Download to read offline







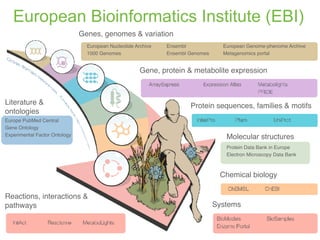







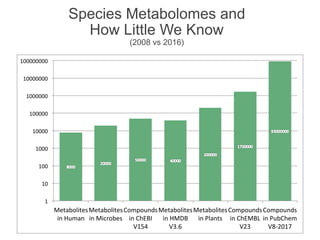
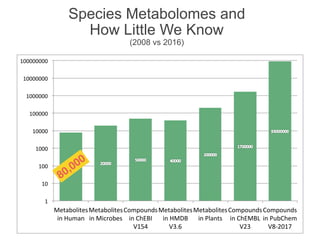
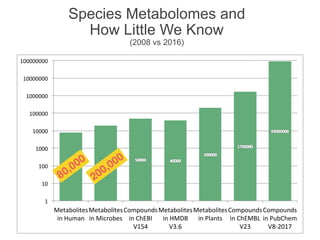
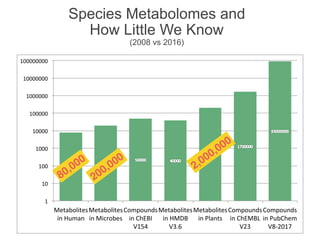
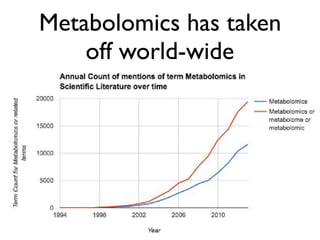

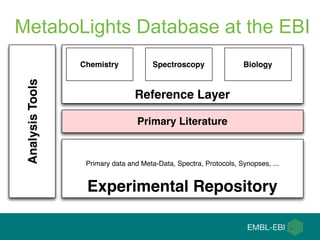
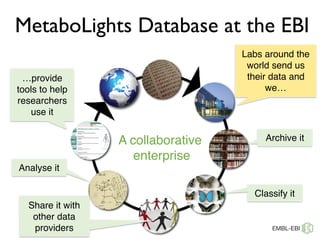
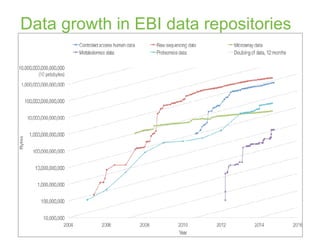
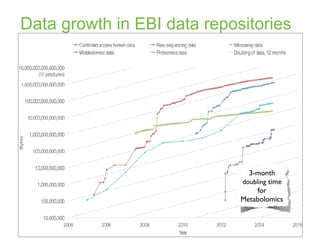
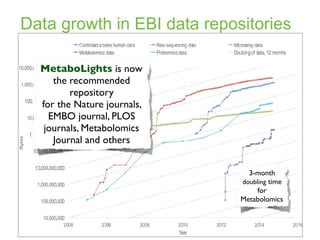
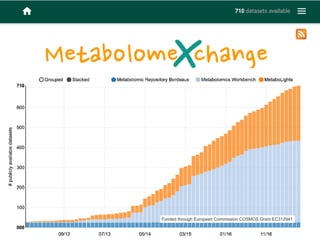
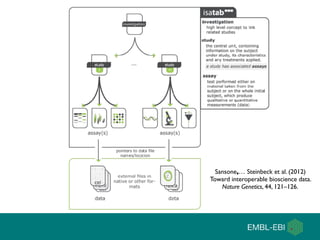
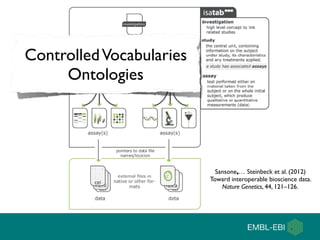
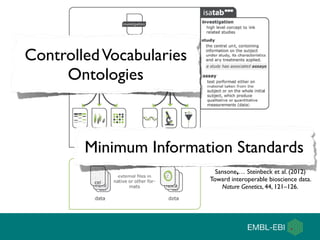
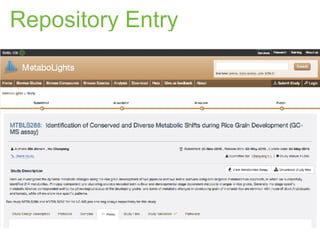
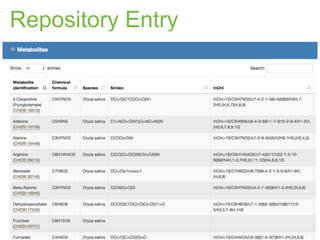
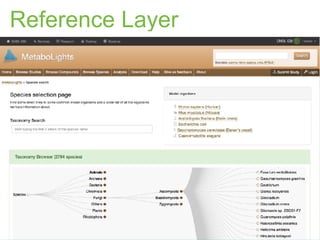
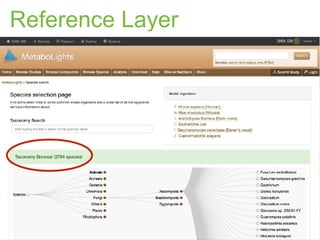
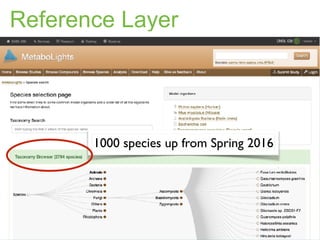
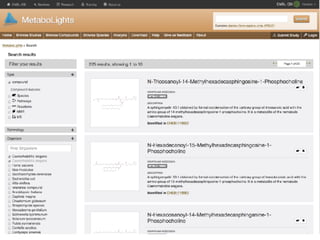
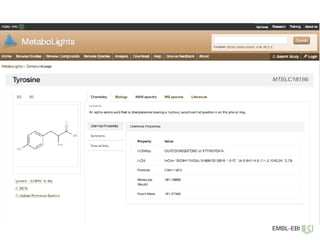
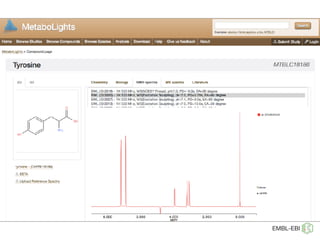
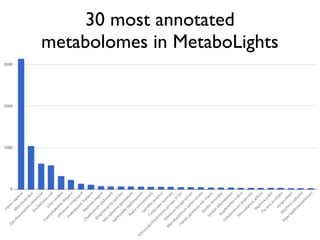
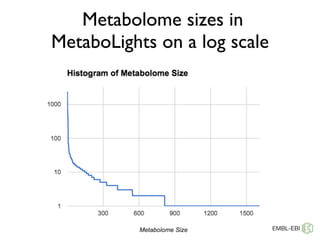
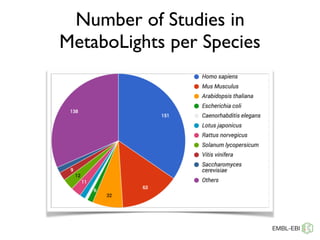




The document discusses the establishment and growth of a metabolome database at the European Bioinformatics Institute, which aims to archive and facilitate the sharing of metabolomic data from various laboratories worldwide. It highlights the significant increase in data over time and the importance of collaboration in the field of metabolomics. The document emphasizes the role of publishers and community support in promoting data sharing and establishing standards in bioinformatics.


























































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)
















