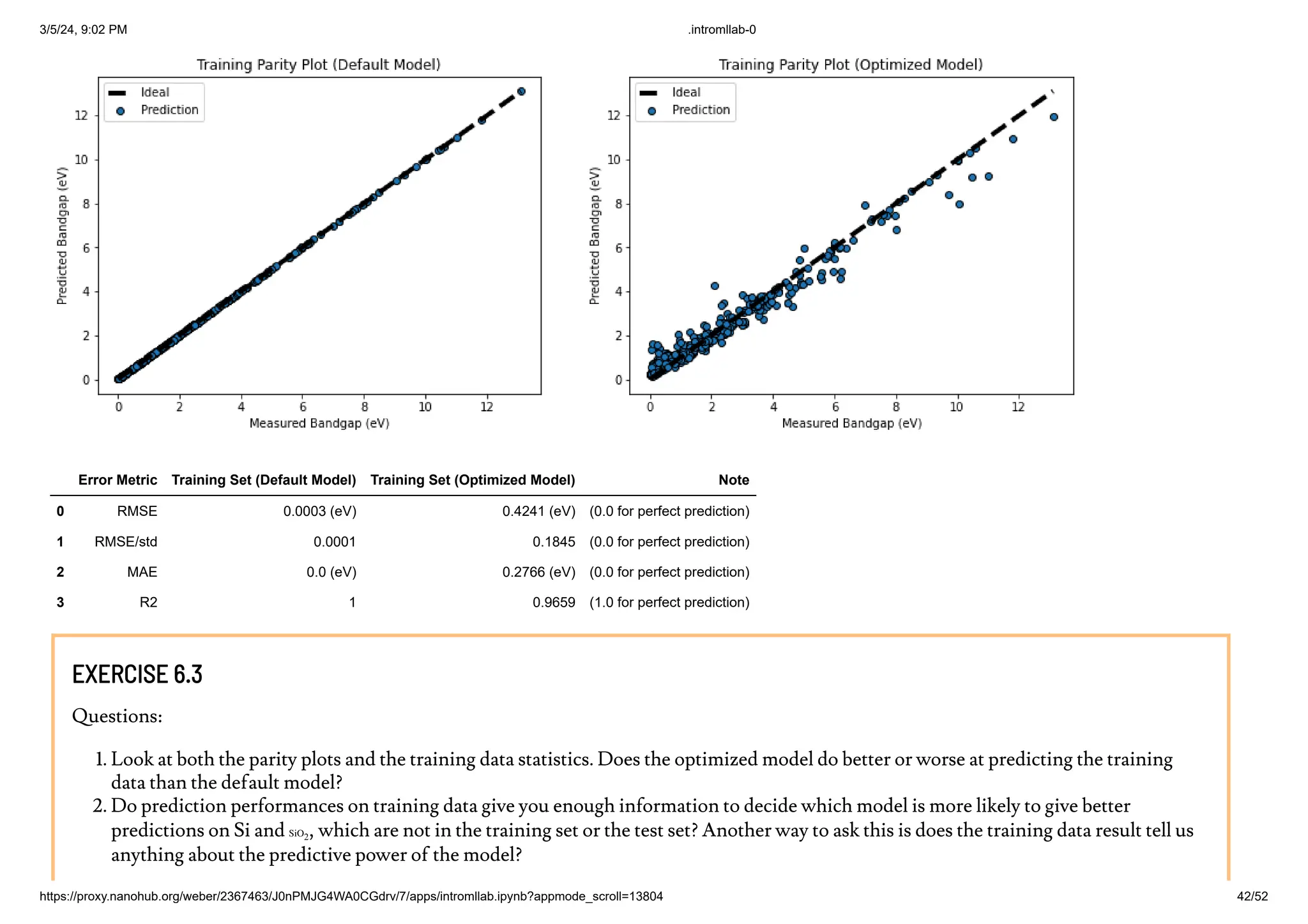
DEFAULT VS. OPTIMIZED MODEL: TRAINING AND VALIDATION DATA PERFORMANCE
Exercise 6.3
DEFAULT VS. OPTIMIZED MODEL: TEST DATA PERFORMANCE
Exercise 6.4
Exercise 6 5
[-----------------------------------BEGIN LESSON----------------
-------------------]
LESSON FORMAT
This is a Jupyter Notebook. It allows you to interact with this page by writing and running code. As you move through this notebook, you
will see unique sections. Within each section, there are learning goals for the section, an overview of the content covered in each section,
and then the content for the section itself. This content can take the form of written lessons, code examples, or coding exercises. The
instructions for the coding exercises are wrapped in an orange rectangle. These instructions will be followed by a code block that resembles
this:](https://image.slidesharecdn.com/intromllab-0-240306015537-bf02d211/75/INTRODUCTION-TO-MACHINE-LEARNING-FOR-MATERIALS-SCIENCE-5-2048.jpg)
![3/5/24, 9:02 PM .intromllab-0
https://proxy.nanohub.org/weber/2367463/J0nPMJG4WA0CGdrv/7/apps/intromllab.ipynb?appmode_scroll=13804 6/52
### FINISH THE CODE BELOW ###
[Your code goes here]
#---------------------------#
Throughout this notebook you'll also see green boxes with the title ProTip that look much like this one. These boxes contain inportant
helpful information
JUPYTER NOTEBOOK TIPS AND TRICKS
CELLS
Each individual part of this notebook is known as a cell. The orange highlight bar along the left edge of this page indicates which cell is
active.
MOVING BETWEEN ACTIVE CELLS
You can move between cells by hitting the up and down arrows or by clicking on the cell you want to focus on. The up and down arrow
keys will only move you between cells when you are not in edit mode.
EDIT MODE
Hit the enter key on the active cell to "enter" it and edit its contents. While in edit mode, the up and down arrow keys will not move you
between cells. Double clicking a cell will also enable edit mode.
RUNNING A CELL
Hit shift + enter to run the active cell. In a code cell, the code will run and if there is output, it will be displayed immediately below the
code cell. In a markdown cell, the markdown will be rendered. Running a cell will automatically make the following cell the new active cell.
EXIT EDIT MODE](https://image.slidesharecdn.com/intromllab-0-240306015537-bf02d211/75/INTRODUCTION-TO-MACHINE-LEARNING-FOR-MATERIALS-SCIENCE-6-2048.jpg)





















![3/5/24, 9:02 PM .intromllab-0
https://proxy.nanohub.org/weber/2367463/J0nPMJG4WA0CGdrv/7/apps/intromllab.ipynb?appmode_scroll=13804 30/52
FITTING THE DECISION TREE MODEL
We'll train or "fit" a decision tree model using the RandomForestRegressor().fit() class from the scikit-learn package we imported
at the beginning of the notebook. Notice how this only takes 1 single line of code because we're leveraging existing code package that's been built
for us already. Also note that the actual class name that we're using is called RandomForestRegressor. This RandomForestRegressor class can be
configured to be identical to a decision tree, however the reason we'll use it is because later on it will give us more flexibility when we start
changing the model. A decision tree model is basically a random forest model with 1 tree, so we'll set the n_estimators hyperparameter to 1 to
make the model mimic a single decision tree.
Keep in mind that machine learning is much more than this 1 line of code: You have already gone through a ton of preprocessing and decision
making to reach this step!
The outputs above describes the hyperparameters selected (in this case, by default) to fit the decision tree model. and the parameters being
generated in the training process. You may also wonder what the decision tree looks like, and we will visualize the entire tree later.
We'll also go into more detail about what these (hyper)parameters are at a later time when they become more relevant. For now, we're glossing
over because simply knowing these (hyper)parameters doesn't help us evaluate model quality until we have seen its performance: How accurately
and precisely can our decision tree model predict bandgaps? We will jump into that.
As one last motivation as we start asssessing our model, lets predict two band gaps of materials you're probably familiar with, Silicon and Silica.
Silicon is used in practically every electronic device as a semiconductor, and Silica is basic window glass. You can look up the values of their band
gaps fro reference, but look how just in a few lines of code the model can already give us a rough idea of their values. We know Silicon is a semi-
conductor and it's bandgap should be fairly low, while the band gap for Silica has to be much higher because window glass shouldn't absorb any
light at all. Based on these predictions it seems like the model can already pick up on these trends! But as we've been mentioning, just making a
few select predictions is not a good way to measure overall performance, in the next sections we'll dig into more robus ways to measure the
performance!
EVALUATING MODEL PERFORMANCE ON TRAINING AND TEST DATA
To evaluate the model performance, we will use it to predict bandgaps of materials it was trained on (training set) as well as materials it has not
seen before (test set), and we will compare its performance on both datasets.
Model training complete.
Predicting Silicon Band Gap: [2.]
Predicting Silica Band Gap: [7.]](https://image.slidesharecdn.com/intromllab-0-240306015537-bf02d211/75/INTRODUCTION-TO-MACHINE-LEARNING-FOR-MATERIALS-SCIENCE-30-2048.jpg)








![3/5/24, 9:02 PM .intromllab-0
https://proxy.nanohub.org/weber/2367463/J0nPMJG4WA0CGdrv/7/apps/intromllab.ipynb?appmode_scroll=13804 39/52
VISUALIZING THE LEARNING CURVE
How do we find out the best value for the hyperparameter n_estimators from the grid search?
Let's check how the performance changed as a function of n_estimators by plotting the average Mean Squared Error (MSE) for both the
training and validation splits for each hyperparameter choice (specified in opt_dict ).
EXERCISE 6.1
Before diving into the questions lets run a few different grid searches to get a feel for how it works. By default the notebook is setup with a
very rough grid search which should run quickly. be careful adding too many grid points because it is possible to slow down the grid search
to the point of not finishing in hours or days. As a rule of thumb lets not set number of trees to be above 100, and lets not include more than
10 individual grid points in any one search. Try to get a sense of how performance varies with number of trees. Before answering questions
below set your grid to be [1,3,5,7,10,15,20,50] which should give a reasonable spread of values. As a reminder these edits are made in the
section above "defining a parameter space"
Questions:
Minimum Mean Squared Error: 1.281
Number of Trees at minimum: 50](https://image.slidesharecdn.com/intromllab-0-240306015537-bf02d211/75/INTRODUCTION-TO-MACHINE-LEARNING-FOR-MATERIALS-SCIENCE-39-2048.jpg)




![3/5/24, 9:02 PM .intromllab-0
https://proxy.nanohub.org/weber/2367463/J0nPMJG4WA0CGdrv/7/apps/intromllab.ipynb?appmode_scroll=13804 45/52
LEARNING OUTCOMES
1. Judge model performance for two different applications
2. Assess previous error predictions
3 P i i i d l
Remember back when we first trained the model and predicted Silicon and Silica? Let do the same thing for fun with the optimized model. The
values have likely shifted.
When we fit the DT3 model we use the X_predict and y_predict versions of the dataset in which we removed 5 compounds so that we could
predict them now. Note that these predictions are a bit artificial because when we did the model optimization this data was included. In a true
research environment this isn't something you'd want to do.
Edit the cell below to change which compound is predicted between: Silicon, Silica, Salt, Diamond, and Tin
Change the Prediction_features object to one of the following:
xpredict_Si
xpredict_SiO2
xpredict_NaCl
xpredict_C
xpredict_Sn
Now for our final test on model performance. We are going to take the individual predictions on our Test data set and quantify how often the
model succeeded or failed in making predictions for both the Solar application and Wide Band Gap application. Below we've rearranged the
existing data from the parity plots in the previous section and printed it explicitly so we can look in more detail.
In doing this we are viewing the results of this regression model through the lens of classificaiton. Essentially the materials with known values in
a certain range will be viewed as one class of materials, and everything else as another class. We'll then assess how well the model does at correctly
identifying these classes of materials. If you want you read up on the background related to a few of these metrics you can look into the metrics
precision and recall for binary classifiers. During the exercises below we'll walk through the process of calculating the recall for this pseudo-
classification model.
Predicted Band Gap: [1.4931]](https://image.slidesharecdn.com/intromllab-0-240306015537-bf02d211/75/INTRODUCTION-TO-MACHINE-LEARNING-FOR-MATERIALS-SCIENCE-45-2048.jpg)






















































