- The document describes building predictive models using decision tree and regression modeling to predict which customers are likely to purchase new organic products being introduced by a supermarket.
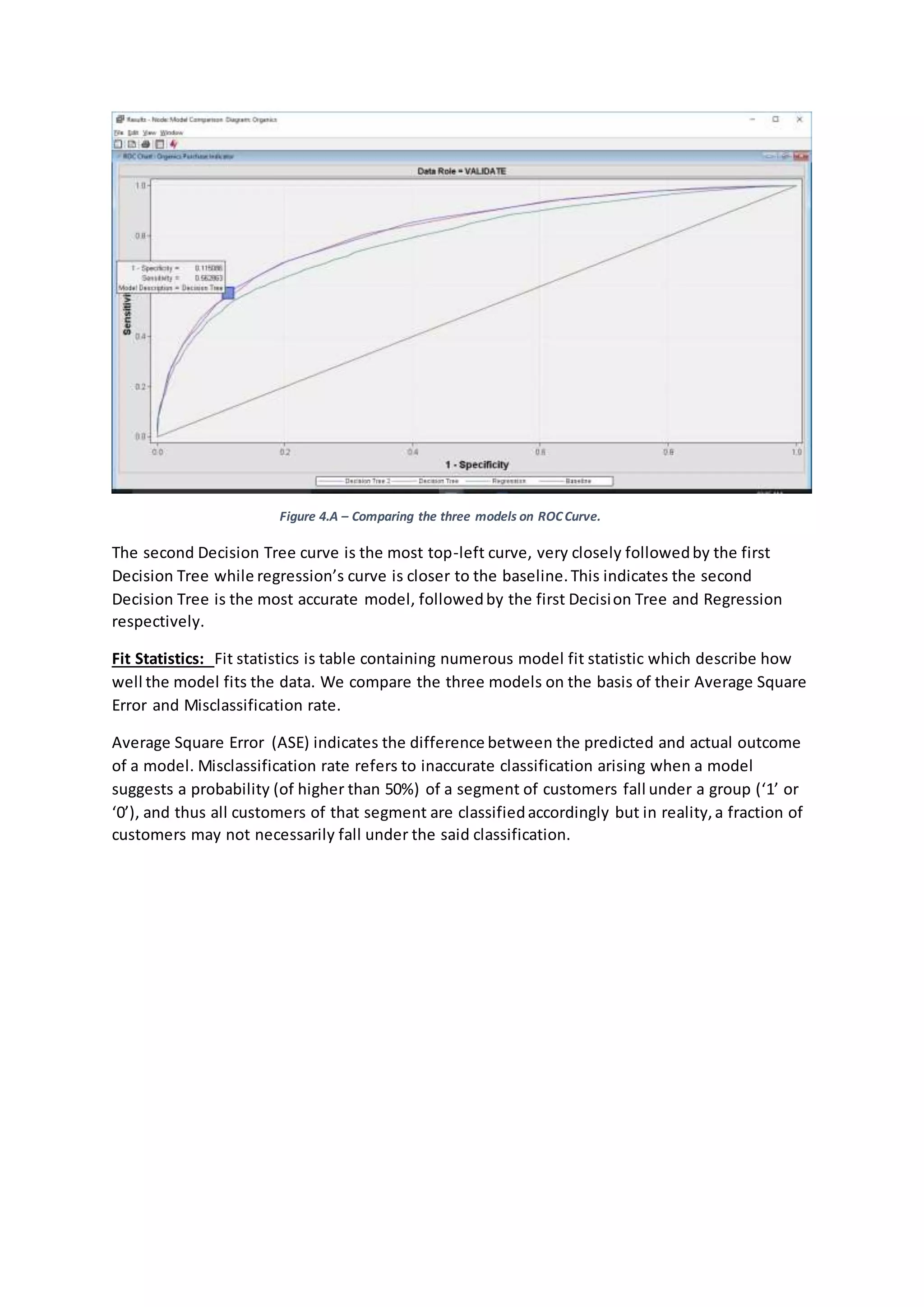
- Both decision tree and logistic regression models were created, with the decision tree models performing slightly better based on various evaluation metrics such as cumulative lift, ROC curve, and average square error.
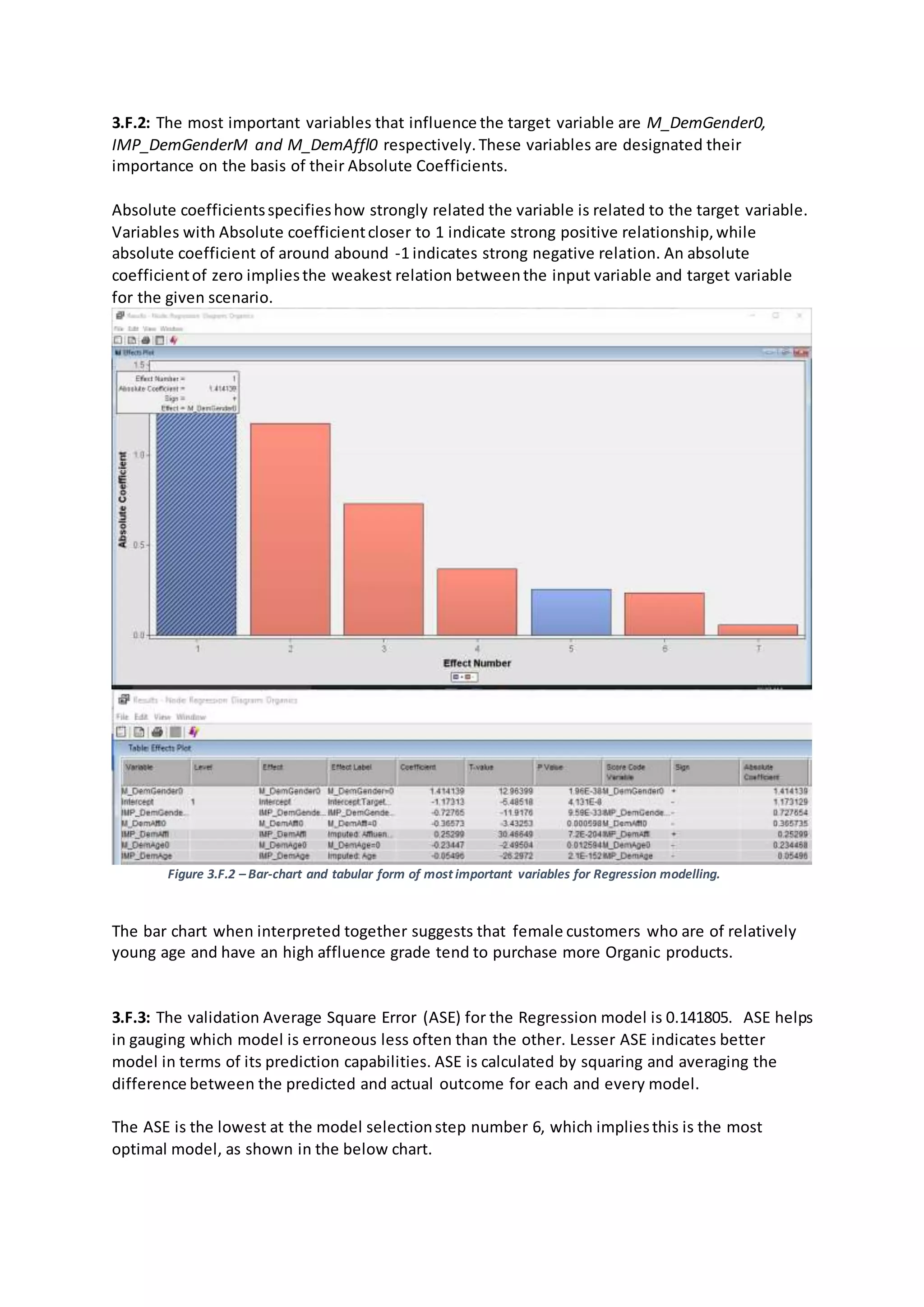
- The top variables influencing the likelihood of a customer purchasing organics according to the models were gender, age, and affluence level.

![1.A.3: Distribution of Target variables [Appendix – Figure 1.A.3 (2)]
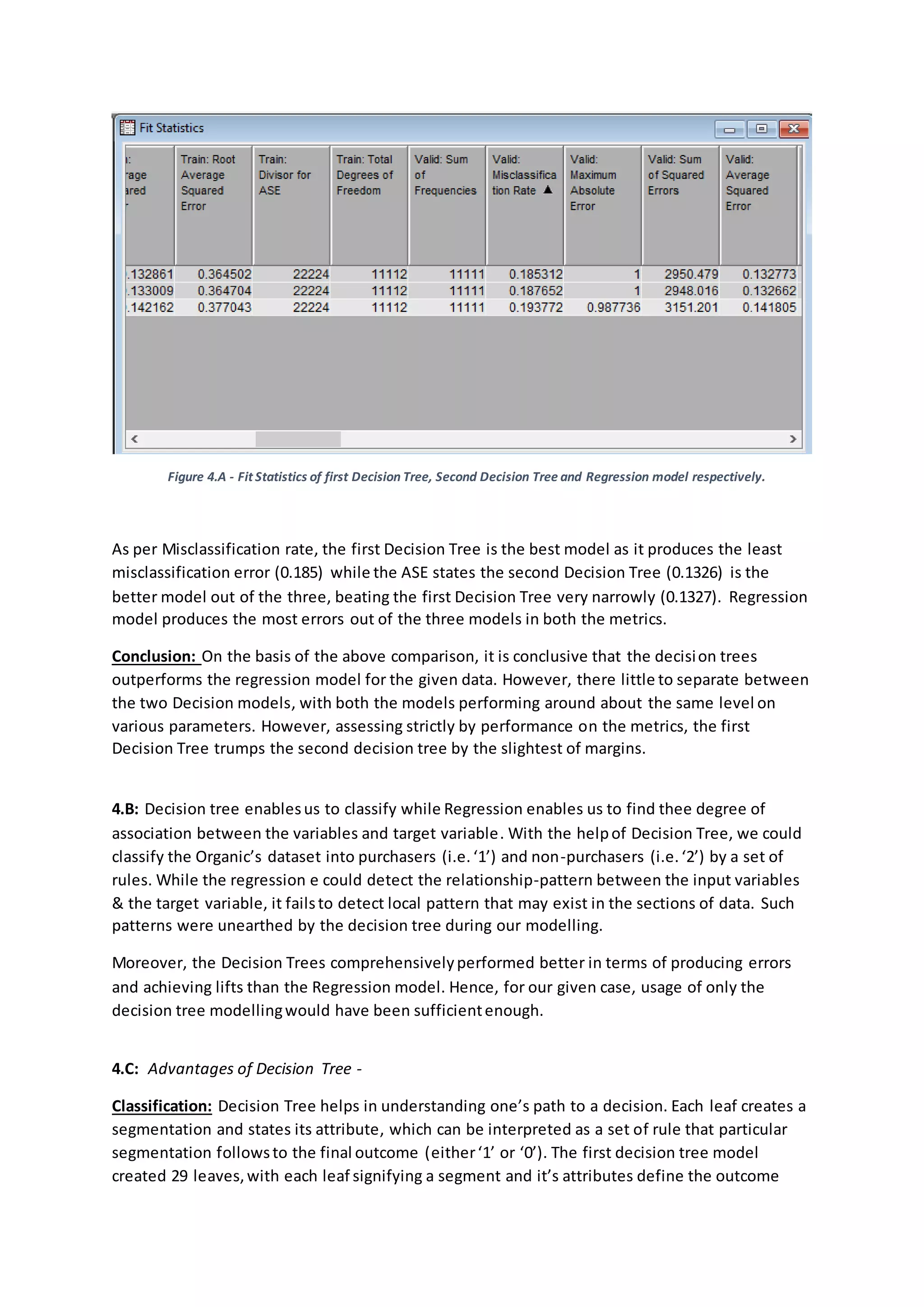
Figure 1.A.3 - Summary of Distribution of TargetBuy
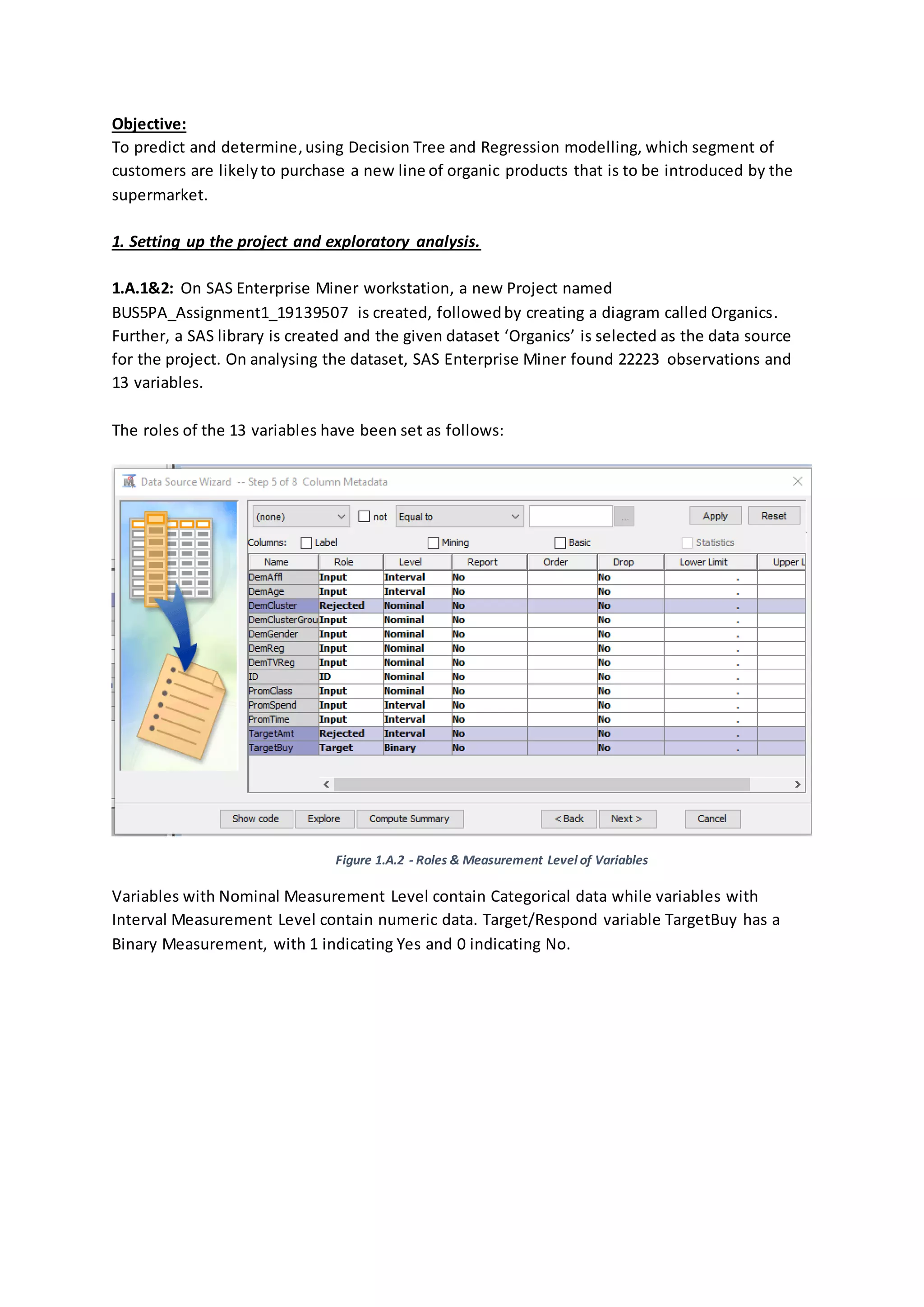
1.A.4: DemCluster has been Rejected as DemClusterGroup contains collapsed data of
DemCluster and based on past evidences,DemClusterGroup is sufficientfor the modelling.
1.B: TargetBuy envelopesthe data contained in TargetAmt. Utilizing TargetAmt as an input
could lead to an imprecise modelling or leakage as the model would find strong co-relation
between the input (TargetAmt) and Target (TargetBuy), since the target variable contains the
collapsed data of TargetAmt. Hence, TargetAmt should not be used as input and should be set
as Rejected.
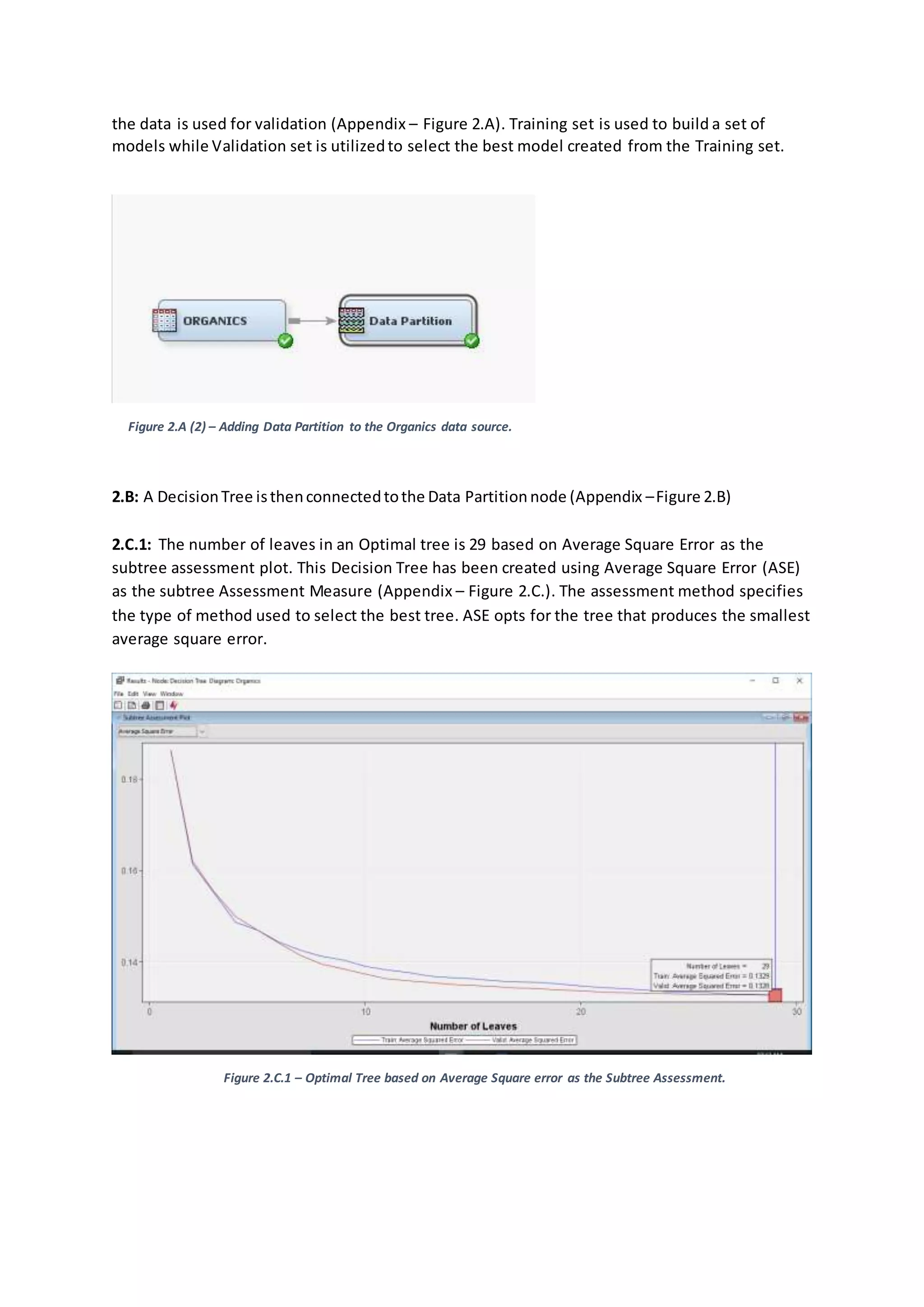
2. Decision tree based modelling and analysis.
2.A: After dragging the Organics dataset to the Organics diagram, we connect the Data Partition
node to the Organics dataset. 50% of the data is utilizedfor training while the remaining 50% of](https://image.slidesharecdn.com/19139507assignment1report-180311072511/75/Building-Evaluating-Predictive-model-Supermarket-Business-Case-3-2048.jpg)

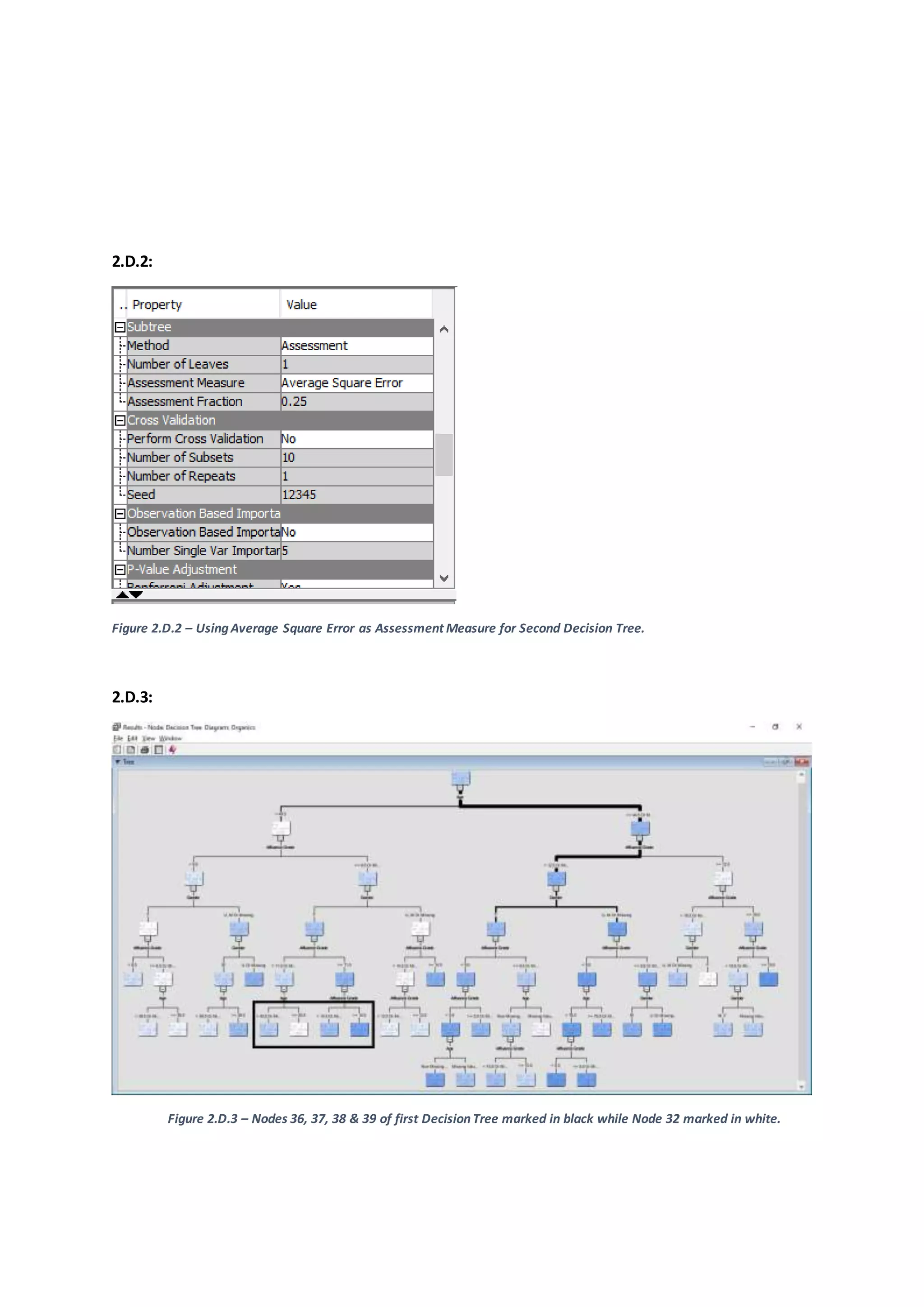
![Figure 2.D.3 – Leaves on Optimal Tree based on Average Square Error for Decision Tree 2.
The two Decision Tree models differas the maximum branch splits (2 vs 3) is different.This
results in the divergence in number of leavesin optimal tree of the respective Decision Tree the
first decision tree contains 29 leaves whereas Decision Tree 2 contains 33 leaves.
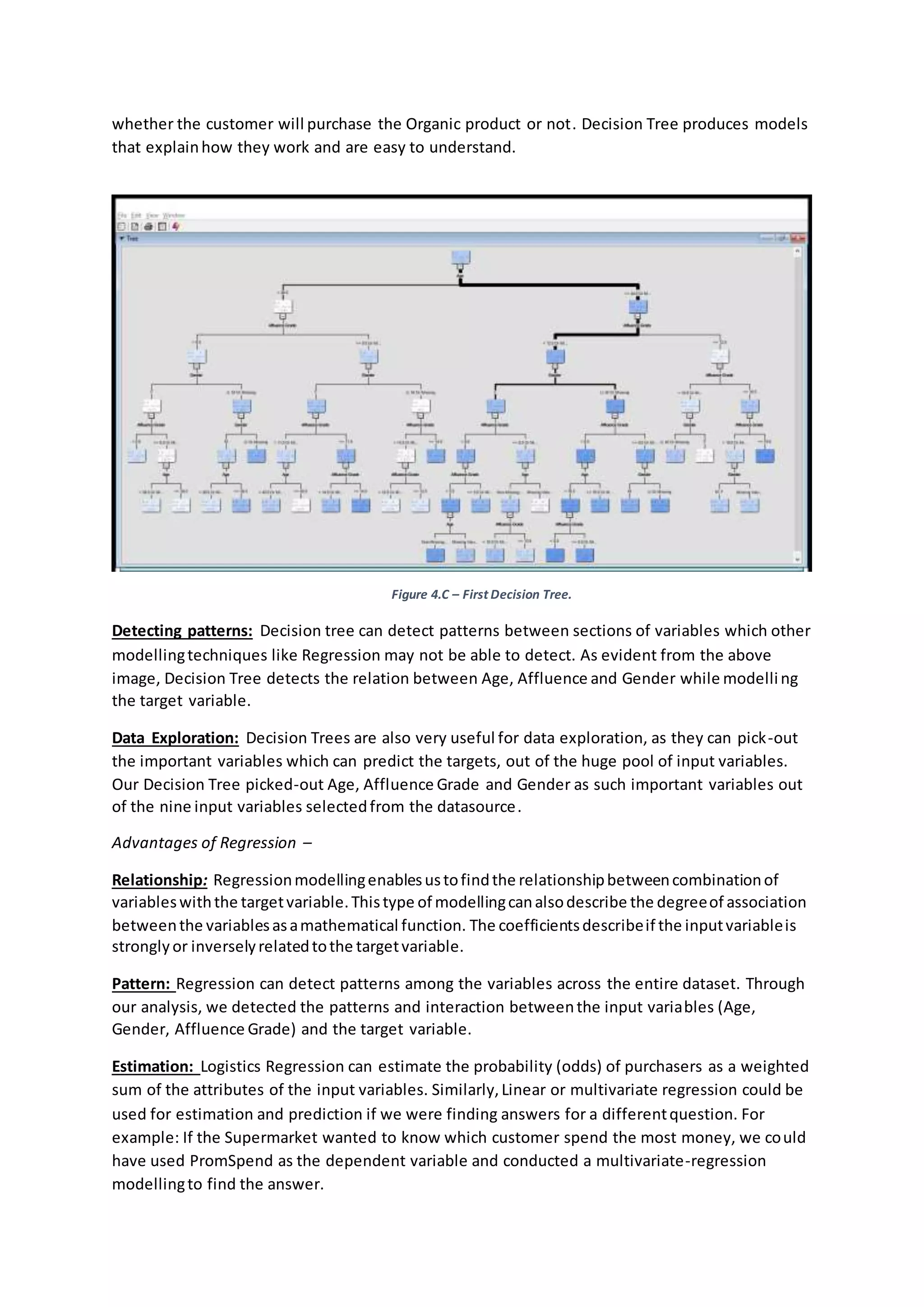
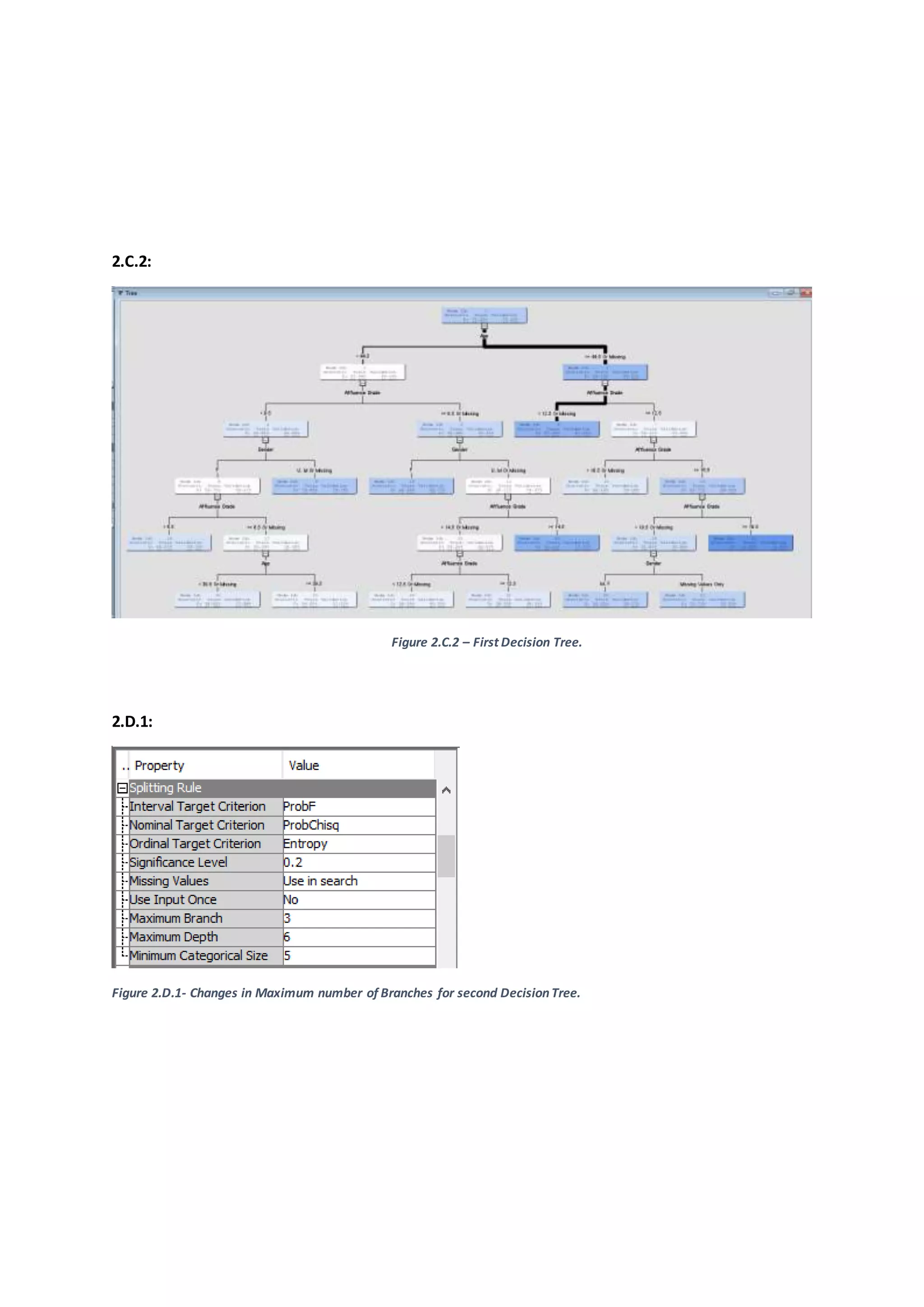
The set of rulesor classificationsetbythe firstDecisionTree canbe summarizedas –
Female customersunderthe Age of 44.5 years,havingAffluence grade more than9.5 or
missingare likelytopurchase organicproducts(Node 36,37, 38 & 39, Appendix –Figure
2.D.3).
Female customersunderthe age of 39.5 years,havingAffluence grade of lessthan9.5 but
more than 6.5 or missingare likelytopurchase organicproducts(Node 32, Appendix–
Figure 2.D.3).
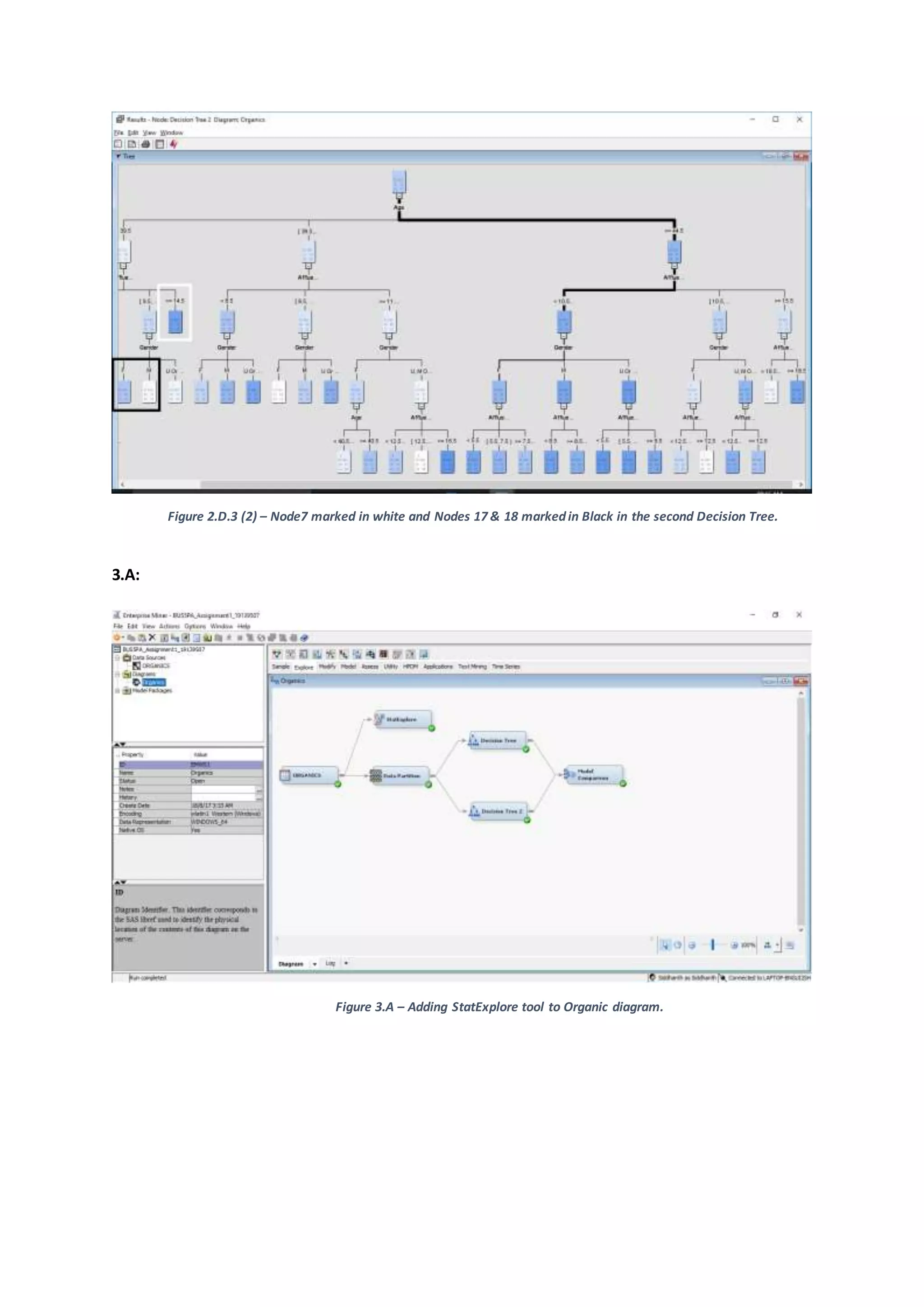
The set of rules or classificationsetbythe secondDecisionTree canbe summarizedas –
Customersunderthe age of 39.5 yearswhohave an affluence grade of more than14.5 are
verylikelytopurchase organicproducts[Node 7,Appendix –Figure 2.D.3(2)].
Customersunderthe age of 39.5 yearshavingaffluencegrade of lessthan14.5 butmore
than 9.5 (ormissing) are likelytopurchase organicproducts.However,if suchacustomeris
a Female,thenshe is22% more likelytobuyOrganicproductsthan the customerwhois
male withthe same attributes[Node 17& 18, Appendix –Figure 2.D.3 (2)].
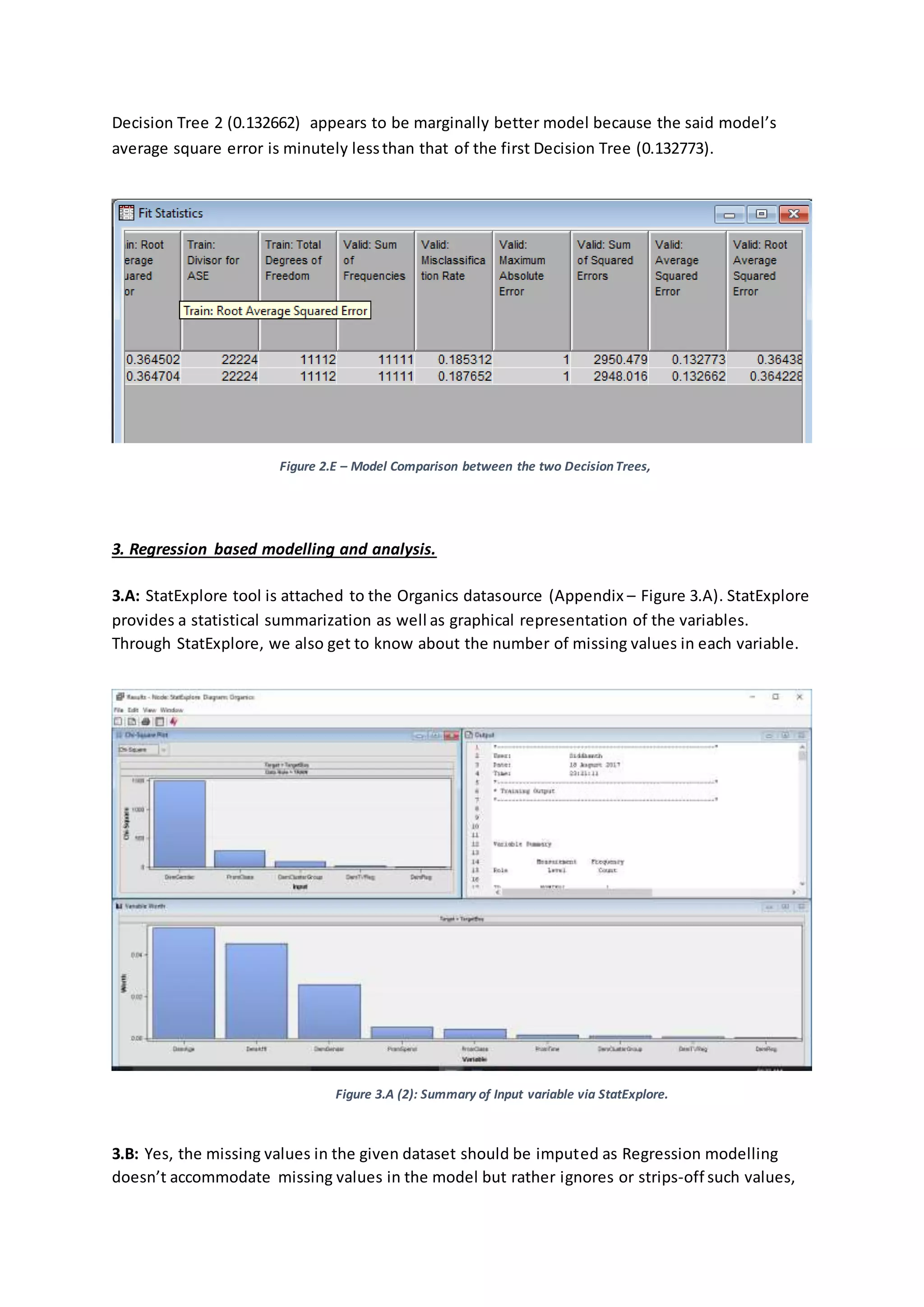
2.E: Average square error computes, squares and then averages the variation betweenthe
predicted outcome and the actual outcome of the leaf nodes. Lower the average square error,
better the model; as it indicates the model produces the fewer errors. For the Organics dataset,](https://image.slidesharecdn.com/19139507assignment1report-180311072511/75/Building-Evaluating-Predictive-model-Supermarket-Business-Case-6-2048.jpg)






















































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

