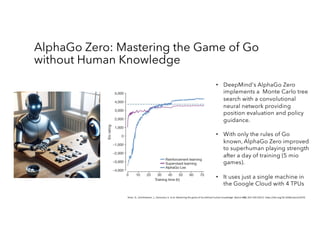
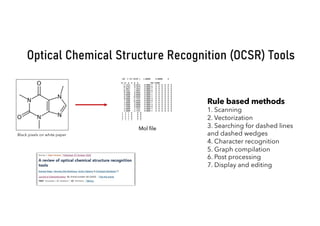
Download to read offline

















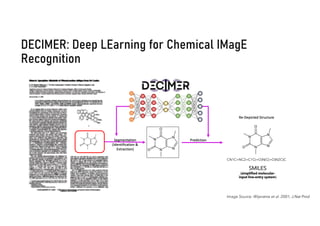

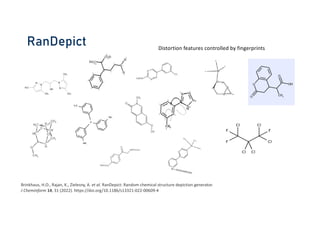
![DECIMER – Image to SMILES
CN1C=NC2=C1C(=O)N(C(=O)N2C)C
Show and tell: Image Caption Generator
DECIMER – Image to SMILES
Reference and Image source: Xu et al. 2015, arXiv[cs.LG]](https://image.slidesharecdn.com/ai-chem-nfdi4chem-09-2024-small-240911080955-81bcf634/85/AI-in-Chemistry-Deep-Learning-Models-Love-Really-Big-Data-21-320.jpg)
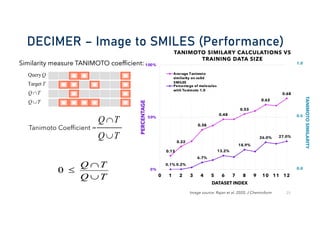




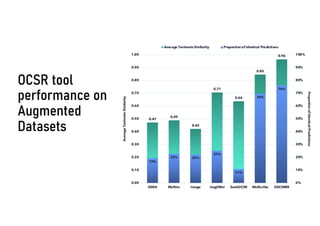
![OCSR tool performance on Augmented Datasets
Clean Data Augmented Data
• xy-shearing factor randomly drawn from [−0.1, 0.1]
• rotation (randomly drawn from [−5°, 5°])
Reference: Clevert et al. 2021, Chemical Science
Bayer AG, Berlin](https://image.slidesharecdn.com/ai-chem-nfdi4chem-09-2024-small-240911080955-81bcf634/85/AI-in-Chemistry-Deep-Learning-Models-Love-Really-Big-Data-34-320.jpg)



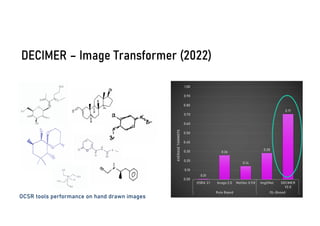
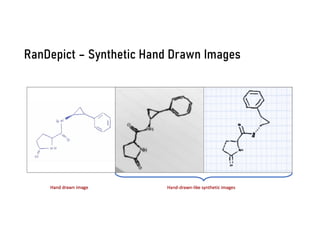
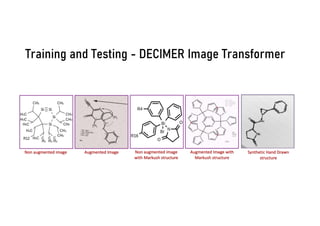
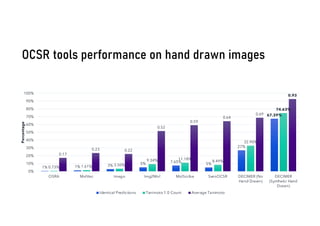
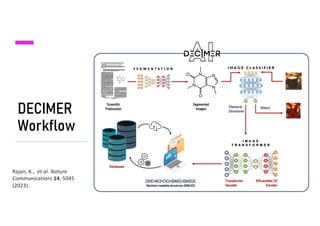







The document discusses advancements in deep learning applications in chemistry, emphasizing the importance of big data and innovative models such as GPT-3 and AlphaFold. It covers various deep learning methods including neural networks and their impact on chemical property prediction, reaction mechanisms, and the modeling of biological structures. The Decimer project is highlighted as a key tool for automating chemical image recognition and extraction of chemical data from scientific literature.

















































































